深度学习推荐系统中各类流行的Embedding方法(上)
本文首发于我的微信公众号里,地址:https://mp.weixin.qq.com/s/D57jP5EwIx4Y1n4mteGOjQ
我的个人微信公众号:Microstrong
微信公众号ID:MicrostrongAI
公众号介绍:Microstrong(小强)同学喜欢研究数据结构与算法、机器学习、深度学习等相关领域,公众号一直以来坚持原创,分享自己在计算机视觉、自然语言处理等方向的读书笔记。希望同大家一起学习交流进步!期待您的关注!
个人博客:https://blog.csdn.net/program_developer
Embedding方法概览:

1. Embedding简介
Embedding,中文直译为“嵌入”,常被翻译为“向量化”或者“向量映射”。在整个深度学习框架中都是十分重要的“基本操作”,不论是NLP(Natural Language Processing,自然语言处理)、搜索排序,还是推荐系统,或是CTR(Click-Through-Rate)模型,Embedding都扮演着重要的角色。
1.1 什么是Embedding
形式上讲,Embedding就是用一个低维稠密的向量“表示”一个对象,这里所说的对象可以是一个词(Word2vec),也可以是一个物品(Item2vec),亦或是网络关系中的节点(Graph Embedding)。其中“表示”这个词意味着Embedding向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性。
1.2 Embedding技术对于深度学习推荐系统的重要性
在深度学习推荐系统中,为什么说Embedding技术对于深度学习如此重要,甚至可以说是深度学习的“基本核心操作”呢?原因主要有以下四个:
(1)在深度学习网络中作为Embedding层,完成从高维稀疏特征向量到低维稠密特征向量的转换(比如Wide&Deep、DIN等模型)。推荐场景中大量使用One-hot编码对类别、id型特征进行编码,导致样本特征向量极度稀疏,而深度学习的结构特点使其不利于稀疏特征向量的处理,因此几乎所有的深度学习推荐模型都会由Embedding层负责将高维稀疏特征向量转换成稠密低维特征向量。因此,掌握各类Embedding技术是构建深度学习推荐模型的基础性操作。
(2)作为预训练的Embedding特征向量,与其他特征向量连接后,一同输入深度学习网络进行训练(比如FNN模型)。Embedding本身就是极其重要的特征向量。相比MF等传统方法产生的特征向量,Embedding的表达能力更强,特别是Graph Embedding技术被提出后,Embedding几乎可以引入任何信息进行编码,使其本身就包含大量有价值的信息。在此基础上,Embedding向量往往会与其他推荐系统特征连接后一同输入后续深度学习网络进行训练。
(3)通过计算用户和物品的Embedding相似度,Embedding可以直接作为推荐系统的召回层或者召回策略之一(比如Youtube推荐模型等)。Embedding对物品、用户相似度的计算是常用的推荐系统召回层技术。在局部敏感哈希(Locality-Sensitive Hashing)等快速最近邻搜索技术应用于推荐系统后,Embedding更适用于对海量备选物品进行快速“筛选”,过滤出几百到几千量级的物品交由深度学习网络进行“精排”。
(4)通过计算用户和物品的Embedding,将其作为实时特征输入到推荐或者搜索模型中(比如Airbnb的embedding应用)。
2. Word2Vec-Embedding流行起点
关于Word2Vec的入门文章请看我之前的一篇文章:深度浅出Word2Vec原理解析,Microstrong,地址:https://mp.weixin.qq.com/s/zDneR1BU6xvt8cndEF4_Xw
2.1 基于负采样的Skip-gram
这里我单独把基于负采样的Skip-gram模型再详细描述一次,是因为这个模型太重要了,稍后我们讲解的Item2Vec模型和Airbnb论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb 》提出的模型都借鉴了基于负采样的Skip-gram模型的思想。所以,我们务必要把基于负采样的Skip-gram模型理解透彻。
Skip-gram模型是由Mikolov等人提出的。下图展示了Skip-gram模型的过程。该模型可以看做是CBOW模型的逆过程。CBOW模型的目标单词在该模型中作为输入,上下文则作为输出。

我们使用 来表示输入层中唯一单词(也叫中心词)的输入向量,所以这样的话,对隐藏层
的定义意味着h仅仅只是简单拷贝了输入层到隐藏层的权重矩阵
中跟输入单词
相关的那一行。拷贝公式得到:
在输出层,我们输出 个多项式分布来替代仅输出一个多项式分布。每个输出是由同一个隐藏层到输出层矩阵计算得出的:
这里是第c个输出面上第j个单词;
是中心词对应的目标单词中的第c个单词;
是中心词(唯一输入单词);
是第c个输出面上第j个单元的输出值;
是第c个输出面上的第j个单元的输入。因为输出面共享同一权重矩阵,所以有:
是词汇表第j个单词的输出向量,可由
矩阵中的所对应的一列拷贝得到。
Skip-gram的损失函数可以写为:
由于语料库非常的大,直接计算中心词与词库中每个单词的softmax概率不现实。为了解决这个问题,Google提出了两个方法,一个是hierarchical softmax,另一个方法是negative sample。negative sample的思想本身源自于对Noise Contrastive Estimation的一个简化,具体的,把目标函数修正为:
是噪声分布 ( noise distribution )。即训练目标是使用Logistic regression区分出目标词和噪音词。另外,由于自然语言中很多高频词出现频率极高,但包含的信息量非常小(如'is' 'a' 'the')。为了balance低频词和高频词,利用简单的概率丢弃词
:
其中是
的词频,t的确定比较trick,启发式获得。实际中t大约在
附近。
Airbnb论文:
Grbovic M, Cheng H. Real-time personalization using embeddings for search ranking at airbnb[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 311-320.
