问题背景
某平台镜像仓库,对上传上来的镜像tag,无法设置tag保留策略,如设置tag最多保留数目,导致开发人员流水线构建的镜像push到镜像仓库的tag不停累积,镜像仓库存储空间消耗很快。
经调研,虽然镜像仓库功能前端缺少相关设置选项,但是有相关restapi接口,包括删除镜像tag的后端接口。
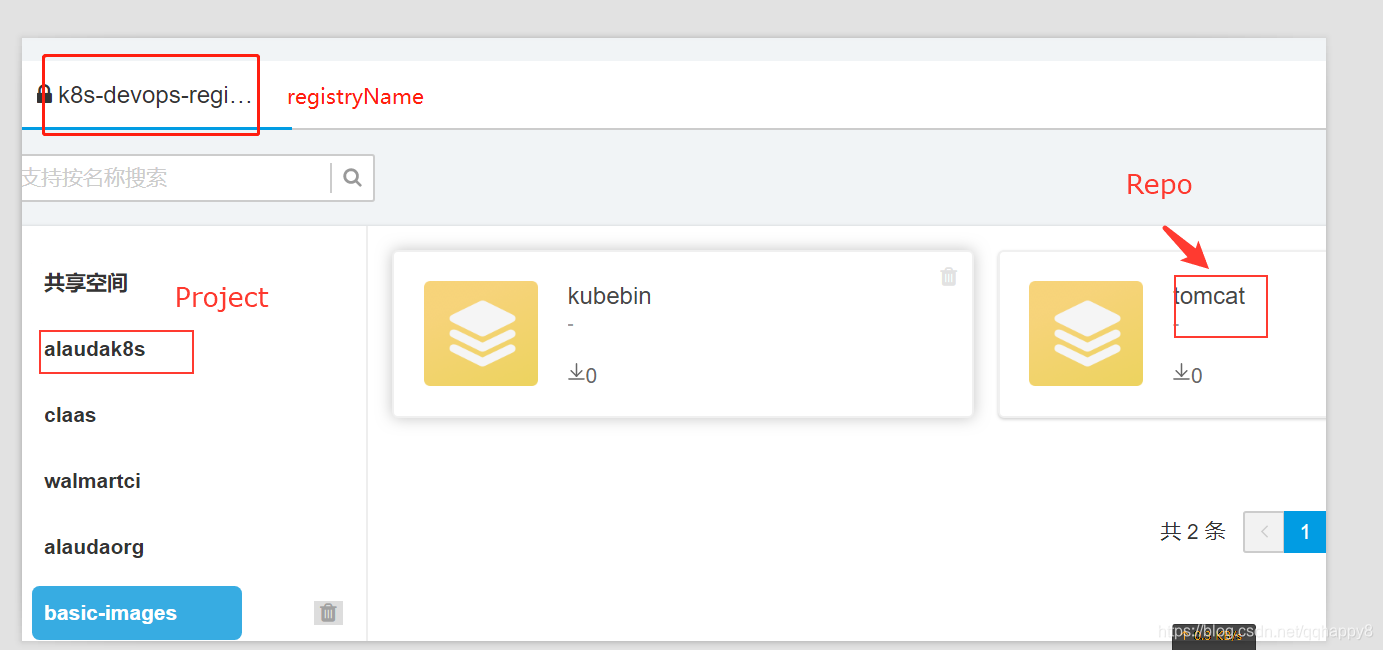
镜像仓库设计上由上到下分为3层,最上层为registryname,对应docker registry仓库;中间层为project,最下层为repo。一个registry下面有多个project,一个project下面有多个repo,一个repo有多个tag,如下图所示。
相关rest接口如下:




为了实现tag保留策略的功能,用Python撰写了脚本,通过requests模块调用接口,传入想保留的最大tag数目,repo的tag数目超过最大tag数目的,安装tag的创建时间进行排序,只保留日期最新的tag,其余tag进行清理,同时支持特定projec或者repo可以跳过tag数目的检查,脚本如下;
#!/bin/env python
# -*- coding: utf-8 -*-
import requests
import json
import argparse
#from collections import defaultdict
from dateutil.parser import parse
from time import mktime,sleep
from sys import exit
class repoTagClean:
def __init__(self,apiendpoint,token,registryName,maxtags,skipproject,skiprepo):
self.apiendpoint=apiendpoint
self.token=token
self.registryName=registryName
self.maxtags=maxtags
self.skipproject=skipproject
self.skiprepo=skiprepo
self.headers={"Authorization": "token"+" "+self.token}
def checkInput(self):
url=self.apiendpoint+"/v1/registries/alauda/"
try:
r=requests.get(url=url,headers=self.headers)
if r.status_code != 200:
print "the request return code %s,make sure the jakiro apiendpoint and the token is correct" %(r.status_code)
exit(6)
except:
print "some erros,quit "
exit(7)
def getProjecList(self,skipproject=None):
url=self.apiendpoint+"/v1/registries/alauda/"+self.registryName+"/projects"
r=requests.get(url=url,headers=self.headers)
r.encoding="utf-8"
ProjecList=[]
for p in json.loads(r.text):
ProjecList.append(p["project_name"].encode("utf-8"))
if skipproject!=None:
for i in skipproject.split(","):
ProjecList.remove(i)
return ProjecList
def getRepoList(self,projectName,skiprepo=None):
url=self.apiendpoint+"/v1/registries/alauda/"+self.registryName+"/projects/"+projectName+"/repositories"
r=requests.get(url=url,headers=self.headers)
r.encoding="utf-8"
#repoList=defaultdict(list)
repoList=[]
if len(json.loads(r.text))>0:
for i in json.loads(r.text):
repoList.append(i["name"].encode("utf-8"))
if skiprepo!=None:
