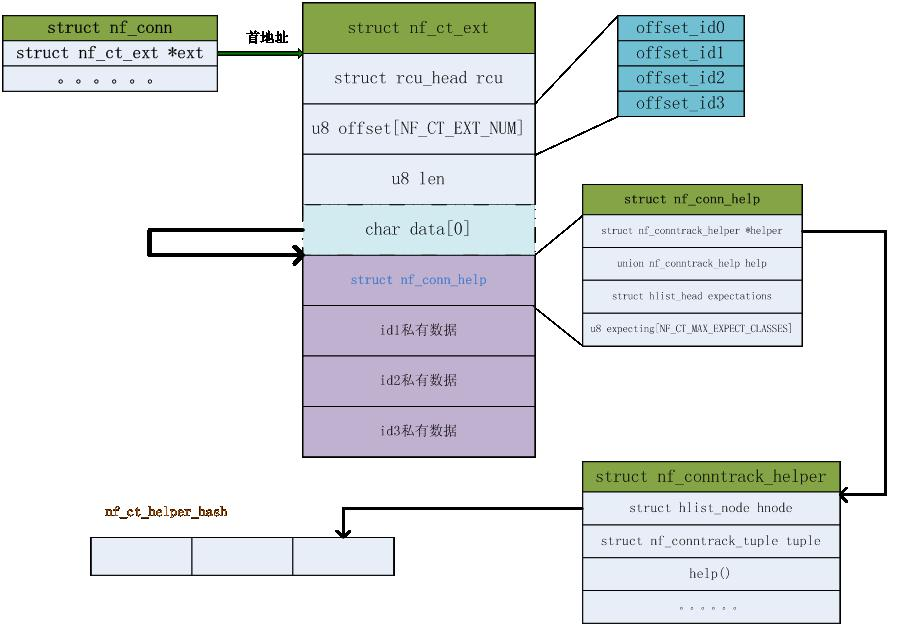
/* 需要对conntrack进行功能扩展的协议,会初始化一个struct nf_conntrack_helper 实例,把该实例注册到Netfilter中管理的全局哈希表中。 查找helper使用的hash 算法 static unsigned int helper_hash(const struct nf_conntrack_tuple *tuple) { return (((tuple->src.l3num << 8) | tuple->dst.protonum) ^ (__force __u16)tuple->src.u.all) % nf_ct_helper_hsize; } 查找时使用的L3协议类型,L4协议类型及L4协议的源端口三元组信息来查找的helper。因为识别不同的L5协议一般都是通过这三元组来识别的。 注册helper实例 Netfilter中定义了一个哈希表来管理和存储不同协议注册的helper实例。 static struct hlist_head *nf_ct_helper_hash __read_mostly; 注意nf_conn_help 和 nf_conntrack_helper的区别 */
int nf_conntrack_helper_register(struct nf_conntrack_helper *me) { struct nf_conntrack_tuple_mask mask = { .src.u.all = htons(0xFFFF) }; unsigned int h = helper_hash(&me->tuple); struct nf_conntrack_helper *cur; int ret = 0; BUG_ON(me->expect_policy == NULL); BUG_ON(me->expect_class_max >= NF_CT_MAX_EXPECT_CLASSES); BUG_ON(strlen(me->name) > NF_CT_HELPER_NAME_LEN - 1); mutex_lock(&nf_ct_helper_mutex); hlist_for_each_entry(cur, &nf_ct_helper_hash[h], hnode) { if (nf_ct_tuple_src_mask_cmp(&cur->tuple, &me->tuple, &mask)) { ret = -EEXIST; goto out; } } hlist_add_head_rcu(&me->hnode, &nf_ct_helper_hash[h]); nf_ct_helper_count++; out: mutex_unlock(&nf_ct_helper_mutex); return ret; }
conntrack关联相关的helper处理时是在:
init_conntrack --{
if (!exp) {// 如果不存在 从新赋值 ct->ext->...->help->helper = helper
__nf_ct_try_assign_helper(ct, tmpl, GFP_ATOMIC);
NF_CT_STAT_INC(net, new);
}
}
看下tftp的例子:
struct nf_conntrack_helper { struct hlist_node hnode; /* Internal use. */ //helper的名字,iptables扩展match helper会使用 char name[NF_CT_HELPER_NAME_LEN]; /* name of the module */ struct module *me; /* pointer to self */ //协议的期望连接的策略参数,包括最大期望连接数及最大连接超时时间*/ const struct nf_conntrack_expect_policy *expect_policy; /* length of internal data, ie. sizeof(struct nf_ct_*_master) */ size_t data_len; //元组信息,表示不同协议的helper,使用该元组的一些字段来在Netfilter中查找helper /* Tuple of things we will help (compared against server response) */ struct nf_conntrack_tuple tuple; /* Function to call when data passes; return verdict, or -1 to invalidate. *///不同协议自己实现自己的helper处理函数 int (*help)(struct sk_buff *skb, unsigned int protoff, struct nf_conn *ct, enum ip_conntrack_info conntrackinfo); void (*destroy)(struct nf_conn *ct); int (*from_nlattr)(struct nlattr *attr, struct nf_conn *ct); int (*to_nlattr)(struct sk_buff *skb, const struct nf_conn *ct); unsigned int expect_class_max; unsigned int flags; unsigned int queue_num; /* For user-space helpers. */ };
static const struct nf_conntrack_expect_policy tftp_exp_policy = { .max_expected = 1, .timeout = 5 * 60, }; static void nf_conntrack_tftp_fini(void) { int i, j; for (i = 0; i < ports_c; i++) { for (j = 0; j < 2; j++) nf_conntrack_helper_unregister(&tftp[i][j]); } } /* list add struct nf_conntrack_helper add nf_ct_helper_hash */ /* tftp[i][0].tuple.src.l3num = AF_INET; tuple.dst.protonum = IPPROTO_UDP; uple.src.u.udp.port = htons(ports[i]); help = tftp_help; */ static int __init nf_conntrack_tftp_init(void) { int i, j, ret; if (ports_c == 0) ports[ports_c++] = TFTP_PORT; for (i = 0; i < ports_c; i++) { memset(&tftp[i], 0, sizeof(tftp[i])); tftp[i][0].tuple.src.l3num = AF_INET; tftp[i][1].tuple.src.l3num = AF_INET6; for (j = 0; j < 2; j++) { tftp[i][j].tuple.dst.protonum = IPPROTO_UDP; tftp[i][j].tuple.src.u.udp.port = htons(ports[i]); tftp[i][j].expect_policy = &tftp_exp_policy; tftp[i][j].me = THIS_MODULE; tftp[i][j].help = tftp_help; if (ports[i] == TFTP_PORT) sprintf(tftp[i][j].name, "tftp"); else sprintf(tftp[i][j].name, "tftp-%u", i); ret = nf_conntrack_helper_register(&tftp[i][j]); if (ret) { pr_err("failed to register helper for pf: %u port: %u ", tftp[i][j].tuple.src.l3num, ports[i]); ports_c = i; nf_conntrack_tftp_fini(); return ret; } } } return 0; } /*/在init函数中对nf_conntrack_helper结构体的tuple进行了部分初始化,由于tftp数据包的协议和port是固定的,
同时注册了help函数为tftp_help(),函数定义如下,----------,参数skb是当前处理的数据包,ct是相应的conntrack,处理tftp read/write request的时候会进入这个函数。 */
