DataFrame & Series
DataFrames
数据框是一种二维数据结构,即数据在行和列中以表格方式对齐。
以下是数据框架的特征。
- 潜在的列是不同的类型
- 大小 – 可变
- 带标签的轴(行和列)
- 可以对行和列进行算术运算
结构【structure】
让我们假设我们正在使用学生的数据创建一个数据框。
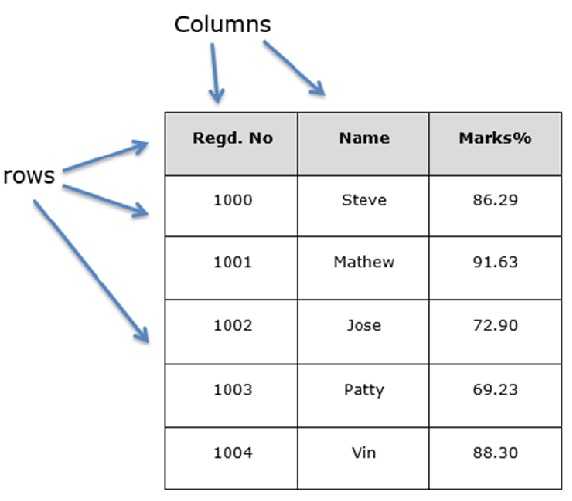
您可以将其视为 SQL 表或电子表格数据表示。
pandas.DataFrame
-
可以使用以下构造函数创建 Pandas DataFrame -
pandas.DataFrame( data, index, columns, dtype, copy) -
构造函数的参数如下 -
Sr.No Parameter & Description 1 data: data 采用各种形式,如 ndarray, series, map, lists, dict, constants and also another DataFrame. 2 index: 对于行标签,如果没有传递索引,则用于结果帧的索引是可选的默认 np.arange(n)。 3 columns: 对于列标签,可选的默认语法是 - np.arange(n)。这仅在没有传递索引时才成立。 4 dtype: 每列的数据类型。 5 copy: 如果默认值为 False,则此命令(或其他任何命令)用于复制数据。
Create an Empty DataFrame
可以创建的基本数据帧是空数据帧。
Example
#import the pandas library and aliasing as pd
import pandas as pd
df = pd.DataFrame()
print df
Its output is as follows −
Empty DataFrame
Columns: []
Index: []
Create a DataFrame from Lists
可以使用单个列表或列表的列表创建 DataFrame。
Example 1
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print df
Its output is as follows −
0
0 1
1 2
2 3
3 4
4 5
Example 2
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print df
Example 3
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'],dtype=float)
print df
Its output is as follows −
Name Age
0 Alex 10.0
1 Bob 12.0
2 Clarke 13.0
注意 - 显而易见,dtype 参数将 Age 列的类型更改为浮点数。
Create a DataFrame from Dict of ndarrays / Lists
所有 ndarray 必须具有相同的长度。如果没有传递索引,则索引的长度应等于数组的长度。
如果索引未传递,则默认情况下,索引长将为 range(n),其中 n 是数组长度。
Example 1
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print df
Its output is as follows −
Age Name
0 28 Tom
1 34 Jack
2 29 Steve
3 42 Ricky
注意 - 显而易见 0,1,2,3。它们是使用函数 range(n) 分配给每个的默认索引。
Example 2
现在让我们使用arrays创建一个带索引的 DataFrame。
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print df
Its output is as follows −
Age Name
rank1 28 Tom
rank2 34 Jack
rank3 29 Steve
rank4 42 Ricky
注意 - 显而易见,索引参数为每一行分配一个索引。
Create a DataFrame from List of Dicts
字典列表可以作为输入数据传递以创建一个 DataFrame。默认情况下,字典的键作为列名。
Example 1
The following example shows how to create a DataFrame by passing a list of dictionaries.
