引入平移不变性
图像中的目标不管被移动到哪个位置,得到的结果(分类标签)应该是相同的,卷积神经网络具有平移不变性。因为图像经过平移,相应的特征图上的表达也是平移的,无论目标出现在图像的哪个位置,它都会检测到同样的这些特征,输出同样的响应。在ROIPooling之后的proposal相对整张图是完全独立出来的个体,每一个proposal都需要单独的训练,所以pooling之后就不再具备平移不变性了。ROI层提取出的proposal中,有的对应前景label,有的对应背景label,proposal位置的偏移就有可能造成label分类(前景和背景分类)的不同。偏移后原来的前景很有可能变成了背景,原来的背景很有可能变成了前景,换句话说分类loss对proposal的位置是敏感的,这种情况ROI层给深层网络带来了平移可变性,但是随着网络的加深,这种平移可变性就变差,这时proposal的一个小偏移在深层的特征图上很有可能都感知不到,即proposal对应的label没有改变,所以深层特征图后虽然有ROI也对平移可变性没有什么帮助,识别出来的位置准确度会很差。
下面介绍R-FCN网络
网络结构
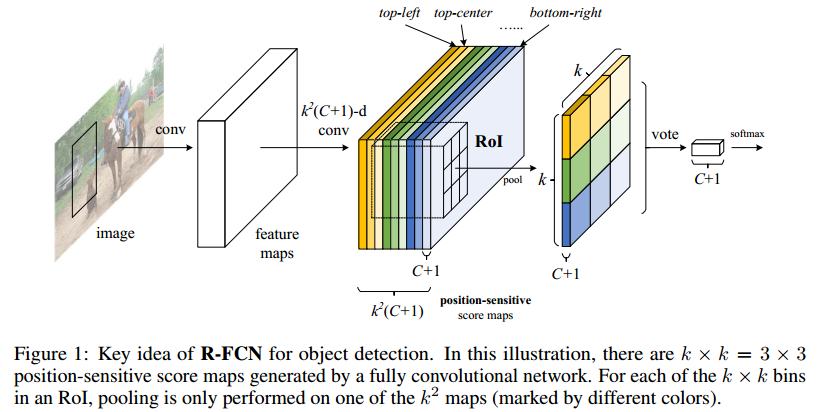
为了解决上述问题,引入了Position sensitive score map 这个概念,可以把目标的位置信息融合进ROIPooling。
(1)Backbone architecture:
对于ResNet101网络去掉最后一层全连接层,保留前100层,再接一个1×1×1024的全连接层(100层输出的维度为2048,为了降维引入了一个1×1的卷积层)
(2)k2(c+1)的conv:
ResNet的输出是W×H×1024,用K2(C+1)个1×1的卷积核去卷积即可得到K2(C+1)个大小为W×H的position sensitive 的score map。这步的卷积就是在做预测。K=3,表示把一个ROI划分成3×3,对应的9个位置分别为:上左(左上角),上中,上右,中左,中中,中右,下左,下中,下右(右下角)
(3)K2×(C+1)个feature map的物理意义:
共有k×k=9个颜色,每个颜色的立体块(W×H×(C+1))表示的是不同位置存在目标的概率值(第一块黄色表示的是左上角位置,最后一块淡蓝色表示的是右下角位置)。共有k2×(C+1)个feature map。每个feature map,z(i,j,c)是第i+k(j-1)个立体块上的第c个map(1<= i,j <=3)。(i,j)决定了9种位置的某一种位置,假设为左上角位置(i=j=1),c决定了哪一类,假设为person类。在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置上可能是人(c='person')且是人的左上部位(i=j=1)的概率值。
(4)ROIpooling的输入和输出:
每个颜色的立体块(C+1)都只抠出对应位置的一个bin,把这k×k个bin组成新的立体块,大小为(C+1)×W'×H'(W'和H是ROI的宽和高)。例如,上图中的第一块黄色只取左上角的bin,最后一块淡蓝色只取右下角的bin。所有的bin重新组合后就变成了一个新的薄的立体块(图中的这个是池化后的输出,即每个面上的每个bin上已经是一个像素。池化前这个bin对应的是一个区域,是多个像素)。ROI pooling的输出为一个(C+1)×k×k的立体块.
(5)vote投票:
最后将这些特征图经过全局平均池化,得到c+1维向量,计算分类损失函数。