莫比乌斯: 百度的下一代query-ad匹配算法

本文介绍的内容来自于百度在KDD2019上的论文[1].
众所周知,百度、头条乃至于Google、Facebook的主要营收点在广告。广告业务的成败关系着众多互联网公司的生死。
由于广告存量的巨大,目前的需求是平均每次query需要从上亿的广告中筛选出相关的出来。因而目前百度现在的广告匹配算法采取三层结构:
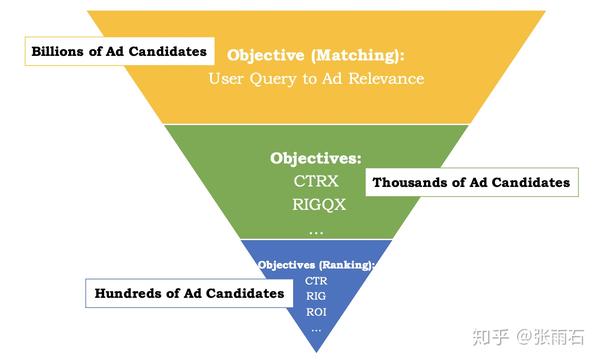
当用户进行查询的时候,跟Search类似,需要对query做后处理,包括query rewriting、query expansion和semantic matching。 然后使用快速查询的算法在上亿的广告中筛选出几千个candidate,即最上的Matching步所做的事情。
然后中间层使用部分CTR相关的指标和轻量级的CTR算法比如LR做进一步的筛选。得到几百个候选。
最后使用深度学习的模型做详细的排序。
这个架构从速度的角度考虑运行的完全没有问题,但是从目标的角度考虑,就有问题了,问题在于最前面的Matching算法跟最后的Ranking算法的目标不一致,这就会导致在最后排序的时候,可能最相关的广告并不在候选集合中,即便排的再好也无济于事。
莫比乌斯——目标合并的思想
莫比乌斯是一个项目名称,这个项目就是专门用来解决上述问题的,解决的方法自然是在Matching层就考虑到广告点击率相关的目标。即:
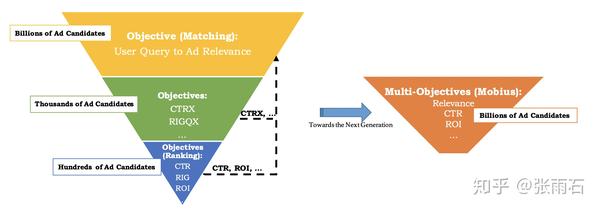
但是这样就会遇到两个问题:
- Insufficient click history,之前ranking层的模型是基于筛选后的query-ad对训练的,得到的模型对频繁的query或者ad的评分比较高,所以模型的问题是对于query-ad对,如果query或者ad有一个频繁出现,那么即使query-ad不相关,评分仍然会比都不频繁的query-ad对要高。
- 高计算量存储量需求,之前的三层架构就是为了性能所做的断舍离。CTR目标下沉之后就会对计算量和存储量产生大的需求。
为了解决上述两个问题,采用了如下几种方法:
- 将原来的Ranking的模型作为teacher,去训练一个student模型。通过主动学习的方式做数据增强,得到能够更准确判断稀疏数据的模型
- 采用目前最新的ANN(Approximate Nearest Neighbor)和MIPS(Maximum Inner Product Search)算法来加快计算速度。
问题表达
原来的Ranking层的目标是:
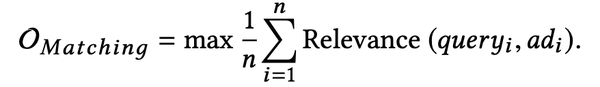
而莫比乌斯的目标是:
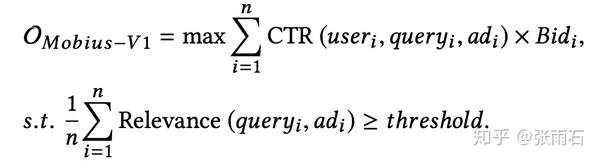
基于主动学习的CTR模型
无论是广告系统还是推荐系统,不可避免的会出现长尾问题和冷启动问题。这点会体现在稀疏数据的错误评分上,如下图

Tesla Model 3和Mercedes-Benz都是出现比较频繁的数据,White Rose 则不是。这里Tesla Model 3和Mercedes-Benz能够给出正确的相关度和CTR估计。但是对于White Rose而言,相关度确实很低,但是CTR评分却很高,导致了不正确的广告出现了。
为了解决这个问题,原来三层结构中的相关性模型被用来当做teacher模型来筛选query-ad对,流程如下图所示。分为两个步骤:
- 数据增强
- 点击率模型学习
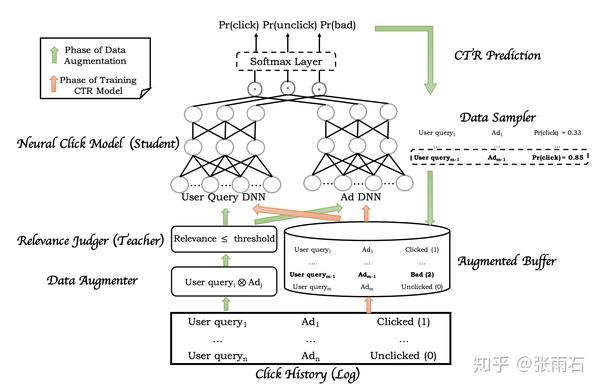