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print df
Its output is as follows −
a b c
0 1 2 NaN
1 5 10 20.0
Note -显而易见,NaN(非数字)附加在缺失区域。
Example 2
The following example shows how to create a DataFrame by passing a list of dictionaries and the row indices.
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data, index=['first', 'second'])
print df
Its output is as follows −
a b c
first 1 2 NaN
second 5 10 20.0
Example 3
The following example shows how to create a DataFrame with a list of dictionaries, row indices, and column indices.
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
#With two column indices, values same as dictionary keys
df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])
#With two column indices with one index with other name
df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])
print df1
print df2
Its output is as follows −
#df1 output
a b
first 1 2
second 5 10
#df2 output
a b1
first 1 NaN
second 5 NaN
Note − Observe, df2 DataFrame is created with a column index other than the dictionary key; thus, appended the NaN’s in place. Whereas, df1 is created with column indices same as dictionary keys, so NaN’s appended.
Create a DataFrame from Dict of Series
可以通过Dict of Series以形成数据帧。结果索引是所有通过的系列索引的并集。
Example
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df
Its output is as follows −
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
Note − Observe, 对于系列一,没有传递标签“d”,但在结果中,对于 d 标签, 附加了 NaN。
现在让我们通过示例了解列的选择、添加和删除。
Column Selection
从 DataFrame 中选择一列。
Example
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df ['one']
Its output is as follows −
a 1.0
b 2.0
c 3.0
d NaN
Name: one, dtype: float64
Column Addition
向现有DataFrame添加新列
Example
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
# Adding a new column to an existing DataFrame object with column label by passing new series
print ("Adding a new column by passing as Series:")
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print df
print ("Adding a new column using the existing columns in DataFrame:")
df['four']=df['one']+df['three']
print df
Its output is as follows −
Adding a new column by passing as Series:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d NaN 4 NaN
Adding a new column using the existing columns in DataFrame:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d NaN 4 NaN NaN
Column Deletion
Columns can be deleted or popped;
Example
# Using the previous DataFrame, we will delete a column
# using del function
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print ("Our dataframe is:")
print df
# using del function
print ("Deleting the first column using DEL function:")
del df['one']
print df
# using pop function
print ("Deleting another column using POP function:")
df.pop('two')
print df
Its output is as follows −
Our dataframe is:
one three two
a 1.0 10.0 1
b 2.0 20.0 2
c 3.0 30.0 3
d NaN NaN 4
Deleting the first column using DEL function:
three two
a 10.0 1
b 20.0 2
c 30.0 3
d NaN 4
Deleting another column using POP function:
three
a 10.0
b 20.0
c 30.0
d NaN
Row Selection, Addition, and Deletion
We will now understand row selection, addition and deletion through examples.
Selection by Label
Rows can be selected by passing row label to a loc function.
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df.loc['b']
Its output is as follows −
one 2.0
two 2.0
Name: b, dtype: float64
The result is a series with labels as column names of the DataFrame. And, the Name of the series is the label with which it is retrieved.
Selection by integer location
Rows can be selected by passing integer location to an iloc function.
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df.iloc[2]
Its output is as follows −
one 3.0
two 3.0
Name: c, dtype: float64
Slice Rows切片行
Multiple rows can be selected using ‘ : ’ operator.
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print df[2:4]
Its output is as follows −
one two
c 3.0 3
d NaN 4
Addition of Rows
Add new rows to a DataFrame using the append function. This function will append the rows at the end.