2.2 关于Word2Vec几个问题思考
熟悉了Word2vec的基本原理后,我们来探究几个关于Word2vec的经典面试题。
(1) Hierarchical Softmax方法中哈夫曼树是如何初始化生成的?也就是哈夫曼树是如何构建的呢?
答:Hierarchical Softmax依据词频构建Huffman树,词频大的节点离根节点较近,词频低的节点离根节点较远,距离远参数数量就多。
(2)Hierarchical Softmax对词频低的和词频高的单词有什么影响?为什么?
答:词频高的节点离根节点较近,词频低的节点离根节点较远,距离远参数数量就多,在训练的过程中,低频词的路径上的参数能够得到更多的训练,所以Hierarchical Softmax对词频低的单词效果会更好。
(3)Hierarchical Softmax方法中其实是做了一个二分类任务,写出它的目标函数?
答: ,其中
是真实标签,
是模型预测的标签。
(4)Negative Sampling是一种什么采样方式?是均匀采样还是其它采样方法?
答:词典 中的词在语料
中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,反之,对于那些低频词,其被选中的概率就应该比较小。这就是我们对采样过程的一个大致要求,本质上就是一个带权采样问题。
(5)详细介绍一下Word2vec中负采样方法?
答:先将概率以累积概率分布的形式分布到一条线段上,以 为例,
所处线段为
,
所处线段为
,
所处线段为
,然后定义一个大小为
的数组,并把数组等距离划分为
个单元,然后与上面的线段做一次映射,这样我们便知道了数组内的每个单元所对应的字符了,这种情况下算法的时间复杂度为
,空间复杂度为
,
越小精度越大。
最后,我们来聊一聊Word2vec对Embedding技术的奠基性意义。Word2vec是由谷歌于2013年正式提出的,其实它并不完全由谷歌原创,对词向量的研究可以追溯到2003年论文《a neural probabilistic language model》,甚至更早。但正是谷歌对Word2vec的成功应用,让词向量的技术得以在业界迅速推广,使Embedding这一研究话题成为热点。毫不夸张地说,Word2vec对深度学习时代Embedding方向的研究具有奠基性的意义。
从另一个角度看,在Word2vec的研究中提出的模型结构、目标函数、负采样方法及负采样中的目标函数,在后续的研究中被重复使用并被屡次优化。掌握Word2vec中的每一个细节成了研究Embedding的基础。从这个意义上讲,熟练掌握本节内容非常重要。
3. Item2Vec-Word2vec在推荐领域的推广
在Word2vec诞生之后,Embedding的思想迅速从自然语言处理领域扩散到几乎所有机器学习领域,推荐系统也不例外。既然Word2vec可以对词“序列”中的词进行Embedding,那么对于用户购买“序列”中的一个商品,用户观看“序列”中的一个电影,也应该存在相应的Embedding方法,这就是Item2vec方法的基本思想。
Item2Vec论文:
【1】Barkan O , Koenigstein N . Item2Vec: Neural Item Embedding for Collaborative Filtering[J]. 2016.
3.1 Item2Vec的基本原理
由于Word2Vec的流行,越来越多的Embedding方法可以被直接用于物品Embedding向量的生成,而用户Embedding向量则更多通过行为历史中的物品Embedding平均或者聚类得到。利用用户向量和物品向量的相似性,可以直接在推荐系统的召回层快速得到候选集合,或在排序层直接用于最终推荐列表的排序。正是基于这样的技术背景,微软于2016年提出了计算物品Embedding向量的方法Item2Vec。
微软将Skip-gram with negative sampling(SGNS)应用在用户与物品的交互数据中,因此将该方法命名为Item2Vec。相比Word2Vec利用“词序列”生成词Embedding。Item2Vec利用的“物品集合”是由特定用户的浏览、购买等行为产生的历史行为记录序列变成物品集合。通过从物品序列移动到集合,丢失了空间/时间信息,还无法对用户行为程度建模(喜欢和购买是不同程度的强行为)。好处是可以忽略用户和物品关系,即便获得的订单不包含用户信息,也可以生成物品集合。而论文的结论证明,在一些场景下序列信息的丢失是可忍受的。
Item2Vec中把用户浏览的商品集合等价于Word2Vec中的word的序列,即句子(忽略了商品序列空间/时间信息)。出现在同一个集合的商品被视为positive。对于用户历史行为物品集合,Item2Vec的优化目标函数为:
我们再来看一下,Skip-gram是如何定义目标函数的。给定一个训练序列,
,...,
,模型的目标函数是最大化平均的log概率:
通过观察上面两个式子会发现,Item2Vec和Word2Vec唯一的不同在于,Item2Vec丢弃了时间窗口的概念,认为序列中任意两个物品都相关,因此在Item2Vec的目标函数中可以看到,其是两两物品的对数概率的和,而不仅是时间窗口内物品的对数概率之和。
在优化目标定义好后,Item2Vec训练和优化过程同Word2Vec一样,利用负采样,最终得到每个商品的embedding representation。利用商品的向量表征计算商品之间两两的cosine相似度即为商品的相似度。
3.2 双塔模型-"广义"的Item2Vec
3.2.1 DSSM语义召回
DSSM模型是微软2013年发表的一个关于query/doc的相似度计算模型,后来发展成为一种所谓”双塔“的框架广泛应用于广告、推荐等领域的召回和排序问题中。依然我们自底向上来看一下如下的网络结构:
- 首先特征输入层将Query和Doc(one-hot编码)转化为embedding向量,原论文针对英文输入还提出了一种word hashing的特殊embedding方法用来降低字典规模。我们在针对中文embedding时使用word2vec类常规操作即可;
- 经过embedding之后的词向量,接下来是多层DNN网络映射得到针对Query和Doc的128维语义特征向量;
- 最后会使用Query和Doc向量进行余弦相似度计算得到相似度R,然后进行softmax归一化得到最终的指标后验概率P,训练目标针对点击的正样本拟合P为1,否则拟合P为0;

可以看到DSSM的核心思想就是将不同对象映射到统一的语义空间中,利用该空间中对象的距离计算相似度。这一思路被广泛应用到了广告、搜索以及推荐的召回和排序等各种工程实践中。
DSSM论文:
【1】Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// ACM International Conference on Conference on Information & Knowledge Management. ACM, 2013:2333-2338.