/* 函数主要做了两件事情,首先初始化了一个ip_conntrack_expect结构,并将conntrack中应答方向的tuple结构附值给exp-〉tuple,然后调用:ip_conntrack_expect_related(exp, ct) 将这个expect结构与当前的连接状态关联起来,并把它注册到一个专门组织expect结构的全局链表ip_conntrack_expect_list里。 expect结构有什么用呢?当有返回的数据包时,首先仍然是搜索hash表,如果找不到可以匹配的连接,还会在全局链表里搜索匹配的expect结构,然后找到相关的连接状态。 为什么要这样做呢?假设有主机A向主机B发送消息,如下 A(10.10.10.1:1001) ——> B(10.10.10.2:69) 从A的1001端口发往B的69端口,连接跟踪模块跟踪并记录了次条连接,保存在一个ip_conntrack结构里(用tuple来识别),但是我们知道,一个连接有两个方向,我们怎么确定两个方向相反的数据包是属于同一个连接的呢?最简单的判断方法就是将地址和端口号倒过来,就是说如果有下面的数据包: B(10.10.10.2:69)——> A(10.10.10.1:1001) 虽然源/目的端口/地址全都不一样,不能匹配初始数据包的tuple,但是与对应的repl_tuple完全匹配,所以显然应该是同一个连接,所以见到这样的数据包时就可以直接确定其所属的连接了,当然不需要什么expect 然而不是所有协议都这么简单, 对于tftp协议,相应的数据包可能是 B(10.10.10.2:1002)——> A(10.10.10.1:1001) 并不完全颠倒,就是说不能直接匹配初始数据包的tuple的反防向的repl_tuple,在hash表里找不到对应的节点,但我们仍然认为它和前面第一条消息有密切的联系,甚至我们可以明确,将所有下面形式的数据包都归属于这一连接的相关连接 B(10.10.10.2:XXX)——> A(10.10.10.1:1001) 怎么实现这一想法呢,只好再多创建一个expect了,它的tuple结构和repl_tuple完全相同,只是在mask中将源端口位置0,就是说不比较这一项,只要其他项匹配就OK。 (注意一下,ip_conntrack_expect结构里有个mask,ip_conntrack_helper里也有个mask,即使是同一个连接,它们的值也是不一样的。) 以上就是helper和expect的作用了,但是具体的实现方法还跟协议有关,像ftp的连接跟踪就相当复杂。 从help函数返回后,连接跟踪的第一阶段就结束了。 */ static int tftp_help(struct sk_buff *skb, unsigned int protoff, struct nf_conn *ct, enum ip_conntrack_info ctinfo) { const struct tftphdr *tfh; struct tftphdr _tftph; struct nf_conntrack_expect *exp; struct nf_conntrack_tuple *tuple; unsigned int ret = NF_ACCEPT; typeof(nf_nat_tftp_hook) nf_nat_tftp; tfh = skb_header_pointer(skb, protoff + sizeof(struct udphdr), sizeof(_tftph), &_tftph); if (tfh == NULL) return NF_ACCEPT; switch (ntohs(tfh->opcode)) { case TFTP_OPCODE_READ: case TFTP_OPCODE_WRITE: /* 在nf_ct_expect_cachep上分配一个expect连接,同时赋两个值: exp->master = ct, exp->use = 1。 */ /* RRQ and WRQ works the same way
ORGINAL :A(10.10.10.1:1001) ——> B(10.10.10.2:69)
REPLY B(10.10.10.2:69)——> A(10.10.10.1:1001)
生成的expect为:
ORGINAL tuple: A(10.10.10.1:0) ——> B(10.10.10.2:69)
exp->master = ct。注意,expect只有一个tuple,即只有一个方向,
这里只看到ORIGNAL方向的tuple,只是因为tuple的dir没赋值,默认为0。
*/ nf_ct_dump_tuple(&ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple); nf_ct_dump_tuple(&ct->tuplehash[IP_CT_DIR_REPLY].tuple); exp = nf_ct_expect_alloc(ct);//exp->master = ct; if (exp == NULL) { nf_ct_helper_log(skb, ct, "cannot alloc expectation"); return NF_DROP; } /* 根据ct初始化expect */ tuple = &ct->tuplehash[IP_CT_DIR_REPLY].tuple; /*初始化expect exp->class=NF_CT_EXPECT_CLASS_DEFAULT*/ nf_ct_expect_init(exp, NF_CT_EXPECT_CLASS_DEFAULT, nf_ct_l3num(ct), &tuple->src.u3, &tuple->dst.u3, IPPROTO_UDP, NULL, &tuple->dst.u.udp.port); pr_debug("expect: "); nf_ct_dump_tuple(&exp->tuple); nf_nat_tftp = rcu_dereference(nf_nat_tftp_hook); /* 数据包需要走NAT时,if成立,局域网传输则else成立。 */ if (nf_nat_tftp && ct->status & IPS_NAT_MASK)