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print df
Its output is as follows −
a b
0 1 2
1 3 4
0 5 6
1 7 8
Deletion of Rows
使用索引标签从 DataFrame 中删除或删除行。如果标签重复,则将删除多行。
如果您观察到,在上面的示例中,标签是重复的。让我们删除一个标签,看看有多少行会被删除。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
# Drop rows with label 0
df = df.drop(0)
print df
Its output is as follows −
a b
1 3 4
1 7 8
Series
series是一个一维标记数组,能够保存任何类型的数据(整数、字符串、浮点数、python 对象等)。摆针标签统称为索引。
pandas.Series
可以使用以下构造函数创建pandas Series -
pandas.Series( data, index, dtype, copy)
构造函数的参数如下
| Sr.No | Parameter & Description |
|---|---|
| 1 | data:数据采用各种形式,如 ndarray, list, constants |
| 2 | index:索引值必须唯一且可散列,与数据长度相同。如果没有传递索引,则默认为 np.arrange(n)。 |
| 3 | dtype:dtype 用于数据类型。如果没有,将推断数据类型 |
| 4 | copy复制数据。默认False |
可以使用各种输入创建一个系列,例如 -
- Array
- Dict
- Scalar value or constant(标量值或常数)
Create an Empty Series
A basic series,which can be created is an Empty Series.
Example
#import the pandas library and aliasing as pd
import pandas as pd
s = pd.Series()
print s
Its output is as follows −
Series([], dtype: float64)
Create a Series from ndarray
如果数据是 ndarray,则传递的索引必须具有相同的长度。如果没有传递索引,则默认索引将是 range(n),其中 n 是数组长度,即 [0,1,2,3....range(len(array))-1]。
Example 1
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data)
print s
Its output is as follows −
0 a
1 b
2 c
3 d
dtype: object
我们没有传递任何索引,因此默认情况下,它分配的索引范围为 0 到 len(data)-1,即 0 到 3。
Example 2
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data,index=[100,101,102,103])
print s
Its output is as follows −
100 a
101 b
102 c
103 d
dtype: object
我们在这里传递了索引值。现在我们可以在输出中看到自定义的索引值。
Create a Series from dict
可以将 dict 作为输入传递,如果未指定索引,则按排序顺序获取字典键以构造索引。如果传入 index ,则会拉出 index 中标签对应的 data 中的值。
Example 1
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data)
print s
Its output is as follows −
a 0.0
b 1.0
c 2.0
dtype: float64
Observe −字典键用于构造索引。
Example 2
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data,index=['b','c','d','a'])
print s
Its output is as follows −
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
Observe − 索引顺序保持不变,缺少的元素用 NaN(非数字)填充。
Create a Series from Scalar(标量)
如果数据是标量值,则必须提供索引。该值将重复以匹配索引的长度
#import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
s = pd.Series(5, index=[0, 1, 2, 3])
print s
Its output is as follows −
0 5
1 5
2 5
3 5
dtype: int64
Accessing Data from Series with Position(根据位置访问Series的数据)
Series 中的数据可以类似于 ndarray 中的数据进行访问。
Example 1
检索第一个元素。正如我们已经知道的,数组的计数从零开始,这意味着第一个元素存储在第零个位置,依此类推。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve the first element
print s[0]
Its output is as follows −
1
Example 2
检索系列中的前三个元素。如果在它前面插入 : ,将该索引前所有项目都将被提取。如果使用两个参数(它们之间有:),则检索两个索引之间的项目(不包括停止索引)
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve the first three element
print s[:3]
Its output is as follows −
a 1
b 2
c 3
dtype: int64
Example 3
检索最后三个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve the last three element
print s[-3:]
Its output is as follows −
c 3
d 4
e 5
dtype: int64
Retrieve Data Using Label (Index)【使用标签(索引)检索数据】
A Series 就像一个固定大小的字典,因为您可以通过索引标签获取和设置他的值。
Example 1
使用索引标签值检索单个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve a single element
print s['a']
Its output is as follows −
1
Example 2
使用索引标签值列表检索多个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve multiple elements
print s[['a','c','d']]
Its output is as follows −
a 1
c 3
d 4
dtype: int64
Example 3
如果不包含标签,则会引发异常。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
#retrieve multiple elements
print s['f']
Its output is as follows −
…
KeyError: 'f'
cpg 20210625 如有错误欢迎指正。
references