3.2.2 双塔系列模型总结
事实上,Embedding对物品进行向量化的方法远不止Item2Vec。广义上讲,任何能够生成物品向量的方法都可以被称为Item2Vec。典型的例子是曾在百度、Facebook等公司成功应用的双塔模型,如下图所示。
 图:百度的“双塔”模型(来源于参考文献11)
图:百度的“双塔”模型(来源于参考文献11)
百度的双塔模型分别用复杂网络对“用户特征”和“广告特征”进行了Embedding化,在最后的交叉层之前,用户特征和广告特征之间没有任何交互,这就形成了两个独立的“塔”,因此称为双塔模型。
在完成双塔模型的训练后,可以把最终的用户Embedding和广告Embedding存入内存数据库。而在线上inference时,也不用复现复杂网络,只需要实现最后一层的逻辑(即线上实现LR或浅层NN等轻量级模型拟合优化目标”的上线方式),在从内存数据库中取出用户embedding和广告embedding之后,通过简单计算即可得到最终的预估结果。
总之,在广告场景下的双塔模型中,广告侧的模型结构实现的其实就是对物品进行Embedding的过程。该模型被称为“双塔模型”,因此以下将广告侧的模型结构称为“物品塔”。那么,“物品塔”起到的作用本质上是接收物品相关的特征向量,经过“物品塔”内的多层神经网络结构,最终生成一个多维的稠密向量。从Embedding的角度看,这个稠密向量其实就是物品的Embedding向量,只不过Embedding模型从Word2Vec变成了更为复杂灵活的“物品塔”模型,输入特征由用户行为序列生成的One-hot特征向量,变成了可包含更多信息的、全面的物品特征向量。二者的最终目的都是把物品的原始特征转变为稠密的物品Embedding向量表达,因此不管其中的模型结构如何,都可以把这类模型称为“广义”上的Item2Vec类模型。
Word2Vec和其衍生出的Item2Vec类模型是Embedding技术的基础性方法,但二者都是建立在“序列”样本(比如句子、用户行为序列)的基础上的。在互联网场景下,数据对象之间更多呈现的是图结构,所以Item2Vec在处理大量的网络化数据时往往显得捉襟见肘,这就是Graph Embedding技术出现的动因。下一篇文章再给大家详细介绍Graph Embedding的相关内容,请大家持续关注我哈!
双塔模型推荐阅读论文:
【1】Yi X, Yang J, Hong L, et al. Sampling-bias-corrected neural modeling for large corpus item recommendations[C]//Proceedings of the 13th ACM Conference on Recommender Systems. 2019: 269-277.
