查询处理
1 概述
1.1 基本步骤
- 语法分析与翻译
- 优化
- 执行
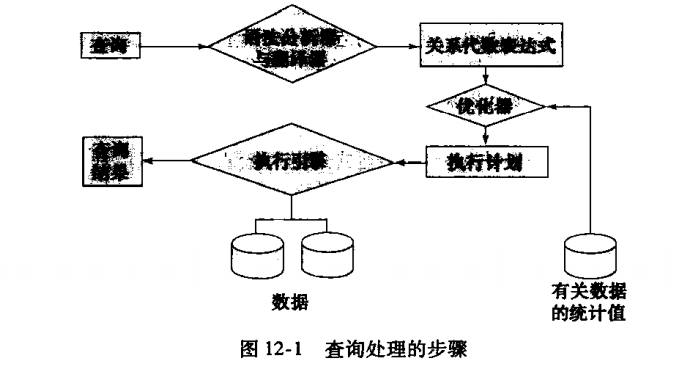
1.2 查询
一个查询,一般都会有多种计算结果的方法。
例如,select salary from instructor where salary<75000;
可以被翻译为以下任意一个关系代数表达式
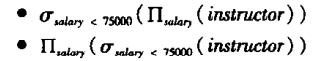
要全面说明如何执行一个查询,有以下概念:
- 计算原语(evaluation primitive):加了“如何执行”注释的关系代数运算
- 查询执行计划(query-execution plan):用于执行一个查询的原语操作序列,也成为查询计算计划(query-evaluation plan)
- 查询执行引擎(query-execution engine):接受一个查询执行计划,执行该计划并把结果返回给查询
给定查询的不同执行计划会有不同的代价,选择最高效率的查询计划就是查询优化,是系统的责任
2 查询代价的度量
主要度量:
- 传送磁盘块数
- 搜索磁盘次数
假设传输一个磁盘块的数据平均tr秒,磁盘访问时间(磁盘搜索加旋转延迟)ts秒,一次传输b个块以及执行S次磁盘搜索的时间为:
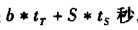
我们假定开始时的数据必须从磁盘中读出,但实际上可能已经被缓存过了。为了简化,忽略这种情况,所以实际代价可能小于估算代价
因此,很难估算计划的响应时间,原因如下:
- 查询开始执行时,响应时间依赖于缓存区内容;对查询进行优化时,该信息无法获取,即使获取了也很难进行计算
- 在具有多张磁盘的系统中,响应时间依赖于访问如何分布在各磁盘上,没有对分布在磁盘中的数据的详细了解很难估计
优化器通常努力去降低查询计划的资源消耗,而不是降低响应时间。因为总有一些方法可以以资源换时间,这对于单个查询是降低了响应时间,但如果多个查询同时执行,往往会提高响应时间。
3 选择运算
文件扫描(file scan)是存取数据最低级的操作
3.1 文件扫描和索引选择

3.2 复杂选择
有以下更复杂的选择谓词
-
合取 conjunction
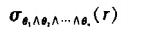
-
析取 disjunction
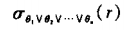
-
取反
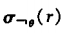
分别有以下算法
-
A7(利用一个索引的合取选择)
判断是否有某个属性上存在索引,若存在选择A2-A6中的一个来搜索满足条件的记录,然后在内存缓冲区中,通过测试检索到的记录是否满足其他条件,最终完成这个操作。由选择的θi组合决定。
-
A8(通过使用组合索引和合取选择)
可能使用组合索引,索引的类型决定使用A2、A3、A4中的哪一个
-
A9(通过标识符的交实现合取选择)
要求各个条件涉及的字段上带有记录指针的索引。对每个索引进行扫描,获取那些指向单个条件记录的指针,然后取交集。需要注意的是:
- 应该把指向一个磁盘块的指针放在一起,这样只需要一次磁盘IO就可以获取该磁盘块上的全部记录
- 要按存储次序执行,这样磁盘臂的移动最少
-
A10(通过标识符的并实现析取选择)
如果析取条件中均有带有记录指针的索引,可以类似A9。
否则直接线性扫描。(不然的话为了取一个条件也要线性扫描一次,不如直接扫描好了)
-
取反
线性扫描A1
4 排序
- 针对内存中能够完全容纳的情况
- 标准的排序算法,比如快排
- 针对不能被内存完全容纳的情况
- 本节介绍
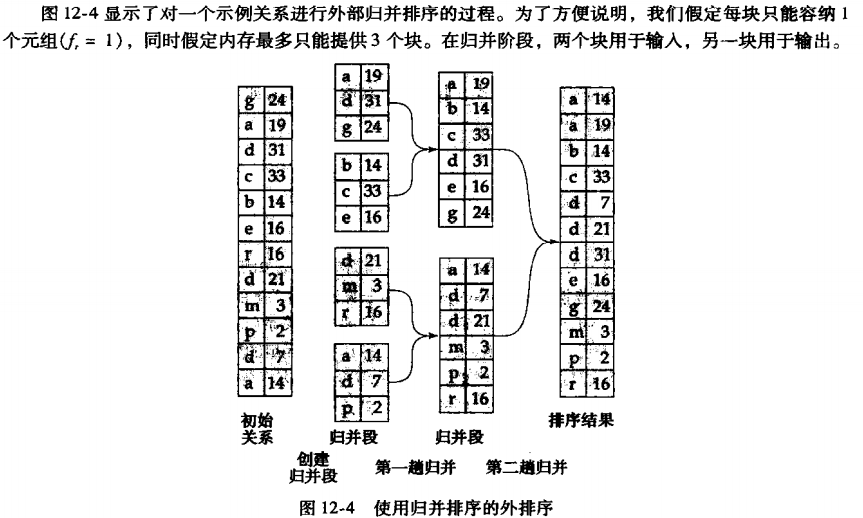
4.1 外部排序归并算法
对于不能完全放在内存中的关系进行排序,称为外排序(external sorting)。
其中最常用的技术是归并排序。
-
建立多个排好序的归并段(sorted run)
Repeatedly do the following till the end of the relation:
(a) Read M blocks of relation into memory
(b) Sort the in-memory blocks
(c) Write sorted data to run Ri ; increment i.
Let the final value of i be N
-
归并归并段
We assume (for now) that N < M.
(1)Use N blocks of memory to buffer input runs, and 1 block to buffer output. Read the first block of each run into its buffer page
(2)repeat
(2.1)Select the first record (in sort order) among all buffer pages
(2.2)Write the record to the output buffer. If the output buffer is full write it to disk.
(2.3)Delete the record from its input buffer page.( If the buffer page becomes empty then read the next block (if any) of the run into the buffer. )
(3)until all input buffer pages are empty:
注:如果N>M,就先排序M-1个段
4.2 算法分析