//*如果ct做了NAT,就调用nf_nat_tftp指向的函数,这里它指向nf_nat_tftp.c中的help()函数。*/ ret = nf_nat_tftp(skb, ctinfo, exp);//如果ct做了NAT,就调用nf_nat_tftp指向的函数,这里它指向nf_nat_tftp.c中的help()函数 else if (nf_ct_expect_related(exp) != 0) {//调用nf_ct_expect_insert 插入 nf_ct_expect_hash 同时ct.expect_count++ nf_ct_helper_log(skb, ct, "cannot add expectation"); ret = NF_DROP; } nf_ct_expect_put(exp); break; case TFTP_OPCODE_DATA: case TFTP_OPCODE_ACK: pr_debug("Data/ACK opcode "); break; case TFTP_OPCODE_ERROR: pr_debug("Error opcode "); break; default: pr_debug("Unknown opcode "); } return ret; } /* 首先仍然是获取协议信息 proto = ip_ct_find_proto((*pskb)->nh.iph->protocol); 然后调用resolve_normal_ct() ct = resolve_normal_ct(*pskb, proto,&set_reply,hooknum,&ctinfo) 在resolve_normal_ct函数内部, get_tuple(skb->nh.iph, skb, skb->nh.iph->ihl*4, &tuple, proto) 然后查找hash表 h = ip_conntrack_find_get(&tuple, NULL) 这时候,还是举刚才的例子,如果之前曾有这样的数据包通过: A(10.10.10.1:1001) ——> B(10.10.10.2:69) 那么相应的连接状态应该已经建立了,这时候如果有完全相反的数据包 B(10.10.10.2:69) ——> A(10.10.10.1:1001) 那么在搜索hash表的时候就能顺利找到对应的连接,找到以后就简单了 skb->nfct = &h->ctrack->infos[*ctinfo] 将连接状态附值给nfct位,接下来就没什么特别的事情要做了,设置几个标志位,检查一下数据包等等 我们主要关心的还是这样的情况,如果后续的数据包是这样的: B(10.10.10.2:1002) ——> A(10.10.10.1:1001) 那么程序执行到ip_conntrack_find_get处时,会发现在hash表里找不到与当前数据包相匹配的连接,于是还是调用init_conntrack()创建连接 接下来的部分都和初始连接一样,计算hash值,初始化一个ip_conntrack等等,直到: expected = LIST_FIND(&ip_conntrack_expect_list, expect_cmp, struct ip_conntrack_expect *, tuple) 之前注册的expect被找到了,找到以后,进行下面的操作 if (expected) { DEBUGP("conntrack: expectation arrives ct=%p exp=%p ", conntrack, expected); /* 设置状态位为IPS_EXPECTED_BIT,当前的连接是一个预期的连接 */ __set_bit(IPS_EXPECTED_BIT, &conntrack->status); /* conntrack的master位指向搜索到的expected,而expected的sibling位指向conntrack……..解释一下, 这时候有两个conntrack,一个是一开始的初始连接(比如69端口的那个)也就是主连接conntrack1, 一个是现在正在处理的连接(1002)子连接conntrack2,两者和expect的关系是: 1. expect的sibling指向conntrack2,而expectant指向conntrack1, 2. 