深度学习推荐系统中各类流行的Embedding方法(下)- Microstrong的文章:
Microstrong:深度学习推荐系统中各类流行的Embedding方法(下)zhuanlan.zhihu.com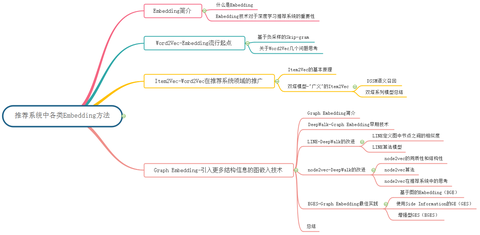
Reference
【1】《深度学习推荐系统》王喆编著。
【2】Graph Embedding:深度学习推荐系统的"基本操作" - 顾鹏的文章 - 知乎 https://zhuanlan.zhihu.com/p/68247149
【3】第四范式先荐 第5期 图推荐算法在E&E问题上的应用,地址:https://mp.weixin.qq.com/s/RTAHBIAPQMqCM8WF6trwug
【4】图推荐算法在E&E问题上的应用,地址:https://mp.weixin.qq.com/s/KSW47hbNLaHTw9Ib0wMO8g
【5】Embedding在推荐算法中的应用总结 - 梦想做个翟老师的文章 - 知乎 https://zhuanlan.zhihu.com/p/78144408
【6】Graph Embedding:深度学习推荐系统的"基本操作" - 顾鹏的文章 - 知乎 https://zhuanlan.zhihu.com/p/68247149
【7】word2vec详解(CBOW,skip-gram,负采样,分层Softmax) - 孙孙的文章 - 知乎 https://zhuanlan.zhihu.com/p/53425736
【8】推荐召回算法之深度召回模型串讲 - 深度传送门的文章 - 知乎 https://zhuanlan.zhihu.com/p/63343894
【9】现阶段各家公司的广告算法使用的主流模型有哪些? - 付鹏的回答 - 知乎 https://www.zhihu.com/question/352306163/answer/902698330
【10】深度学习技术在美图个性化推荐的应用实践,地址:https://mp.weixin.qq.com/s/b8DkQWZbUc5-jzWKBd8iUA
【11】如何解决推荐系统工程难题——深度学习推荐模型线上serving? - 王喆的文章 - 知乎 https://zhuanlan.zhihu.com/p/77664408
深度学习推荐系统中各类流行的Embedding方法(下)
本文首发于我的微信公众号里,地址:本文首发于我的微信公众号里,地址:https://mp.weixin.qq.com/s/N76XuNJ7yGzdP6NHk2Rs-w
我的个人微信公众号:Microstrong
微信公众号ID:MicrostrongAI
公众号介绍:Microstrong(小强)同学喜欢研究数据结构与算法、机器学习、深度学习等相关领域,公众号一直以来坚持原创,分享自己在计算机视觉、自然语言处理等方向的读书笔记。希望同大家一起学习交流进步!期待您的关注!
个人博客:https://blog.csdn.net/program_developer
Embedding技术概览:

对其它Embedding技术不熟悉,可以看我的上一篇文章:
深度学习推荐系统中各类流行的Embedding方法(上),地址:https://mp.weixin.qq.com/s/D57jP5EwIx4Y1n4mteGOjQ
1. Graph Embedding简介
Word2Vec和其衍生出的Item2Vec类模型是Embedding技术的基础性方法,二者都是建立在“序列”样本(比如句子、用户行为序列)的基础上的。在互联网场景下,数据对象之间更多呈现的是图结构,所以Item2Vec在处理大量的网络化数据时往往显得捉襟见肘,在这样的背景下,Graph Embedding成了新的研究方向,并逐渐在深度学习推荐系统领域流行起来。
Graph Embedding也是一种特征表示学习方式,借鉴了Word2Vec的思路。在Graph中随机游走生成顶点序列,构成训练集,然后采用Skip-gram算法,训练出低维稠密向量来表示顶点。之后再用学习出的向量解决下游问题,比如分类,或者连接预测问题等。可以看做是两阶段的学习任务,第一阶段先做无监督训练生成表示向量,第二阶段再做有监督学习,解决下游问题。
总之,Graph Embedding是一种对图结构中的节点进行Embedding编码的方法。最终生成的节点Embedding向量一般包含图的结构信息及附近节点的局部相似性信息。不同Graph Embedding方法的原理不尽相同,对于图信息的保留方式也有所区别,下面就介绍几种主流的Graph Embedding方法和它们之间的区别与联系。
2. DeepWalk-Graph Embedding早期技术
早期,影响力较大的Graph Embedding方法是于2014年提出的DeepWalk,它的主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入Word2Vec进行训练,得到物品的Embedding。因此,DeepWalk可以被看作连接序列Embedding和Graph Embedding的过渡方法。

论文《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》用上图所示的方法展现了DeepWalk的算法流程。DeepWalk算法的具体步骤如下:
(1)图(a)是原始的用户行为序列。
(2)图(b)基于这些用户行为序列构建了物品关系图。可以看出,物品A和B之间的边产生的原因是用户U1先后购买了物品A和物品B。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品关系图中的边之后,全局的物品关系图就建立起来了。
(3)图(c)采用随机游走的方式随机选择起始点,重新产生物品序列。
(4)将这些物品序列输入图(d)所示的Word2Vec模型中,生成最终的物品Embedding向量。
在上述DeepWalk的算法流程中,唯一需要形式化定义的是随机游走的跳转概率,也就是到达结点 后,下一步遍历
的邻接点
的概率。如果物品关系图是有向有权图,那么从节点
跳转到节点
的概率定义如下式所示。
其中 是物品关系图中所有边的集合,
是节点
所有的出边集合,
是节点
到节点
边的权重,即DeepWalk的跳转概率就是跳转边的权重占所有相关出边权重之和的比例。
如果物品关系图是无向无权图,那么跳转概率将是上式的一个特例,即权重 将为常数1,且
应是节点
所有“边”的集合,而不是所有“出边”的集合。
注意:在DeepWalk论文中,作者只提出DeepWalk用于无向无权图。DeepWalk用于有向有权图的内容是阿里巴巴论文《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》中提出的Base Graph Embedding(BGE)模型,其实该模型就是对DeepWalk模型的实践,本文后边部分会讲解该模型。
DeepWalk相关论文:
【1】Perozzi B, Alrfou R, Skiena S, et al. DeepWalk: online learning of social representations[C]. knowledge discovery and data mining, 2014: 701-710.
【2】Wang J, Huang P, Zhao H, et al. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba[C]. knowledge discovery and data mining, 2018: 839-848.