在数据增强这一步,首先,载入点击历史,得到ad-query对,然后找到ad的集合和query的集合,去做笛卡尔集。然后teacher模型给每一个query-ad对一个评分,用一个threshold来把低相关度的query-ad对找到。再把这些query-ad对fed给CTR模型,找到低相关度高CTR的数据作为bad case。
在模型训练这一步,点击历史中的click、unclick数据和数据增强中的bad case都被输入给模型,模型由两个子网络构成,左侧输入的是user history等信息,右侧则是广告信息,两个子网络分别输出三个长度为32的向量,然后三个向量分别去做内积,得到的三个结果输入给softmax层得到概率。
具体伪代码如下图:

ANN和MIPS加速查询
上面说到,三层结构是为了速度考虑,而变成莫比乌斯之后,去给上亿个广告去做点击率的估计是不现实的。
因而论文采用了ANN去做近似搜索,在上面的模型中,user query被embedding成三个向量,而ad也被embedding成三个向量,然后它们做内积再输入给softmax层,这就使得ANN搜索称为了可能,即直接使用embedding后的向量去做内积然后排序进行搜索。
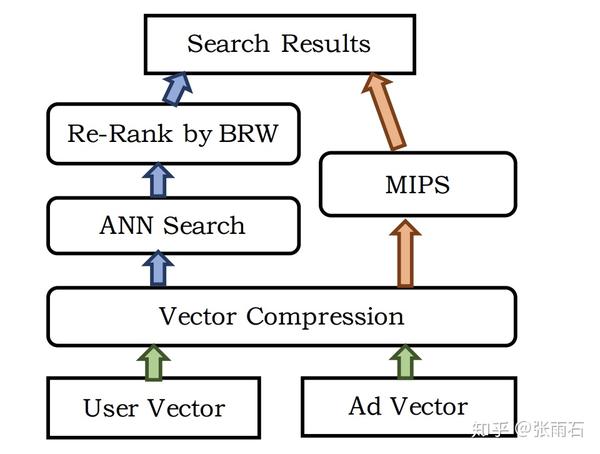
而在MIPS中,除了余弦相似度之外,还需要考虑一些商业上的权重,比如价格等等。
对于ANN和MIPS以及向量压缩的的优化内容,不在本文的介绍之内。但是大家可以预想到的是,这些优化可以使大规模搜索成为了可能。
实验
线下实验中:
可以保证AUC有些许损失的情况下,相关度大大提升。

同时,响应时间也在可控范围内:

在线上实验中,提升CPM 3.8个点
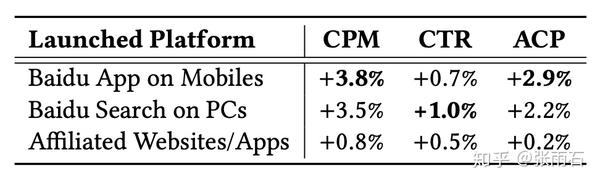
都是真金白银。
参考文献
[1]. Fan, Miao, et al. "Mobius: Towards the next generation of query-ad matching in Baidu's sponsored search." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
解密百度凤巢广告系统AI技术:用GPU训练千亿参数深度学习模型
寒冬刚过,当下正是全球紧张抗击新冠病毒疫情的特殊时期。3月2日早上7点,百度研究院(西雅图)办公室开展了一场远程学术报告,百度研究员向正在美国德克萨斯州奥斯丁市召开的MLSys(机器学习和系统结合的顶级AI学术会议)听众远程讲述了百度的论文。这篇论文介绍了百度最先进的凤巢广告系统的AI技术:Distributed Hierarchical GPU Parameter Server for Massive Scale Deep Learning Ads Systems。

这篇论文首先回顾了百度从2010年以来在广告技术中做的一系列世界领先的AI创新工作:
1、 百度开始使用分布式超大规模机器学习模型和分布式参数服务器存储学习模型。
2、2013年百度开始使用分布式超大规模深度学习模型,参数达到了千亿级。
3、2014年以来,百度开始开展大规模向量近邻检索(ANN)技术和最大内积检索(MIPS)技术研究并用于商用。(注:百度科学家因MIPS工作获得AI顶级学术会议NIPS 2014 最佳论文奖。)百度广告AI团队开始广泛使用ANN与MIPS技术来提高广告召回质量。
4、在2019年夏天美国阿拉斯加州举办的数据挖掘顶级学术会议KDD上,百度发表了使用近邻检索和最大内积检索技术来极大提高百度广告效果的论文:MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search。