一个主连接conntrack1可以有若干个expect(int expecting表示当前数量),这些 expect也用一个链表组织,conntrack1中的struct list_head sibling_list就是该 链表的头。 3. 一个子连接只有一个主连接,conntrack2的struct ip_conntrack_expect *master 指向expect 通过一个中间结构expect将主连接和子连接关联起来 */ conntrack->master = expected; expected->sibling = conntrack; /* 将此连接从预期连接全局链表里删除(只是从全局链表里删除,但连接本身还在),因为此连接即将被正式添加到全局的连接表里, 所以下次如果再有B(10.10.10.2:1002) ——> A(10.10.10.1:1001)这样的数据包,就能直接从hash表里找到了,不必再借用expect。 因此主连接中的预期连接数expecting也自动减1 LIST_DELETE(&ip_conntrack_expect_list, expected); expected->expectant->expecting--; nf_conntrack_get(&master_ct(conntrack)->infos[0]); } 接下来,如果expect里的expectfn函数有定义的话就执行它(一般是没有的) if (expected && expected->expectfn) expected->expectfn(conntrack); 后面的过程略去了,和之前差不多 */
1/ 根据数据包的ct初始化一个expect连接;tftp请求(读或写)只能从client到server
static int nf_ct_expect_insert(struct nf_conntrack_expect *exp) { /* 获得exp->master的help */ struct nf_conn_help *master_help = nfct_help(exp->master); struct nf_conntrack_helper *helper; struct net *net = nf_ct_exp_net(exp); unsigned int h = nf_ct_expect_dst_hash(net, &exp->tuple); /* two references : one for hash insert, one for the timer */ atomic_add(2, &exp->use); /* 插入到help->expectations链表 */ hlist_add_head(&exp->lnode, &master_help->expectations);////如果有多个相关联的期望连接,链接起来 master_help->expecting[exp->class]++; /* 插入到全局的expect_hash表 */ hlist_add_head_rcu(&exp->hnode, &nf_ct_expect_hash[h]); net->ct.expect_count++; /* 设置并启动定时器 */ setup_timer(&exp->timeout, nf_ct_expectation_timed_out, (unsigned long)exp); helper = rcu_dereference_protected(master_help->helper, lockdep_is_held(&nf_conntrack_expect_lock)); if (helper) { exp->timeout.expires = jiffies + helper->expect_policy[exp->class].timeout * HZ; } add_timer(&exp->timeout); NF_CT_STAT_INC(net, expect_create); return 0; }
当tftp请求包进入nf_conntrack_in的时候,由于没有ct条目,所以调用init_conntrack()尝试新建一个条目,在这个函数中,根据skb新建两个方向的tuple,:
local_bh_disable(); /* 会在全局的期望连接链表expect_hash中查找是否有匹配新建tuple的期望连接。第一次过来的数据包肯定是没有的, 于是走else分支,__nf_ct_try_assign_helper()函数去nf_ct_helper_hash哈希表中匹配当前tuple, 由于我们在本节开头提到nf_conntrack_tftp_init()已经把tftp的helper extension添加进去了, 所以可以匹配成功,于是把找到的helper赋值给nfct_help(ct)->helper,而这个helper的help方法就是tftp_help()。 当tftp请求包走到ipv4_confirm的时候,会去执行这个help方法,即tftp_help(),也就是建立一个期望连接 当后续tftp传输数据时,在nf_conntrack_in里面,新建tuple后,在expect_hash表中查可以匹配到新建tuple的期望连接(因为只根据源端口来匹配), 因此上面代码的if成立,所以ct->master被赋值为exp->master,并且,还会执行exp->expectfn()函数,这个函数上面提到是指向nf_nat_follow_master()的, 该函数根据ct的master来给ct做NAT,ct在经过这个函数处理前后的tuple分别为: */ /* 在helper 函数中 回生成expect 并加入全局链表 同时 expect_count++*/ if (net->ct.expect_count) { /* 如果在期望连接链表中 */ spin_lock(&nf_conntrack_expect_lock); exp = nf_ct_find_expectation(net, zone, tuple); /* 如果在期望连接链表中 */ if (exp) { pr_debug("expectation arrives ct=%p exp=%p ", ct, exp); /* Welcome, Mr. Bond. We've been expecting you... */ __set_bit(IPS_EXPECTED_BIT, &ct->status); /* conntrack的master位指向搜索到的expected,而expected的sibling位指向conntrack……..解释一下,这时候有两个conntrack, 一个是一开始的初始连接(比如69端口的那个)也就是主连接conntrack1, 一个是现在正在处理的连接(1002)子连接conntrack2,两者和expect的关系是: 1. expect的sibling指向conntrack2,而expectant指向conntrack1, 2. 一个主连接conntrack1可以有若干个expect(int expecting表示当前数量),这些 expect也用一个链表组织,conntrack1中的struct list_head sibling_list就是该 链表的头。 3. 一个子连接只有一个主连接,conntrack2的struct ip_conntrack_expect *master 指向expect 通过一个中间结构expect将主连接和子连接关联起来 */ /* exp->master safe, refcnt bumped in nf_ct_find_expectation */ ct->master = exp->master; if (exp->helper) {/* helper的ext以及help链表分配空间 */ help = nf_ct_helper_ext_add(ct, exp->helper, GFP_ATOMIC); if (help) rcu_assign_pointer(help->helper, exp->helper); } #ifdef CONFIG_NF_CONNTRACK_MARK ct->mark = exp->master->mark; #endif #ifdef CONFIG_NF_CONNTRACK_SECMARK ct->secmark = exp->master->secmark; #endif NF_CT_STAT_INC(net, expect_new); } spin_unlock(&nf_conntrack_expect_lock); } /*在全局的期望连接链表expect_hash中查找是否有匹配新建tuple的期望连接。 第一次过来的数据包肯定是没有的,于是走else分支,__nf_ct_try_assign_helper() 函数去nf_ct_helper_hash哈希表中匹配当前tuple,由于我们在本节开头提到nf_conntrack_tftp_init() 已经把tftp的helper extension添加进去了,所以可以匹配成功,于是把找到的helper赋值给nfct_help(ct)->helper, 而这个helper的help方法就是tftp_help() */ if (!exp) {// 如果不存在 从新赋值 ct->ext->...->help->helper = helper __nf_ct_try_assign_helper(ct, tmpl, GFP_ATOMIC); NF_CT_STAT_INC(net, new); } /* Now it is inserted into the unconfirmed list, bump refcount */ nf_conntrack_get(&ct->ct_general); /* 将这个tuple添加到unconfirmed链表中,因为数据包还没有出去, 所以不知道是否会被丢弃,所以暂时先不添加到conntrack hash中 */ nf_ct_add_to_unconfirmed_list(ct); local_bh_enable(); if (exp) { if (exp->expectfn) exp->expectfn(ct, exp); nf_ct_expect_put(exp);