3. LINE-DeepWalk的改进
DeepWalk使用DFS(Deep First Search,深度优先搜索)随机游走在图中进行节点采样,使用Word2Vec在采样的序列上学习图中节点的向量表示。LINE(Large-scale Information Network Embedding)也是一种基于邻域相似假设的方法,只不过与DeepWalk使用DFS构造邻域不同的是,LINE可以看作是一种使用BFS(Breath First Search,广度优先搜索)构造邻域的算法。
在Graph Embedding各个方法中,一个主要区别是对图中顶点之间的相似度的定义不同,所以先看一下LINE对于相似度的定义。
3.1 LINE定义图中节点之间的相似度
现实世界的网络中,相连接的节点之间存在一定的联系,通常表现为比较相似或者在向量空间中距离接近。对于带权网络来说,节点之间的权越大,相似度会越高或者距离越接近,这种关系称为一阶近邻。一阶近邻关系用于描述图中相邻顶点之间的局部相似度,形式化描述为若顶点、
之间存在直连边,则边权
即为两个顶点的相似度,若不存在直连边,则一阶相似度为0。 如下图所示,6和7之间存在直连边,且边权较大(表现为图中顶点之间连线较粗),则认为两者相似且一阶相似度较高,而5和6之间不存在直连边,则两者间一阶相似度为0。
但是,网络中的边往往比较稀疏,仅仅依靠一阶近邻关系,难以描述整个网络的结构。论文中定义了另外一种关系叫做二阶近邻。例如下图中的网络,节点5和节点{1,2,3,4}相连,节点6也和节点{1,2,3,4}相连,虽然节点5和6之间没有直接联系,但是节点5和6之间很可能存在某种相似性。举个例子,在社交网络中,如果两个人的朋友圈重叠度很高,或许两个人之间具有相同的兴趣并有可能成为朋友;在NLP中,如果不同的词经常出现在同一个语境中,那么两个词很可能意思相近。
LINE通过捕捉网络中的一阶近邻关系和二阶近邻关系,更加完整地描述网络。并且LINE适用于有向图、无向图、有权图、无权图。

3.2 LINE算法模型
(1)一阶近邻关系模型
一阶近邻关系模型中定义了两个概率,一个是联合概率,如下公式所示:
其中, 是图中节点
的向量表示,上式表示节点
和
之间的相似程度,这是一个sigmoid函数。
另外一个是经验概率,如下公式所示:
其中, 是节点
和
之间的权重。优化目标为最小化下式:
其中,是两个分布的距离,目标是期望两个概率分布接近,利用KL散度来计算相似性,丢掉常数项之后,得到下面公式:
一阶近邻关系模型的优化目标就是最小化 。可以看到,上面这些公式无法表达方向概念,因此一阶近邻关系模型只能描述无向图。
(2)二阶近邻关系模型
二阶近邻关系描述的是节点与邻域的关系,每个节点有两个向量,一个是该顶点本身的表示向量,一个是该顶点作为其他顶点的邻居时的表示向量,因此论文中对每个节点定义了两个向量, 表示节点i本身,
是节点j作为邻居的向量表示。针对每一个从节点i到j的有向边 (i,j),定义一个条件概率,如下式:
其中,|V|是图中所有的节点数量,这其实是一个softmax函数。同样,还有一个经验概率,如下式:
其中, 是边
的边权,
是从顶点
出发指向邻居节点的所有边权之和,N(i)是从节点i出发指向邻居的所有边集合。同样需要最小化条件概率和经验概率之间的距离,优化目标为:
其中,为控制节点重要性的因子,可以通过顶点的度数或者PageRank等方法估计得到。假设度比较高的节点权重较高,令
,采用KL散度来计算距离,略去常数项后,得到公式:
直接优化上式计算复杂度很高,每次迭代需要对所有的节点向量做优化,论文中使用Word2Vec中的负采样方法,得到二阶近邻的优化目标,如下公式所示。从计算的过程可以看到,二阶相似度模型可以描述有向图。
对比一阶近邻模型和二阶近邻模型的优化目标,差别就在于,二阶近邻模型对每个节点多引入了一个向量表示。实际使用的时候,对一阶近邻模型和二阶近邻模型分别训练,然后将两个向量拼接起来作为节点的向量表示。
此外有一点需要说明,在Graph Embedding方法中,例如DeepWalk、Node2Vec、EGES,都是采用随机游走的方式来生成序列再做训练,而LINE直接用边来构造样本,这也是他们的一点区别。
LINE论文:
【1】Tang J, Qu M, Wang M, et al. Line: Large-scale information network embedding[C]//Proceedings of the 24th international conference on world wide web. 2015: 1067-1077.