5、2017年以来,百度广告AI团队开始尝试使用分布式GPU系统(4-8块GPU卡)来取代已经在百度使用了10多年的MPI CPU集群。这是本篇论文的内容。
论文主要讲述如何用小型的GPU-SSD 集群来训练千亿参数模型。
在众多机器学习应用中,模型的大小通常在"数万"或"百万"这个数量级上。特别大的模型比如ResNet-152(6千万)和BERT-Large(3亿)也远远不到千亿这个量级。百度广告搜索结合了用户特征,查询关键词特征,广告特征等信息,输入参数的维度可以达到数千亿,要应用千亿维的数据来预测广告点击率就需要用到千亿参数的模型。千亿个参数就意味着需要10TB(10万亿字节)才能储存这些模型参数。这么大规模的机器学习以往需要数百台的计算节点来处理,由于当前最先进的GPU也只有32 GB的显存,完全不可能将千亿模型完整放进GPU。因此,尽管GPU相对CPU有非常好的加速优势,但是一直以来工业界没有办法用GPU来训练广告点击模型。
论文回顾了2015 年百度用哈希技术来减小模型的尝试。实验表明合适的哈希方法可以有效地减小模型大小,用哈希技术与深度学习结合的方法能显著地提高逻辑回归模型的准确率,并且模型可以非常小,单机就可以装下。但是基于哈希技术的模型压缩并不是无损的,要更进一步提高准确率的话,就还是需要用到原始千亿维向量来训练深度学习模型。
自从2017年以来,百度广告AI团队创造性地结合了GPU和SSD (即固态硬盘),在业界首次提出用分布式层级参数服务器的方案来解决千亿模型参数的训练难题。其中一个很大的难题是SSD的读取速度比内存要慢一到两个数量级。百度广告AI技术团队克服了一系列艰巨的技术难题,经过较长研发迭代周期,从系统层面圆满的解决了一系列的技术难题,在全世界首次实现了商用的GPU-SSD大规模深度学习广告系统。
目前使用的分布式层级参数服务器只需要4个GPU节点,训练速度就能比150个CPU节点的计算集群快2倍,性价比高9倍!这大大提高了研究人员试验和验证新模型的效率,使得更多的研究员和工程师能同时在更短的时间用更少的资源来迭代新的策略。同时,分布式层级参数服务器的可扩展性也很强,论文中使用1、2、4个GPU节点来测试,都表现出了几乎理想的线性的效率提升,这也使得未来训练更大数量级的模型成为可能。
此外,这篇论文的第一作者赵炜捷博士是百度研究院美研的第一批博士后。该博士后项目由百度CTO兼百度研究院院长王海峰博士支持下设立,目的是让刚毕业的博士可以在百度研究院心无旁骛开展基础研究。
论文中的系统也与百度飞桨深度学习平台深度结合,为中国完全自主知识产权的深度学习平台贡献了力量。
解密百度凤巢广告系统AI技术:用GPU训练千亿参数深度学习模型
浅谈百度新一代query-ad 推荐引擎如何提升广告收益率
今天看了一篇论文,是某顶会的被推荐为最值得阅读的论文之一。题目是《MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search》,里面有几个观点挺新颖的,跟大家分享下。
首先 query-ad 指的就是搜一个信息然后展示一个广告,用户点击广告会付费,向百度这样的体量,单纯这样的广告营收转化每天可能就有上亿元。
在这个论文里,百度的研究员提了一个很有趣的观点:传统的召回 - 排序架构,可能对于 CPM 转化不是最理想的(CPM = CTR × Bid
),这个观点挺有趣的,接下来看下百度是怎么证明这个问题并解决的。
01 传统的召回 - 排序框架有什么问题?
