10. 执行配置优化
● 一个 SM中,占用率 = 活动线程的数量 / 最大可能活动线程的数量。后者保存在设备属性的 maxThreadsPerMultiProcessor 分量中(GTX1070为例,该值为2048)。较高的占用率不代表计算效率很高,但是较低的占用率意味着内存延迟严重,还有改进的空间。
● 寄存器有效性是决定占用率的几个因素之一。寄存器读取比内存读取的延迟低很多,但是寄存器组(register file)数量有限,硬件上被整个 SM 上的所有线程共享,软件上一次只能给一个线程块使用,若线程块使用的寄存器过多,则会减少SM上同时运行的线程块和线程数量,降低占用率。每个线程使用寄存器上限可以在在编译时使用 -maxrregcount 选项进行指定,或每内核使用限定符 __launch_bounds__ 。
● 寄存器限制的计算过程。以我的 GTX1070(CC = 6.1)为例,影响SM中活动线程块数量的因素有以下这些。参考了 CUDA C Programming Guide,其他教材或博客上都不完整。

■ 当给定一个设备和程序时,首先应该自然满足:tw = 32,tb ≤ tbmax,rt ≤ rtmax,rb = rt·tb ≤ rbmax,sb ≤ sbmax,不然核函数直接报错退出。
■ 考虑到线程数(或等价的线程束数)、寄存器数、共享内存大小这三个方面,需要满足下式条件(第二行与第三行等价,一个以线程的角度考虑,一个以线程束的角度考虑),

■ 考虑 bs 在各约束下的上界,得到一个SM上活跃线程块的解:

■ 于是占用率可用下式计算,(两个算法等价,一个以线程的角度考虑,一个以线程束的角度考虑),第二个算法占用率计算器 CUDADocumentation_tools_CUDA_Occupancy_Calculator.xls 中才用得到算法。