4. node2vec - DeepWalk的改进
2016年,斯坦福大学的研究人员在DeepWalk的基础上更进一步,提出了node2vec模型,它通过调整随机游走权重的方法使Graph Embedding的结果更倾向于体现网络的同质性(homophily)或结构性(structural equivalence)。
4.1 node2vec的同质性和结构性
具体的讲,网络的“同质性”指的是距离相近节点的Embedding应尽量近似,如下图所示,节点 与其相连的节点
的Embedding表达应该是接近的,这就是网络的“同质性”的体现。
“结构性”指的是结构上相似的节点Embedding应尽量近似,下图中节点 和节点
都是各自局域网络的中心节点,结构上相似,其Embedding的表达也应该近似,这是“结构性”的体现。

为了使Graph Embedding的结果能够表达网络的“结构性”,在随机游走过程中,需要让游走的过程更倾向于BFS,因为BFS会更多地在当前节点的邻域中游走遍历,相当于对当前节点周边的网络结构进行一次“微观扫描”。当前节点是“局部中心节点”,还是“边缘节点”,或是“连接性节点”,其生成的序列包含的节点数量和顺序必然是不同的,从而让最终的Embedding抓取到更多结构性信息。
另外,为了表达“同质性”,需要让随机游走的过程更倾向于DFS,因为DFS更有可能通过多次跳转,游走到远方的节点上,但无论怎样,DFS的游走更大概率会在一个大的集团内部进行,这就使得一个集团或者社区内部的节点的Embedding更为相似,从而更多地表达网络的“同质性”。
但是在不同的任务中需要关注的重点不同,可能有些任务需要关注网络的homophily,而有些任务比较关注网络的structural equivalence,可能还有些任务两者兼而有之。在DeepWalk中,使用DFS随机游走在图中进行节点采样,使用Word2Vec在采样的序列学习图中节点的向量表示,无法灵活地捕捉这两种关系。
实际上,对于这两种关系的偏好,可以通过不同的序列采样方式来实现。有两种极端的方式,一种是BFS,如上图中红色箭头所示,从u出发做随机游走,但是每次都只采样顶点u的直接邻域,这样生成的序列通过无监督训练之后,特征向量表现出来的是structural equivalence特性。另外一种是DFS,如上图中蓝色箭头所示,从u出发越走越远,学习得到的特征向量反应的是图中的homophily关系。
4.2 node2vec算法
那么在node2vec算法中,是怎么控制BFS和DFS的倾向性呢?主要是通过节点间的跳转概率。下图所示为node2vec算法从节点t跳转到节点v,再从节点v跳转到周围各点的跳转概率。假设从某顶点出发开始随机游走,第i-1步走到当前顶点v,要探索第i步的顶点x,如下图所示。下面的公式表示从顶点v到x的跳转概率,E是图中边的集合,(v, x)表示顶点v和x之间的边,表示从节点v跳转到下一个节点x的概率,Z是归一化常数。
带偏随机游走的最简单方法是基于下一个节点边权重 进行采样,即
,Z是权重之和。对于无权重的网络,
。最简单的方式,就是按照这个转移概率进行随机游走,但是无法控制BFS和DFS的倾向性。

node2vec用两个参数p和q定义了一个二阶随机游走,以控制随机游走的策略。假设当前随机游走经过边到达顶点
,现在要决定从节点v跳转到下一个节点x,需要依据边(v,x)上的跳转概率
。设
,
是顶点
和
之间的边权;
是修正系数,定义如下:
上式中表示下一步顶点x和顶点t之间的最短距离,只有3种情况,如果又回到顶点t,那么
;如果x和t直接相邻,那么
;其他情况
。参数p和q共同控制着随机游走的倾向性。参数p被称为返回参数(return parameter),控制着重新返回顶点t的概率。如果
,那么下一步较小概率重新返回顶点t;如果
,那么下一步会更倾向于回到顶点t,node2vec就更注重表达网络的结构性。参数q被称为进出参数(in-out parameter),如果q>1,那么下一步倾向于回到t或者t的临近顶点,这接近于BFS的探索方式;如果q<1,那么下一步倾向于走到离t更远的顶点,接近于DFS寻路方式,node2vec就更加注重表达网络的同质性。因此,可以通过设置p和q来控制游走网络的方式。所谓的二阶随机游走,意思是说下一步去哪,不仅跟当前顶点的转移概率有关,还跟上一步顶点相关。在论文中试验部分,作者对p和q的设置一般是2的指数,比如
。
node2vec这种灵活表达同质性和结构性的特点也得到了实验的证实,通过调整参数 和
产生了不同的Embedding结果。下图中的上半部分图片就是node2vec更注重同质性的体现,可以看到距离相近的节点颜色更为接近,下图中下半部分图片则更注重体现结构性,其中结构特点相近的节点的颜色更为接近。

4.3 node2vec在推荐系统中的思考
node2vec所体现的网络的同质性和结构性在推荐系统中可以被很直观的解释。同质性相同的物品很可能是同品类、同属性,或者经常被一同购买的商品,而结构性相同的物品则是各品类的爆款、各品类的最佳凑单商品等拥有类似趋势或者结构性属性的商品。毫无疑问,二者在推荐系统中都是非常重要的特征表达。由于node2vec的这种灵活性,以及发掘不同图特征的能力,甚至可以把不同node2vec生成的偏向“结构性”的Embedding结果和偏向“同质性”的Embedding结果共同输入后续的深度学习网络,以保留物品的不同图特征信息。
node2vec论文:
【1】Grover A, Leskovec J. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016: 855-864.
