IP层转发分组的流程
这篇文章我们一起来学习下IP层转发分组的流程。
首先用一个简单的例子来说明路由器是怎样转发分组的,如下图所示:
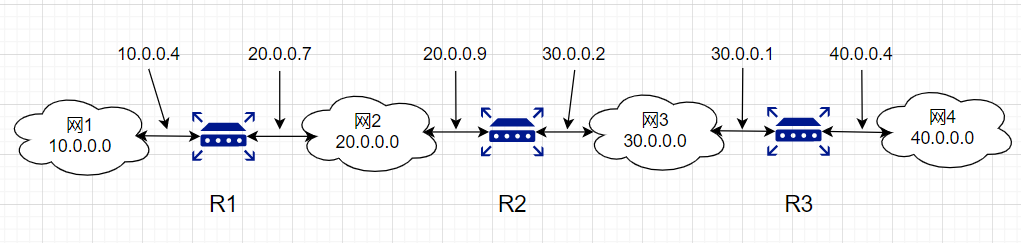
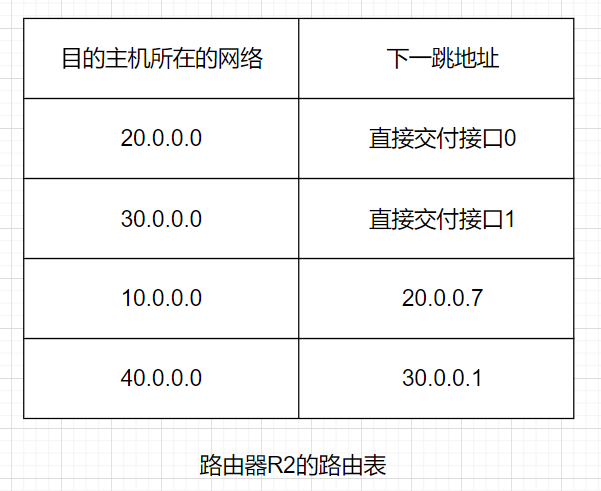
有4个A类网络通过三个路由器连接在一起,每一个网络上都可能有成千上万台主机。若路由表指出每一台主机应怎样转发,则路由表就会过于庞大(假设每一个网络有一万台主机,四个网络就有4万台主机,因而每一个路由表就有4万行),但若路由表指出到某个网络应如何转发,则每个路由器中的路由表就只包含4行,一行对应一个网络。以路由器R2的路由表为例,由于R2同时连接在网络2和网络3上,因此只要目的主机在网络2或网络3上,都可通过接口0或1由路由器R2直接交付(还要利用ARP协议找到主机硬件地址)。若目的主机在网络1中,则下一跳路由器应为R1,其IP地址为20.0.0.7。路由器R2和R1由于同时连接在网络2上,因此路由器R2把分组转发到路由器R1是很容易的。同理,若目的主机在网络4中,则路由器R2应把分组转发给IP地址为30.0.0.1的路由器R3(注意:每一个路由器都有2个不同的IP地址)。
可以把整个的网络拓扑简化为下图所示:
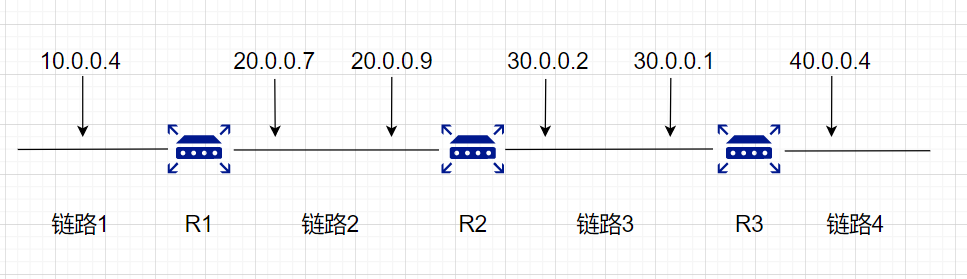
网络变成了一条链路,但每一个路由器都注明其IP地址。使用这样的简化图,可以使我们不必关心某个网络内部的具体拓扑以及连接在该网络上有多少台主机,这样的图强调了在互联网上转发分组时,是从一个路由器转发到下一个路由器。
在路由表中,每一条路由最主要的是以下两个信息:
- 目的网络地址
- 下一跳地址
根据目的网络地址来确定下一跳路由器,这样做可得到以下的结果:
- IP数据报最终一定可以找到目的主机所在网络上的路由器
- 只有到达最后一个路由器时,才试图向目的主机进行直接交付
在IP数据报的首部中,没有地方可以用来指明“下一跳路由器的IP地址”,在IP数据报的首部写上的IP地址是源IP地址和目的IP地址,而没有中间经过的路由器的IP地址。既然IP数据报中没有下一跳路由器的IP地址,那么待转发的数据报又怎样能够找到下一跳路由器呢?当路由器收到一个待转发的数据报,从路由表得出下一跳路由器的IP地址后,不是把这个地址填入IP数据报,而是送交数据链路层的网络接口软件。网络接口软件负责把下一跳路由器的IP地址转换成硬件地址(使用ARP协议),并将此硬件地址放在链路层的MAC帧的首部,然后根据这个硬件地址找到下一跳路由器。由此可见,当发送一连串的数据报时,上述的这种查找路由表、用ARP得到硬件地址、把硬件地址写入MAC帧的首部等过程,将不断重复进行。
下面总结下分组转发算法:
- 从数据报的首部提取出目的主机的IP地址D,得出目的网络地址为N
- 若N就是与此路由器直接相连的某个网络地址,则直接交付,即不需要再经过其它的路由器,直接把数据报交付目的主机(把目的主机地址D转换为硬件地址,把数据报封装为MAC帧,再发送此帧);否则就间接交付,执行下一步
- 若路由表中有目的地址为D的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器,否则,执行下一步
- 若路由表中有到达网络N的路由,则把数据报传送给路由表中所指明的下一跳路由器,否则,执行下一步
