(一)YOLO——————将分类问题视为一个单一的回归问题,直接从图片中得到边界框坐标和分类可能性
论文地址:https://arxiv.org/abs/1506.02640
官方代码地址:http://pjreddie.com/yolo/
(先前的工作:重新定义分类器执行检测)
1.思想
我们将目标检测作为一个回归问题,应用于空间分离的边界框和相关的类概率。在一次评估中,单个神经网络直接从完整的图像中预测边界框和类概率。由于整个检测管道是一个单一的网络,可以直接对检测性能进行端到端优化。
2.检测过程
(1)调整输入图片大小为448*448
(2)在图片上运行单一的卷积网络
(3)选取满足模型置信度的检测结果(非极大值抑制)
将输入的图片分成S*S的网格——>如果目标的中心落在方格中,则该方格负责检测该目标——>每个方格预测B个bbox(x,y,w,h)以及这些bbox的置信度分数(confidence)——>对于每张图片输出S*S*(B*5+C)。
(x,y)代表bbox的中心(相对于网格的边界);(w,h)代表整个图片的宽和高
框的置信度confidence: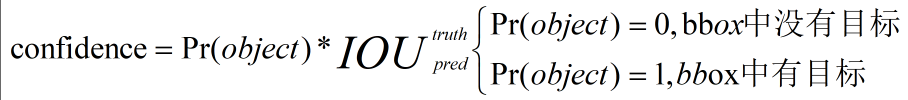
具体类的置信度C;
小问题:每一个网格,怎么可以只预测一个class probabilities,是只预测一次就是对的嘛?
3.网络结构
(初始化的卷积层负责从整张图片中提取特征,全连接层负责输出类可能性(c)和框的坐标(x,y,w,h))

注:
基础网络为GoogLenet,使用1*1和3*3的卷积层代替了GoogLenet中的inception modules
Fast YOLO使用了9个卷积层和2个全连接层
4. 训练
预训练模型
ImageNet 1000-class competition das
3.损失函数
平方和误差——容易优化,但是并不符合最大化平均精度的目标
出现的问题:
1.定位误差和分类误差相等的加权,这可能并不理想。而且,在每个图像中,许多网格单元不包含任何对象。 这将这些单元格的“置信度”分数推向零,通常会压制包含对象的单元格的渐变。 这可能导致模型不稳定,导致训练早期出现分歧。
解决;
增加定位误差的权重,降低不含有目标的框的置信度损失
2.大的框和小的框具有相等的权重,我们的误差度量应该反映出大盒子里的小偏差比小盒子里的小偏差更重要。
解决:
为了部分解决这个问题,我们预测边界框的宽度和高度的平方根,而不是直接预测宽度和高度

4.优点:
(1)速度快————将检测作为回归问题,不需要复杂的管道(pipeline)
(2)从全局角度对图片进行预测,背景误检率低————隐含的编码了类的上下文信息和外观
(3)学习对象的一般表示,有很高的通用性,当有新域名或者意外输入时,不太可能发生故障。在对自然图像进行训练并对艺术作品进行测试时,YOLO优于DPM等顶级检测方法。
5.缺点:
(1)会产生更多的定位错误(准确率低,尤其是小目标)
(2)召回率低
6.实验结果
base_YOLO 45fps TitanX(GPU)
Fast_YOLO 155fps TitanX(GPU)
(处理实时的流媒体视频延时小于25ms)