传统的推荐架构是这样分工的,将推进分为召回和排序模块,召回负责解决相关性问题,排序解决业务目标的问题。以搜索广告为例,召回模块的作用是首先遍历出跟用户检索信息相关的广告,然后排序模块负责找出那些广告用户点击带来的 CPM 最高。
百度认为这种做法并不经济,因为如果召回阶段只考虑相关性的话会产生大量没有价值的召回候选集,这些内容在接下来排序的过程中是一种资源浪费。另外对于一些低频出现的但是可能触发高 CPM 的广告,在召回阶段可能会过滤掉,因为召回并没有考虑 CPM。
02 怎么解决召回阶段没考虑 CPM 这个问题呢?
答案就是在召回阶段加一层,这一层负责考虑业务属性。
绿色这一层就是增加的层。这一层他希望给相关性加一个 threshold,在召回候选集满足大于 threshold 的同时让 CPM 最大(下图上边公式是 CPM 的计算公式)。
这么做的一个结果我感觉就是那种跟搜索内容没有特别高的相关性的但是很贵的广告也会出现在广告列表。
流程图如下:
先把 user 和 ad 做 vector,然后做 vector compression,这里的 compression 不是压缩的意思,有点向量分桶的意思,通过 kmeans 算法把向量按照 index 分成不同的类别(我有点没太看懂这一段)。
| 3.2.3 Vector Compression. Storing a high-dimensional floatingpoint feature vector for each of billions of ads takes a large amount of disk space and poses even more problems if these features need to be in memory for fast ranking. A general solution is compressing floating-point feature vectors into random binary (or integer) hash codes [7, 28, 30], or quantized codes [23]. The compression process may reduce the retrieval recall to an extent but it may bring significant storage benefits. For the current implementation, we adopted a quantization based method like K-Means to cluster our index vectors, rather than ranking all ad vectors in the index. When a query comes, we first find the cluster that the query vector is assigned to and fetch the ads that belong to the same cluster from the index. The idea of product quantization (PQ) [23] goes one more step further to split vectors into several subvectors and to cluster each split separately. In our CTR model, as mentioned in Section 3.1, we split both query embeddings and ad embeddings into three subvectors. Then each vector can be assigned to a triplet of cluster centroids. For example, if we choose 10^3 centroids for each group of subvectors, 10^9 possible cluster centroids can be exploited which is adequate for a billion-scale multi-index [26] for ads. In Mobius-V1, we employ a variant algorithm called Optimized Product Quantization (OPQ) [14]. | |
理解 product quantization 算法