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器,否则,执行下一步
- 报告转发分组错误
路由表并没有给分组指明到某个网络的完整路径,即先经过哪一个路由器,然后再经过哪一个路由器等等。路由表指出,到某个网络应当先到某个路由器,在到达下一跳路由器后,继续查找路由表,知道下一步应当到哪一个路由器。这样一步一步的查找下去,直到最后到达目的网络。就好比我们去某个目的地,但没有地图,只能在每个岔路问路,路人仅指出下一段路如何走,到了下一个岔路,我们继续问路,如此往复。即使没有地图,但最终一定可以到达目的地。
在进一步讨论路由选择之前,我们还要先介绍划分子网和构造超网这两个非常重要的概念。
划分子网
三级IP地址
今天来看,在ARPANET的早期,IP地址的设计不够合理:
-
IP地址空间的利用率有时很低
每一个A类地址网络可连接的主机数超过1000万,而每一个B类地址网络可连接的主机数也超过6万。有的单位申请到了一个B类地址网络,但所连接的主机数并不多,又不愿意申请一个足够使用的C类地址。IP地址的浪费,还会使IP地址空间资源过早被用完。 -
给每一个物理网络分配一个网络号会使路由表变的太大而使网络性能变坏
每一个路由器都应当能够从路由表查出应怎样到达其它网络的下一跳路由器,当互联网中的网络数越多,路由器的路由表的项目数也就越多。这样,即使我们拥有足够多的IP地址资源可以给每一个物理网络分配一个网络号,也会导致路由器的路由表中的项目数过多。这不仅增加了路由器的成本(更多存储空间),而且查找路由会耗费更多的时间,同时也使路由器之间定期交换的路由信息急剧增加,因而使得路由器和互联网的性能下降。 -
两级IP地址不够灵活
有时情况紧急,一个单位需要在新的地点马上开通一个新的网络。但是在申请到一个新的IP地址之前,新增加的网络是不可能连接到互联网上工作的。
为了解决以上问题,从1985年起,IP地址中增加了一个“子网号字段”,使两级IP地址变成三级IP地址。这种做法叫做划分子网,它的基本思路如下:
(1)一个拥有许多物理网络的单位,可将所属的物理网络划分为若干个子网(subnet)。划分子网纯属一个单位内部的事情,本单位以外的网络看不见这个网络是由多少个子网组成,因为这个单位对外仍然表现为一个网络。
(2)划分子网的方法是从网络的主机号借用若干位作为子网号(subnet-id),当然主机号也就相应减少了同样的位数。
(3)凡是从其它网络发送给本单位某台主机的IP数据报,仍然是根据IP数据报的目的网络号找到连接在本单位网络上的路由器。但此路由器在收到IP数据报后,再按目的网络号和子网号找到目的子网,把IP数据报交付目的主机。
下面用例子说明划分子网的概念:
某单位拥有一个B类IP地址,网络地址是145.13.0.0(网络号是145.13)。凡目的地址为145.13.x.x的数据报都被送到这个网络上的路由器R1。

现在把上图所示的网络划分为三个子网,假定子网号占用8位,那么此时主机号就只有8位。所划分的三个子网分别是145.13.3.0、145.13.7.0、145.13.21.0。在划分子网后,整个网络对外部仍表现为一个网络,其网络地址为145.13.0.0,但网络145.13.0.0上的路由器R1在收到外来的数据报后,再根据数据报的目的地址把它转发到相应的子网。

子网掩码
假定有一个数据报已经到达了路由器R1(145.13.3.10),那么这个路由器如何把它转发到子网145.13.3.0呢?