■ 计算案例:tsmax = 768,rsmax = 8192,tb = 128,rt = 12,不考虑 sb 。解答:tsmax / tb = 6,rsmax / (rt * tb) = 5,blockactive = 5,γ1 = 83 %
■ 补充,CUDADocumentation_tools_CUDA_Occupancy_Calculator.xls 给出了更好的计算结果,可以在指定计算能力的情况下计算各种 tb,rt,sb 组合的占用率并化成了图。另外涉及了几个在上述计算中没有考虑的细节:Register allocation unit size = 256(寄存器申请数量基数),Register allocation granularity = warp(寄存器申请粒度,都是 warp),Shared Memory allocation unit size = 256(共享内存申请基数),Warp allocation granularity = 4(warp 数量基数),这样就会引入一堆取整函数,针对每种稀奇古怪的 tb,rt,sb组合都能算出占用率。
● nvcc 命令中使用选项 --ptxas options=v 来规定每个线程使用的寄存器数量。
● 启用线程网格时的一些启示。
■ 线程块中的线程数应该取作线程束尺寸的倍数,以便充分利用内存合并读写,避免非饱和线程束造成的浪费。
■ 适当减小线程尺寸,使得等待 __syncthreads(); 的线程变少,降低内存延迟。另一方面,经验上线程尺寸不应小于 64,128 至 256 为宜,除非线程块数量可以很大 。
■ 网格中的线程块数应该大于 SM 数,使每个 SM 都至少有一个线程块进行计算。如 GTX1070 有 16 个SM,则调用核函数时应尽量使 gridDim.x > 16 (一维)。
■ 高占用率意味着每个线程能够使用的寄存器数量较少,通常占用率大于 50 % 以后继续提高占用率对效率提升帮助不明显,这时增加线程寄存器数量,减小内存读写延迟意义更大。
■ 共享内存大小与线程块大小相关,但一般与线程数无关,应使用一个线程对多个共享内存进行操作。
11. 指令级优化
● 算术指令优化(编译器可以完成)。如 n 为 2 的整数幂,则 i / n 等价于 i >> log2(n),i % n 等价于 i & ( n - 1 ) 。
● 浮点数计算尽量使用内置函数,如使用 rsqrtf( x ) 而不是 1.0f / sqrtf( x );单精度函数,如使用 sqrtf( x ) 而不是 sqrt( x )。
● 避免隐式格式转换。如对 char 和 short 的操作通常会转换成 int,使用没有预设为 float 的浮点参数(默认为 double)使 float 变量转换成 double。
● 绝对值较小的有理型指数运算(如计算 x2/3)可以使用 sqrt()、cbrt()、rsqrt()、rcbrt() 等函数进行组合,计算效率高于 pow() (可计算指数为浮点数的情况);绝对值较小的整形指数运算(如计算 x2、x5)可以使用显式乘法或等价的 inline 函数、宏函数等来完成,计算效率高于pow() 。
● exp2() 、exp2f() 、exp10() 、exp10f() 与 exp() 、expf() 效率接近,替代 pow() 或 powf(),计算效率高一个数量级左右。
● 使用 sinpi() 、sinpif() 替代 sin(π * <expr>) 或 sinf(π * <expr>) ,不仅计算速度快且内含 π 的精度也较高。
● nvcc 命令中调整数据精度的一些选项。 -ftz=true 非初始化的数据都默认为0; -prec-div=false 降低除法精度; -prec-sqrt=false 降低平方根计算精度。
● 使用不同类型的内置函数:functionName(),functionNamef(),__functionNamef() 。如 sin(x); 用于计算双精度正弦, sinf(x); 用于计算单精度正弦, __sinf(x); 用于计算可接受精度损失条件下的单精度正弦。__sinf(x) 比 sinf(x) 损失一些精度,但是速度快一个量级,在直接输出结果、不需要进一步规约或减低结果量级的情况下可以使用)
● nvcc 命令中使用选项 -use_fast_math 来强制转化所有 functionNamef() 为 __functionNamef() 。
12. 控制计算流程
● 避免线程分支,分支尽量在线程束之间进行,而一个线程束内部不分。
● Volta 构架开始支持独立线程调度,可以使那些有 “不依赖于数据的分支” 的线程束中的线程独立运行, 然后使用函数 __syncwarp(); 来同步线程束。
● 分支预测,可由编译器部分完成,也可由程序员部分控制(如使用预编译命令 #pragma unroll 来展开循环或者判断)。在程序运行时所有分支指令都会被调度,但只有正确谓词的指令被用上。当分支指令少于某一个阈值的时候,编译器会使用预测指令替代分支指令,减少线程束发散。
● 循环变量使用有符号整数,与编译器优化有关。
● 代码分支时谨慎使用 __syncthreads(); ,如下例所示。
1 int imax = (nElement + blockDim.x - 1) / blockDim.x * blockDim.x; 2 // 规定下标 i 的范围,向上对齐到 blockDim.x整数倍,保证不小于 nElement,且所有线程迭代次数相等 3 4 for (int i = threadIdx.x; i < imax; i += blockDim.x)// 每次迭代读取 blockDim.x 个下标 5 { 6 if (i < nElement) // 控制访问范围,最后一次迭代向下对齐到 nElement 7 { 8 ... 9 } 10 11 __syncthreads(); // 线程同步放到条件语句外 12 13 if (i < nElement) // 同步后的下一步工作 14 { 15 ... 16 } 17 }
● (?) Similar care must be taken when invoking__syncthreads();from a device function called from potentially divergent code. A straightforward method of solving this issue is to call the device function from non-divergent code and pass a thread_active flag as a parameter to the device function. This thread_active flag would be used to indicate which threads should participate in the computation inside the device function, allowing all threads to participate in the __syncthreads(); .
13. 应用部署
14. 理解编程环境
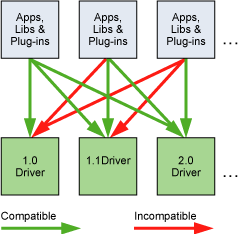
● CUDA Driver API 和 CUDA Runtime API 是两套不同的编程接口。Driver API 向后兼容但不向前兼容(对 Driver 有最低版本要求)。
● CUDA Runtime
■ 主机 Runtime 环境提供函数功能包括:设备管理、上下文管理、内存管理、代码模块管理、执行控制、纹理引用管理、基于OpenGL和Direct3D的互操作性。Runtime 主要完成了控制内核函数加载、设置内核参数、隐式驱动版本检查、代码初始化、CUDA上下文管理、模块管理、内核的配置、参数传递等过程。
■ 与低级别的 CUDA Driver API相比,CUDA Runtime 简化了管理过程。nvcc 生成的 C/C++代码自动使用 CUDA Runtime。另外,cuBLAS、cuFFT 等工具包也依赖于 Runtime。
cuda_runtime_api.h // C 语言的 CUDA Runtime 接口头文件
cuda_runtime.h // C++ 语言的 CUDA Runtime 借口头文件,依赖于cuda_runtime_api.h
15. 部署准备
● 在不知道运行 CUDA 应用的设备的情况下,程序应该显式地检查设备和运行状况。包括设备数量,计算能力,以及计算过程中的错误。
● CUDA Runtime API 既不能保证向前兼容,也不能保证向后兼容,所以有时需要在应用发布时附上 Runtime Restribution,用动态或静态链接的方式保证运行环境。同一台设备上可能有多个 Runtime 环境,但只要 Driver 均支持即可。
● 默认条件下 nvcc 使用静态链接,使得源代码少少变大,但是保证了 Runtime 文件能被正确读取到。也可在 nvcc 命令中使用选项 --cudart=shared 来控制动态链接源。
● 有关 Linux ,MacOS,Windows 上动态库的一些内容,看不懂。
16. 部署基础设施工具
● Nvidia-SMI ,NVIDIA系统管理工具。
● NVML,NVIDIA 管理库,用于生成第三方管理工具的接口函数库。
● Cluster Management Tools,集群管理工具。
● Compiler JIT Cache Management Tools,即时编译管理工具。
● CUDA_VISIBLE_DEVICE,CUDA 可视化工具。