1. 引言Product quantization,国内有人直译为乘积量化,这里的乘积是指笛卡尔积(Cartesian product),意思是指把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化(quantization)。这样每个向量就能由多个低维空间的量化 code 组合表示。为简洁描述起见,下文用 PQ 作为 product quantization 的简称。 The idea is to decomposes the space into a Cartesian product of low dimensional subspaces and to quantize each subspace separately. A vector is represented by a short code composed of its subspace quantization indices. 2011 年,Herve Jegou 等学者在 PAMI 上发表了 PQ 方法的第一篇正式 paper[1],用于解决相似搜索问题(similarity search)或者也可以说是近邻搜索(nearest neighbor search)问题。其实这几位作者在 2009 年的 INRIA(即法国国家信息与自动化研究所)的技术报告上已经发表 PQ 方法。这里插一段题外话,[1] 的一作 Herve Jegou 和二作 Matthijs Douze 均在 2015 年跳槽去了 Facebook AI research,并在今年 3 月份合作开源了 Faiss 相似搜索工具 [4]。 近几年,深度学习技术被广泛用于图像识别、语音识别、自然语言处理等领域,能够把每个实体(图像、语音、文本)转换为对应的 embedding 向量。一般来说,相似的实体转换得到的 embedding 向量也是相似的。对于相似搜索问题,最简单的想法是暴力穷举法,如果全部实体的个数是n,n是千万量级甚至是上亿的规模,每个实体对应的向量是D,那么当要从这个实体集合中寻找某个实体的相似实体,暴力穷举的计算复杂度是O(n×D),这是一个非常大的计算量,该方法显然不可取。所以对大数据量下高维度数据的相似搜索场景,我们就需要一些高效的相似搜索技术,而 PQ 就是其中一类方法。 PQ 是一种量化(quantization)方法,本质上是数据的一种压缩表达方法(其实通信学科的一个主要研究工作就是研究信号的压缩表达),所以该方法除了可以用在相似搜索外,还可以用于模型压缩,特别是深度神经网络的模型压缩上。由于相似搜索不仅要考虑如何量化的问题,还要考虑如何检索(search)的问题,而模型压缩可能更主要的是考虑如何量化的问题,不用太关注如何检索这个问题,所以这篇文章会主要站在相似搜索上的应用来介绍 PQ 方法。至于模型压缩,可以找找近几年研究神经网络模型压缩的 paper 或者一些互联网公司(比如百度, Snap 等)发出的一些资料 [3]。 2. 相似搜索的若干种方法参考文献 [5][6] 很好的总结了相似搜索的几类方法,这里简要总结几个核心点。可以将方法分为三大类:
3. Product Quantization 算法的核心文献 [1] 详细介绍了 PQ 算法的过程和时间复杂度分析,这篇博客的第 3 节和第 4 节简要总结下其中的若干要点。 在介绍 PQ 算法前,先简要介绍 vector quantization。在信息论里,quantization 是一个被充分研究的概念。Vector quantization 定义了一个量化器 quantizer,即一个映射函数q,它将一个D维向量x转换码本 cookbook 中的一个向量,这个码本的大小用k表示。 Quantization is a destructive process which has been extensively studied in information theory. Its purpose is to reduce the cardinality of the representation space, in particular when the input data is real-valued. Formally, a quantizer is a function q mapping a D-dimensional vector x∈RD to a vector q(x)∈C=ci;i∈I, where the index set I is from now on assumed to be finite: I=0,⋯,k−1. The reproduction values ci are called centroids. The set of reproduction values C is the codebook of size k. 