从IP数据报的首部无法看出源主机或目的主机所连接的网络是否进行了子网划分。因为IP地址本身及数据报的首部都没有包含任何有关子网划分的信息,必须另外想办法,这就是子网掩码。如下图所示:

为了使路由器R1能够很方便的从数据报中的目的IP地址中提取出所要找的子网的网络地址,路由器R1就要使用三级IP地址的子网掩码。将数据报的目的IP地址和子网掩码进行“与”运算,就可得到子网的网络地址。从网络外面看,这就是一个普通的B类网络,但进入到这个网络后(进入路由器R1),就看到了还有许多网络(子网)。
现在的互联网标准规定:所有的网络都必须使用子网掩码,同时在路由器的路由表中也必须有子网掩码这一栏。如果一个网络不划分子网,那么该网络的子网掩码就使用默认子网掩码,如下:
- A类地址默认子网掩码:255.0.0.0
- B类地址默认子网掩码:255.255.0.0
- C类地址默认子网掩码:255.255.255.0
子网掩码是一个网络或一个子网的重要属性,路由器在和相邻路由器交换路由信息时,必须把自己所在网络(或子网)的子网掩码告诉相邻路由器。在路由器的路由表中的每一个项目,除了要给出目的网络地址外,还必须同时给出该网络的子网掩码。若一个路由器连接在两个子网上,就拥有两个网络地址和两个子网掩码。
划分子网增加了灵活性,但却减少了能够连接在网络上的主机数。
使用子网时分组的转发
在划分子网后,分组转发的算法必须做相应的改动。
使用子网划分后,路由表必须包含以下三项内容:目的网络地址、子网掩码、下一跳地址,此时转发分组算法如下:
- 从收到的数据报的首部提取目的IP地址D
- 判断是否直接交付,对路由器直接相连的网络逐个进行检查:用各网络的子网掩码和D进行“与”运算,看结果是否和网络地址匹配。若匹配,则直接交付分组(把D转换为物理地址,把数据报封装成帧发送出去),否则间接交付,执行下一步
- 若路由表有目的地址为D的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器,否则执行下一步
- 对路由表中的每一行,用其中的子网掩码和D进行“与”运算,其结果为N。若N与该行的目的网络地址匹配,则把数据报传送给该行指明的下一跳路由器,否则执行下一步
- 若路由表中有一个默认路由,则把数据报传送给路由表所指明的默认路由器,否则执行下一步
- 报告转发分组出错
无分类编址CIDR(构造超网)
划分子网在一定程度上缓解了互联网在发展中遇到的困难,然而在1992年,互联网仍然面临三个必须尽早解决的问题,这就是:
(1)B类地址在1992年已分配了一半,眼看很快就将全部分配完毕
(2)互联网主干网上的路由表中的项目数急剧增长(从几千个增长到几万个)
(3)整个IPv4的地址空间最终将全部耗尽(2011年2月3日,IANA宣布IPv4地址耗尽)
IETF研究出无分类编址的方法来解决前两个问题,它的正式名字是无分类域间路由选择CIDR(Classless Inter-Domain Routing),有两个主要的特点:
(1)它消除了传统的A类、B类、C类地址以及划分子网的概念。它把32位的IP地址划分为前后两个部分,前面部分是网络前缀,用来指明网络,后面部分用来主机。因此,CIDR使IP地址从三级编址又回到了两级编址,它使用斜线记法,在IP地址后面加上斜线“/”,写上网络前缀所占的位数。
(2)CIDR把网络前缀都相同的连续的IP地址组成一个“CIDR地址块”,只要知道CIDR地址块中的任何一个地址,就可以知道这个地址块的起始地址(最小地址),最大地址,以及地址块中的地址数。
当然,主机号全0和全1的地址,一般并不使用。为了方便进行路由选择,CIDR使用32位的地址掩码,它由一串1和一串0组成,1的个数就是网络前缀的长度。虽然CIDR不使用子网,但由于目前仍有一些网络还使用子网划分和子网掩码,因此CIDR使用的地址掩码也可继续称为子网掩码。CIDR不使用子网的的意思是:CIDR并没有在32位地址中指明若干位作为子网字段,但分配到一个CIDR地址块的单位,仍然可以在本单位内根据需要划分出一些子网。这些子网也都只有一个网络前缀和主机号字段,但子网的网络前缀比整个单位的网络前缀要长些。例如,某单位分配到地址块/20,就可以再继续划分为8个子网(从主机号借用3位来划分子网)。这时每一个子网的网络前缀就变成23位。
由于一个CIDR地址块有很多地址,所以在路由表中就利用CIDR地址块来查找目的网络。这种地址的聚合常称为路由聚合,它使得路由表中的一个项目可以表示原来传统分类地址的很多个路由,减少了路由器之间路由选择信息的交换,提高了互联网的性能。路由聚合也称为构成超网。
最长路径匹配
在使用CIDR时,路由器中的每一行由“网络前缀”和“下一跳地址”组成。但是,在查找路由表时可能会得到不止一个匹配结果,这样就带来一个问题:应当从匹配的结果中选择哪一条路由呢?答案是:选择具有最长网络前缀的路由,这叫做最长前缀匹配,因为网络前缀越长,地址块就越小,路由就越具体。
使用二叉线索查找路由表
因为要寻找最长前缀的路由,所以使得路由表的查找过程变得更加复杂了。当路由表的项目数很大时,怎样设法减小路由表的查找时间就成为一个非常重要的问题,路由表中必须使用很好的数据结构以及先进的快速查找算法。
对于无分类编址的路由表的最简单的查找算法是:对所有可能的前缀进行循环查找。例如:给定一个目的地址D,对每一个可能的网络前缀长度M,路由器从D中提取出M个位的网络前缀,查找路由表中的网络前缀,所找到的最长匹配就对应于要查找的路由。这种算法的明显缺点是查找的次数太多。为了进行更加有效的查找,通常是把无分类编址的路由表存放在一种层次的数据结构中,然后自上而下的按层次进行查找,最常用的就是二叉线索。下面用一个例子说明二叉线索的结构。
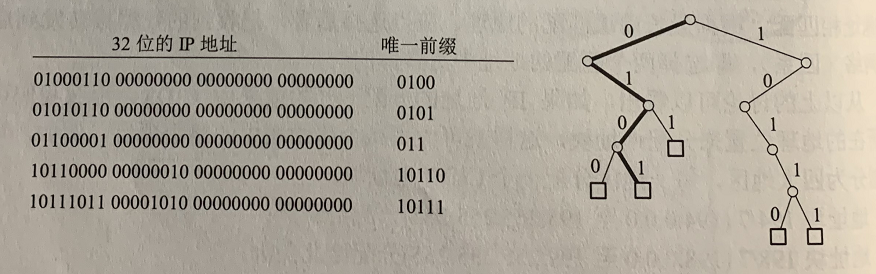
为了简化二叉线索的结构,可以先找出对应于每一个IP地址的唯一前缀。所谓唯一前缀就是:在表中所有的IP地址中,该前缀是唯一的。在进行查找时,只要能够和唯一前缀相匹配就行了。从二叉线索的根节点自顶向下的深度最多有32层,每一层对应于IP地址中的一位。一个IP地址存入二叉线索的规则很简单,先检查IP地址左边的第一位,如为0,则第一层的节点就在根节点的左下方,如为1,则在右下方,再检查地址的第二位,构造出第二层的节点,依次类推,直到唯一前缀的最后一位。