5. EGES - Graph Embedding最佳实践
2018 年,阿里巴巴公布了其在淘宝应用的Embedding方法 EGES(Enhanced Graph Embedding with Side Information)算法,其基本思想是Embedding过程中引入带权重的补充信息(Side Information),从而解决冷启动的问题。
淘宝平台推荐的三个问题:
- 可扩展性(scalability):已有的推荐算法(CF、Base-Content、DL)可以在小数据集上有不错效果,但是对于10亿用户和20亿商品这样海量的数据集上效果差。
- 稀疏性(sparsity):用户仅与小部分商品交互,难以训练准确的推荐模型。
- 冷启动(cold start):物品上新频繁,然而这些商品并没有用户行为,预测用户对这些商品的偏好是十分具有挑战性的。
现在业界针对海量数据的推荐问题通用框架是分成两个阶段,即matching 和 ranking。在matching阶段,我们会生成一个候选集,它的items会与用户接触过的每个item具有相似性;接着在ranking阶段,我们会训练一个深度神经网络模型,它会为每个用户根据他的偏好对候选items进行排序。论文关注的问题在推荐系统的matching阶段,也就是从商品池中召回候选商品的阶段,核心的任务是计算所有item之间的相似度。
为了达到这个目的,论文提出根据用户历史行为构建一个item graph,然后使用DeepWalk学习每个item的embedding,即Base Graph Embedding(BGE)。BGE优于CF,因为基于CF的方法只考虑了在用户行为历史上的items的共现率,但是对于少量或者没有交互行为的item,仍然难以得到准确的embedding。为了减轻该问题,论文提出使用side information来增强embedding过程,提出了Graph Embedding with Side information (GES)。例如,属于相似类别或品牌的item的embedding应该相近。在这种方式下,即使item只有少量交互或没有交互,也可以得到准确的item embedding。在淘宝场景下,side information包括:category、brand、price等。不同的side information对于最终表示的贡献应该不同,于是论文进一步提出一种加权机制用于学习Embedding with Side Information,称为Enhanced Graph Embedding with Side information (EGES)。
5.1 基于图的Embedding(BGE)

该方案是 DeepWalk 算法的实践,具体流程如下:
- 首先,我们拥有上亿用户的行为数据,不同的用户,在每个 Session 中,访问了一系列商品,例如用户 u2 两次访问淘宝,第一次查看了两个商品
B-E,第二次产看了三个商品D-E-F。 - 然后,通过用户的行为数据,我们可以建立一个商品图(Item Graph),可以看出,物品A,B之间的边产生的原因就是因为用户U1先后购买了物品A和物品B,所以产生了一条由A到B的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后,全局的物品相关图就建立起来了。
- 接着,通过 Random Walk 对图进行采样,重新获得商品序列。
- 最后,使用 Skip-gram 模型进行 Embedding 。
Base Graph Embedding 与 DeepWalk 不同的是:通过 user 的行为序列构建网络结构,并将网络定义为有向有权图。其中:根据行为的时间间隔,将一个 user 的行为序列分割为多个session。session分割可以参考Airbnb这篇论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》。
5.2 使用Side Information的GE(GES)
通过使用BGE,我们能够将items映射到高维向量空间,并考虑了CF没有考虑的用户序列关系。但是我们依然没有解决冷启动的问题。为了解决冷启动问题,我们使用边信息( category, shop, price, etc)赋值给不同的item。因为边信息相同的两个item,理论而言会更接近。通过DeepWalk方案得到item的游走序列,同时得到对应的边信息(category,brand,price)序列。然后将所有序列放到Word2Vec模型中进行训练。针对每个 item,将得到:item_embedding,category_embedding,brand_embedding,price_embedding 等 embedding 信息。为了与之前的item embedding区分开,在加入Side information之后,我们称得到的embedding为商品的aggregated embeddings。商品 的aggregated embeddings为:
对上式做一个简单的解释:针对每个 item,将得到:item_embedding,category_embedding,brand_embedding,price_embedding 等 embedding 信息。将这些 embedding 信息求均值来表示该 item的Embedding。