如果希望量化器达到最优,那么需要量化器满足 Lloyd 最优化条件。而这个最优量化器,恰巧就能对应到机器学习领域最常用的 kmeans 聚类算法。需要注意的是 kmeans 算法的损失函数不是凸函数,受初始点设置的影响,算法可能会收敛到不同的聚类中心点(局部最优解),当然有 kmeans++ 等方法来解决这个问题,对这个问题,这篇文章就不多做描述。一般来说,码本的大小k一般会是 2 的幂次方,那么就可以用log2k bit 对应的向量来表示码本的每个值。 有了 vector quantization 算法的铺垫,就好理解 PQ 算法。其实 PQ 算法可以理解为是对 vector quantization 做了一次分治,首先把原始的向量空间分解为 m 个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化,那如何对低维向量空间做量化呢?恰巧又正是用 kmeans 算法。所以换句话描述就是,把原始D维向量(比如D=128)分成m组(比如m=4),每组就是D∗=D/m维的子向量(比如D∗=D/m=128/4=32),各自用 kmeans 算法学习到一个码本,然后这些码本的笛卡尔积就是原始D维向量对应的码本。用qj表示第j组子向量,用Cj表示其对应学习到的码本,那么原始D维向量对应的码本就是C=C1×C2×…×Cm。用k∗表示子向量的聚类中心点数或者说码本大小,那么原始 D 维向量对应的聚类中心点数或者说码本大小就是k=(k∗)m。可以看到m=1或者m=D是 PQ 算法的 2 种极端情况,对m=1,PQ 算法就回退到 vector quantization,对m=D,PQ 算法相当于对原始向量的每一维都用 kmeans 算出码本。 The strength of a product quantizer is to produce a large set of centroids from several small sets of centroids: those associated with the subquantizers. When learning the subquantizers using Lloyd’s algorithm, a limited number of vectors is used, but the codebook is, to some extent, still adapted to the data distribution to represent. The complexity of learning the quantizer is m times the complexity of performing k-means clustering with k∗ centroids of dimension D∗. 如图 1 所示,论文作者在一些数据集上调试k∗和m,综合考虑向量的编码长度和平方误差,最后得到一个结论或者说默认配置,k∗=256和m=8。像这样一种默认配置,相当于用 m×log2k∗=8×log2256=64 bits=8 bytes来表示一个原始向量。图 2 是在这个默认配置下对 128 维的原始数据用 PQ 算法的示意图。 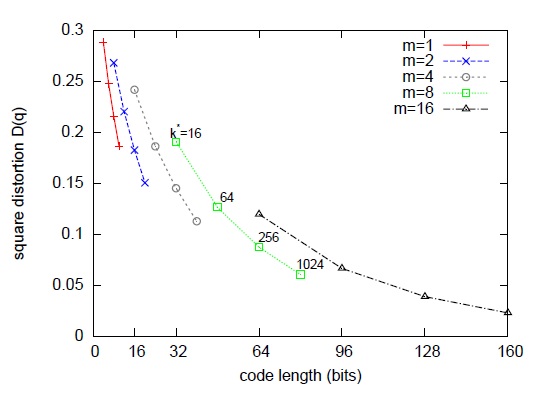 图 1 量化误差与 m 和 k * 之间的关系 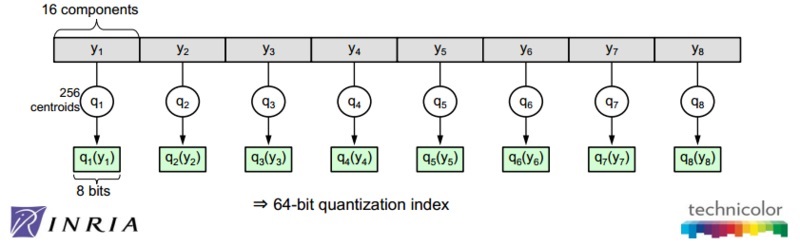 图 2 PQ 算法的示意图 上面介绍了如何建立 PQ 的量化器,下面将介绍如何基于这些量化器做相似搜索。有 2 种方法做相似搜索,一种是 SDC(symmetric distance computation),另一种是 ADC(asymmetric distance computation)。SDC 算法和 ADC 算法的区别在于是否要对查询向量x做量化,参见公式 1 和公式 2。如图 3 所示,x是查询向量 (query vector),y是数据集中的某个向量,目标是要在数据集中找到x的相似向量。 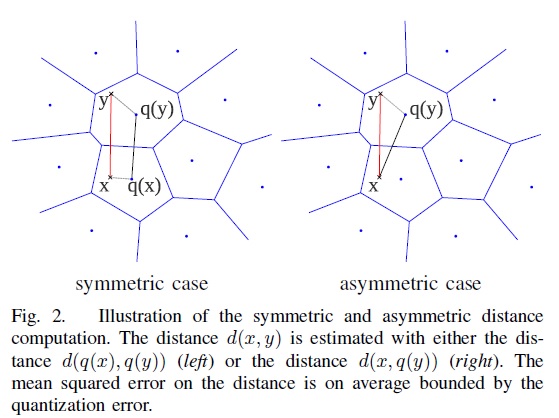 图 3 SDC 和 ADC 的示意图 SDC 算法:先用 PQ 量化器对x和y表示为对应的中心点q(x)和q(y),然后用公式 1 来近似d(x,y)。 d̂ (x,y)=d(q(x),q(y))=∑jd(qj(x),qj(y))2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√(1)
对 SDC 的 2 点补充说明:
ADC 算法:只对y表示为对应的中心点q(y),然后用公式 2 来近似d(x,y)。 d˜(x,y)=d(x,q(y))=∑jd(uj(x),qj(uj(y)))2‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾√(2)
对 ADC 的 2 点补充说明:
图 4 对比了 SDC 算法和 ADC 算法的各阶段复杂度,当n>k∗D∗时,计算瓶颈存在于公式 1 和公式 2 的计算上,它们的复杂度都是O(n×m)。  图 4 对比 SDC 和 ADC 的各阶段计算复杂度 文献 [1] 还对 SDC 和 ADC 算法做了两点更深入的分析,第一点是对距离的期望误差的上界进行分析。对 ADC 算法而言,距离的期望误差的上界只与量化误差有关,与输入的x无关,而对 SDC 算法而言,距离的期望误差的上界是 ADC 距离的期望误差的上界的两倍,所以作者建议在应用时倾向于用 ADC 算法。作者做的第二点分析是计算距离的平方的期望,并希望通过矫正拿到距离的无偏估计。作者虽然推导出校准项,但在实验中却发现加上校准项反倒使得距离的残差的方差加大了,所以作者建议在应用时倾向于不加校准项,也就是说还是用公式 1 或者公式 2 做计算。 4. Product Quantization 算法的改进第 3 节介绍了 SDC 和 ADC 算法,当n>k∗D∗时,计算瓶颈存在于公式 1 和公式 2 的计算上,它们的复杂度都是O(n×m)。实际中n可能是千万量级甚至更大,虽然相比暴力搜索算法,PQ 算法已经减少了计算量,但计算量依旧很大,并不实用。所以作者提出了 IVFADC 算法,一种基于倒排索引的 ADC 算法。简而言之,该算法包含 2 层量化,第 1 层被称为 coarse quantizer,粗粒度量化器,在原始的向量空间中,基于 kmeans 聚类出k′个簇(文献 [8] 建议k′=n‾√)。第 2 层是上文讲的 PQ 量化器,不过这个 PQ 量化器不是直接在原始数据上做,而是经过第 1 层量化后,计算出每个数据与其量化中心的残差后,对这个残差数据集进行 PQ 量化。用 PQ 处理残差,而不是原始数据的原因是残差的方差或者能量比原始数据的方差或者能量要小。图 5 是该方法的索引和查询的流程图。 The energy of the residual vector is small compared to that of the vector itself. 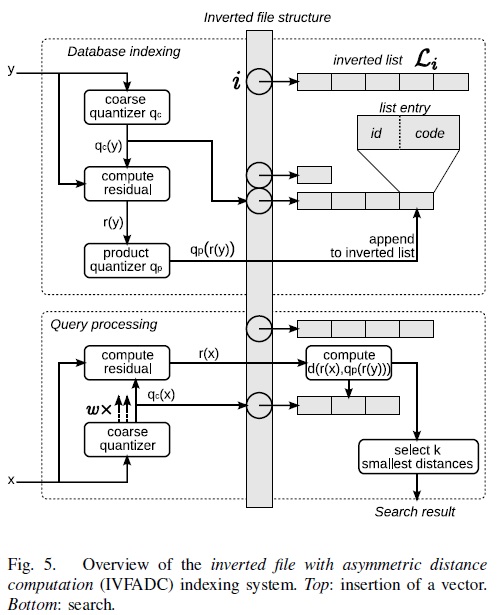 图 5 IVFADC 算法的索引和查询的流程图 对 IVFADC 的 3 点补充说明:
参考文献[1] Product quantization for nearest neighbor search [2] Efficient matching and indexing [4] Faiss [6] What are some fast similarity search algorithms and data structures for high-dimensional vectors? [7] Locality-Sensitive Hashing: a Primer [8] Billion-scale similarity search with GPUs [9] 解读 Product quantization for nearest neighbor search 原创文章,转载请注明:转载自 vividfree 的博客 本文链接地址:理解 product quantization 算法 |
然后就是常规的 ANN&MIPS,ANN 就 approximate nearest neighbor,ANN 简单来说就是向量欧氏距离或者余弦距离。MIPS 就是 maximum inner product search,就是找出向量机最大的列表。这些都是推荐领域很常规的操作,但是百度很明确说了在大规模数据下 ANN 比较好的方案是 random partition tree method,这个可以了解下。
03 总结
本文提到的方法经过百度自己的测试,能达到很好地业务效果。
我自己的感觉,确实在召回阶段加一些业务的目标还是比较有价值的,把业务属性全由排序模块负责可能有模块 1 讲的问题。
PS:百度这个项目名字也挺逗的,他是这样解释的:
“Mobius” is Baidu’s internal code name of this project. Coinciden- tally, the well-known “Mobius Loop” is also the bird’s eye view of Baidu’s Technology Park in Beijing, China;