总结下工作中常用的推荐算法
1.基于内容的推荐算法(简单)
2.基于用户的推荐算法(简单)
3.协同过滤推荐算法(相对复杂)
第一种和第二中算法的基础在于标签体系质量情况。第三种需要对用户的行为进行大规模的收集,取决于埋点质量情况。
1.基于内容的推荐算法:
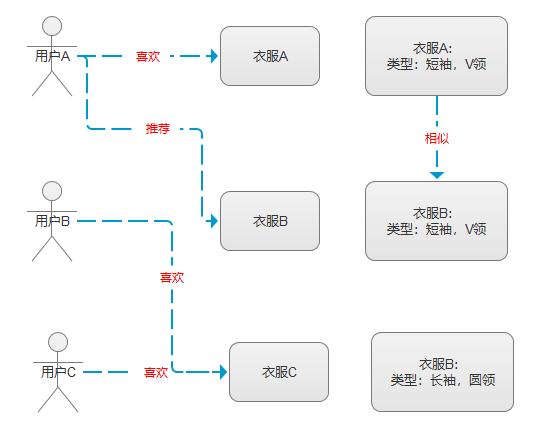
2.基于用户的推荐算法:
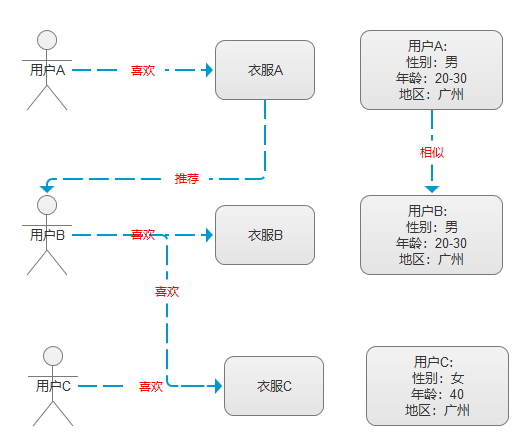
3.协同过滤推荐算法:
实现协同过滤的步骤
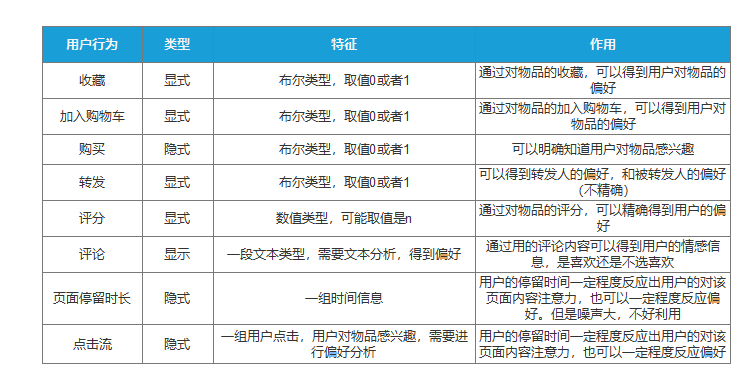
1、收集用户偏好
2、数据清洗
3、找到相似的用户或物品
4、计算推荐
3.1收集用户偏好:
例如:
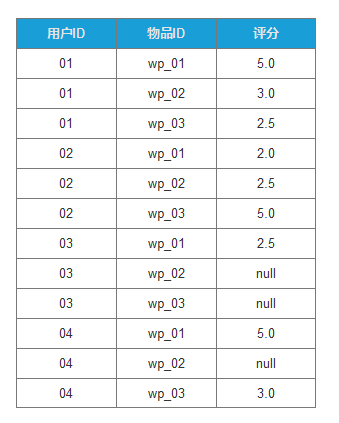
假设我们选区评分作为计算偏好如下表:
每行3个字段,依次是用户ID,物品ID,用户对物品的评分(0-5分,间隔为0.5分)
3.2计算相似性
根据用户,物品,评分,计算出什么人喜欢什么,以及程度
相似性的度量计算方式有下列几种(包括但不限):
1.欧氏距离相似度
2.皮尔森相似度
3.余弦相似度
4.曼哈顿距离相似度
3.2.1假设本次取“欧式距离”计算,计算如下:

3.2.2当得到欧式距离后,我们使用欧式距离相似度计算公式:
S(相似度)= 1 / p(欧式距离) +1
当p越小的时候(也就是距离越小的时候),S越大,说明相似度越高
3.3我们根据上诉计算方式得到如下表格:
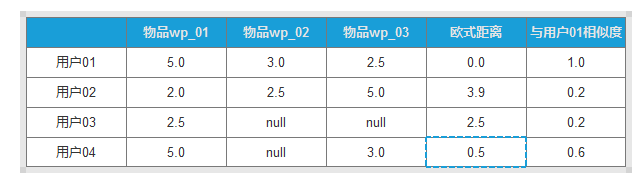
结论:
可以看到,当最后一列相似度的数值越大,说明与用户01的相似度越高。
所以我们相向用户04推荐物品wp_02商品