在全局的期望连接链表expect_hash中查找是否有匹配新建tuple的期望连接。第一次过来的数据包肯定是没有的,于是走else分支,
__nf_ct_try_assign_helper()函数去nf_ct_helper_hash哈希表中匹配当前tuple,由于nf_conntrack_tftp_init()已经把tftp的helper extension添加进去了,
所以可以匹配成功,于是把找到的helper赋值给nfct_help(ct)->helper,而这个helper的help方法就是tftp_help
当tftp请求包走到ipv4_confirm的时候,会去执行这个help方法,即tftp_help(),也就是建立一个期望连接
当后续tftp传输数据时,在nf_conntrack_in里面,新建tuple后,在expect_hash表中查可以匹配到新建tuple的期望连接(因为只根据源端口来匹配),
因此上面代码的if成立,所以ct->master被赋值为exp->master,并且,还会执行exp->expectfn()函数,这个函数上面提到是指向nf_nat_follow_master()的;
tftp_help回调函数中会执行nf_nat_tftp_hook---》也就是 nat的help函数
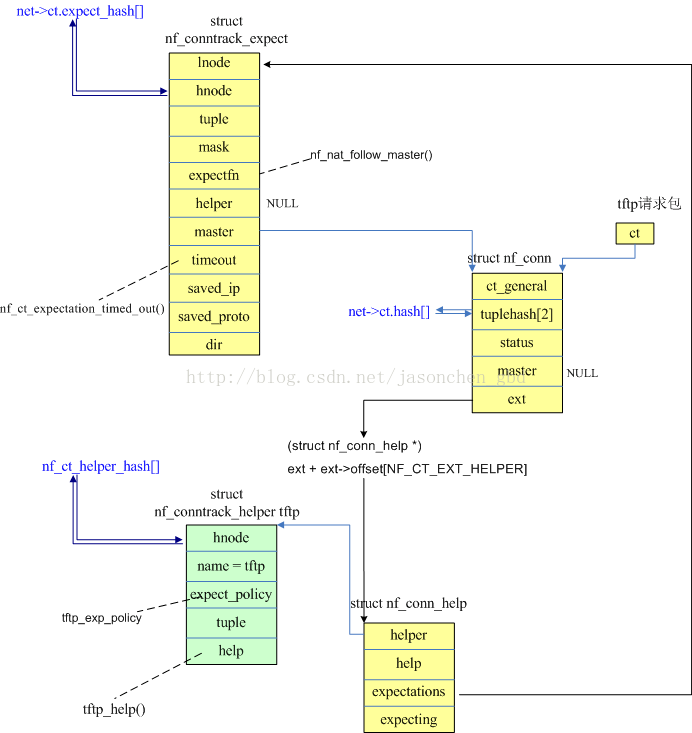
黄色部分内容是处理tftp请求包时初始化的,蓝色的数组是全局hash表。tftp数据包就根据上面的内容进行NAT转换;在nf_ct_find_expectation()查找期望连接时,
如果找到了,就把该期望连接从struct nf_conn_help结构的链表以及全局的期望连接链表expect_hash中删除。在expect_hash中的连接通过设置的超时时间来超时;
初始化help没有 命中tftp_help---》触发tftp_help时 会设置生成 nf_conntrack_expect 并插入全局连表, 第二次时 能找到exp 所以执行exp ---expertfn
来自:https://blog.csdn.net/jasonchen_gbd/article/details/44877343
static unsigned int help(struct sk_buff *skb, enum ip_conntrack_info ctinfo, struct nf_conntrack_expect *exp) { const struct nf_conn *ct = exp->master; exp->saved_proto.udp.port = ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple.src.u.udp.port; exp->dir = IP_CT_DIR_REPLY; /* 还注意到在help()函数中将exp-> expectfn赋值为nf_nat_follow_master(),这个函数的作用在后面会提到。 上面的内容是在客户端发送tftp请求后触发的动作,主要的效果就是生成了一个期望连接并可以被使用了。 下面以请求读数据来看一下传输数据时的数据包变化。 */ exp->expectfn = nf_nat_follow_master; if (nf_ct_expect_related(exp) != 0) { nf_ct_helper_log(skb, exp->master, "cannot add expectation"); return NF_DROP; } return NF_ACCEPT; } static void __exit nf_nat_tftp_fini(void) { RCU_INIT_POINTER(nf_nat_tftp_hook, NULL); synchronize_rcu(); } static int __init nf_nat_tftp_init(void) { BUG_ON(nf_nat_tftp_hook != NULL); RCU_INIT_POINTER(nf_nat_tftp_hook, help); return 0; }