5 连接运算
5.1 嵌套循环连接

5.2 块嵌套循环连接

在最坏的情况下,对于外层关系中的每一个块,内层关系s的每一块只需要读一次,而不是对外层关系的每一个元组读一次。
5.3 索引嵌套循环连接
图12-5中,若在内层循环的连接属性上有索引,可以用索引替代文件扫描。对于外层关系r的每一个元组tr,可以利用索引查找s中和元组tr满足连接条件的元组。
5.4 归并连接
归并连接算法(merge join)又称排序-归并-连接算法(sort-merge join)
先排好序,然后

5.5 散列连接
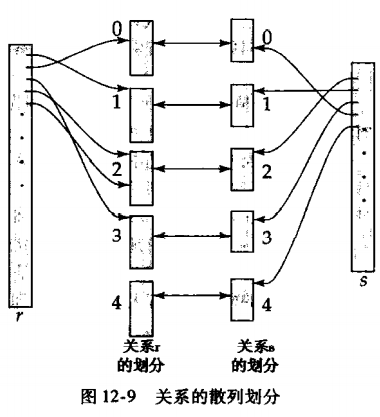

6 其他运算
6.1 去重
- 排序:排序时等值元素相互邻近,删除其他副本只留一个即可
- 散列
6.2 投影
- 首先对每个元素作投影
- 如果所得结果可能有重复,则去重。(若投影列表中属性含有关系的码,则不会有重复,不必去重)
6.3 集合运算

6.4 外连接
略
6.5 聚集
group by
- 可以用类似去重的方法实现
- 不必等聚集后再进行聚集运算,如sum、min、max、count、avg可以在过程中进行计算
7 表达式计算
目前为止,我们研究了单个关系运算如何执行,下面我们讨论如何计算包含多个运算的表达式。
一般来说有两种办法
- 以适当的顺序每次执行一个操作,每次计算的结果被物化到一个临时关系中以备后用。
- 在流水线上同时计算多个运算,一个运算的结果传递给下一个,不必保存临时关系。
7.1 物化
以该表达上为例
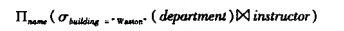
建立运算符树
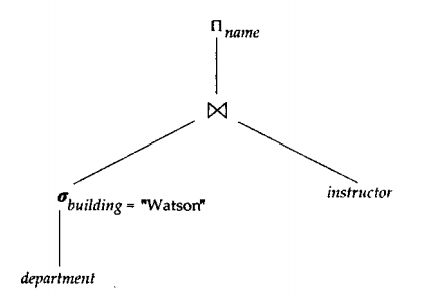
自底向上进行计算。物化的代价不仅仅是涉及的运算代价总和,还要加上将运算结果写到磁盘上的代价。
可以使用双缓冲,即一个缓冲区用于连续执行算法,一个缓冲区用于写出结果
7.2 流水线
好处:
- 消除读和写的临时关系代价,减少查询计算代价
- 如果一个查询计算计划的根操作符及其输入合并到流水线中,那么可以迅速开始产生查询结果
实现
-
需求驱动的流水线

-
生产者驱动的流水线