需要注意的一点是,item 和 side information(例如category, brand, price等) 的 Embedding 是通过 Word2Vec 算法一起训练得到的。如果分开训练,得到的item_embedding和category_embedding(brand_embedding,price_embedding)不在一个向量空间中,做运算无意义。即:通过 DeepWalk 方案得到 item 的游走序列,同时得到对应的(category,brand,price)序列。然后将所有序列数据放到Word2Vec模型中进行训练。
5.3 增强型GES(EGES)
GES中存在一个问题是,针对每个item,它把所有的side information embedding求和后做了平均,没有考虑不同的side information 之间的权重,EGES就是让不同类型的side information具有不同的权重,提出来一个加权平均的方法来聚集这些边界embedding。
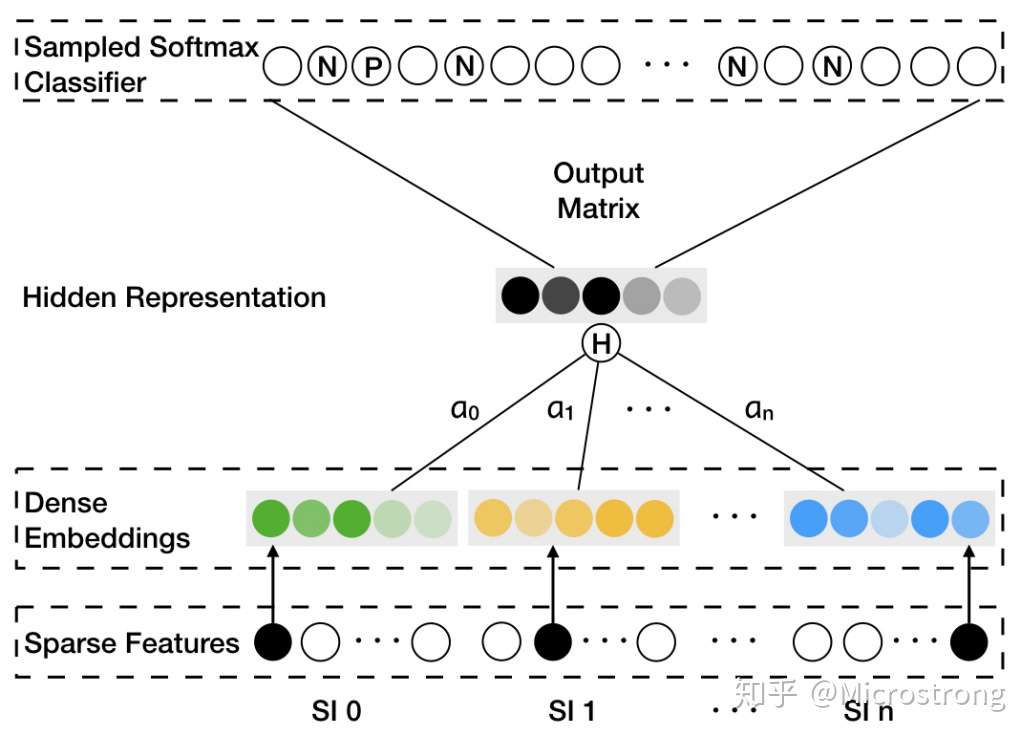
因为每个item对其不同边信息的权重不一样,所以就需要额外矩阵A来表示每个item边信息的权重,其大小为,v是item的个数,n是边信息的个数,加1是还要考虑item自身Embedding的权重。为了简单起见,我们用
表示第v个item、第j个类型的side information的权重。
表示第v个item自身Embedding的权重。这样就可以获得加权平均的方法:
这里对权重项 做了指数变换,目的是为了保证每个边信息的贡献都能大于0。权重矩阵A通过模型训练得到。
EGES算法应用改进的Word2Vec算法(Weighted Skip-Gram)确定模型的参数。对上图中EGES算法简单说明如下:
- 上图的Sparse Features代表 item 和 side information 的ID信息;
- Dense Embeddings 表示 item 和 side information 的 embedding 信息;
分别代表 item 和 side information 的 embedding 权重;
- Sampled Softmax Classifier中的N代表采样的负样本(见论文中的Algorithm 2 Weighted Skip-Gram描述的第8行),P代表正样本(某个item周边上下n个item均为正样本,在模型中表示时不区分远近);
EGES并没有过于复杂的理论创新,但给出了一个工程上的融合多种Embedding的方法,降低了某类信息缺失造成的冷启动问题,是实用性极强的Embedding方法。
EGES论文:
【1】Wang J, Huang P, Zhao H, et al. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba[C]. knowledge discovery and data mining, 2018: 839-848.
6. 总结
时至今日,Graph Embedding仍然是工业界和学术界研究和实践的热点,除了本文介绍的DeepWalk、LINE、node2vec、EGES等主流方法,SDNE、struct2vec等方法也是重要的Graph Embedding模型,感兴趣的读者可以自己查找相关文献进一步学习。
7. Reference
【1】《深度学习推荐系统》王喆编著。
【2】【Graph Embedding】DeepWalk:算法原理,实现和应用 - 浅梦的文章 - 知乎 https://zhuanlan.zhihu.com/p/56380812
【3】【论文笔记】DeepWalk - 陌上疏影凉的文章 - 知乎 https://zhuanlan.zhihu.com/p/45167021
【4】【Graph Embedding】LINE:算法原理,实现和应用 - 浅梦的文章 - 知乎 https://zhuanlan.zhihu.com/p/56478167
【5】Graph Embedding:从DeepWalk到SDNE - 羽刻的文章 - 知乎 https://zhuanlan.zhihu.com/p/33732033
【6】Graph Embedding之探索LINE - 张备的文章 - 知乎 https://zhuanlan.zhihu.com/p/74746503
【7】【Graph Embedding】node2vec:算法原理,实现和应用 - 浅梦的文章 - 知乎 https://zhuanlan.zhihu.com/p/56542707
【8】node2vec在工业界的应用-《当机器学习遇上复杂网络:解析微信朋友圈 Lookalike 算法》,地址:https://mp.weixin.qq.com/s/EV-25t2lWT2JJMLhXsz4zQ
【9】graph embedding之node2vec - 张备的文章 - 知乎 https://zhuanlan.zhihu.com/p/63631102
【10】Graph Embedding在淘宝推荐系统中的应用 - 张备的文章 - 知乎 https://zhuanlan.zhihu.com/p/70198918
【11】Graph Embedding - 阿里EGES算法 - 王多鱼的文章 - 知乎 https://zhuanlan.zhihu.com/p/69069878
【12】Graph Embedding:深度学习推荐系统的"基本操作" - 顾鹏的文章 - 知乎 https://zhuanlan.zhihu.com/p/68247149
【13】论文阅读:Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba,地址:https://blog.csdn.net/Super_Json/article/details/85537938