for i in skiprepo.split(","):
if i in repoList:
repoList.remove(i)
return repoList
def getAllTagDict(self,projectName,repoName):
url=self.apiendpoint+"/v1/registries/alauda/"+self.registryName+"/projects/"+projectName+"/repositories/"+repoName+"/tags"+"?view_type=detail&page_size=100"
r=requests.get(url=url,headers=self.headers)
r.encoding="utf-8"
tagDict={}
if json.loads(r.text)["count"]>self.maxtags:
for i in json.loads(r.text)["results"]:
tagDict[i["tag_name"].encode("utf-8")]=mktime(parse(i["created_at"].encode("utf-8")).timetuple())
return tagDict
def getDeleteTagList(self,tagDict):
pendDeleteTag=[]
allTags=sorted(tagDict.items(),key=lambda x:x[1])
for i in allTags[:len(allTags)-self.maxtags]:
pendDeleteTag.append(i[0])
return pendDeleteTag
def getTagList(self):
#tagDict=defaultdict(defaultdict)
pendingDelete=[]
projectList=self.getProjecList(self.skipproject)
for p in projectList:
repoList=self.getRepoList(p,self.skiprepo)
if repoList:
for r in repoList:
print "begin to check project: [%s], the repo is: [%s]" %(p,r)
tagDict=self.getAllTagDict(p,r)
if tagDict:
t1=self.getDeleteTagList(tagDict)
pendingDelete.append((p,r,t1))
return pendingDelete
def deleteTag(self,pendingDelete):
for i in pendingDelete:
for j in i[2]:
url=self.apiendpoint+"/v1/registries/alauda/"+self.registryName+"/projects/"+i[0]+"/repositories/"+i[1]+"/tags/"+j
print "begin to clean tag:%s/%s/%s" %(i[0],i[1],j)
d=requests.delete(url=url,headers=self.headers)
sleep(1)
def main():
parser = argparse.ArgumentParser(description="Cleanup the extra images tag")
parser.add_argument("-i","--apiendpoint",dest="apiendpoint",required=True,help="the jakiro apiendpoint,like http://1.1.1.1:32001")
parser.add_argument("-t","--token",dest="token",required=True,help="the jakiro apiendpoint auth token")
parser.add_argument("-r","--registryname",dest="registryname",choices=["k8s-tools-registry","k8s-devops-registry"],required=True,help="the registryname")
parser.add_argument("-m","--maxtags",dest="maxtags",required=False,type=int,help="the maxtags to keep",default=10)
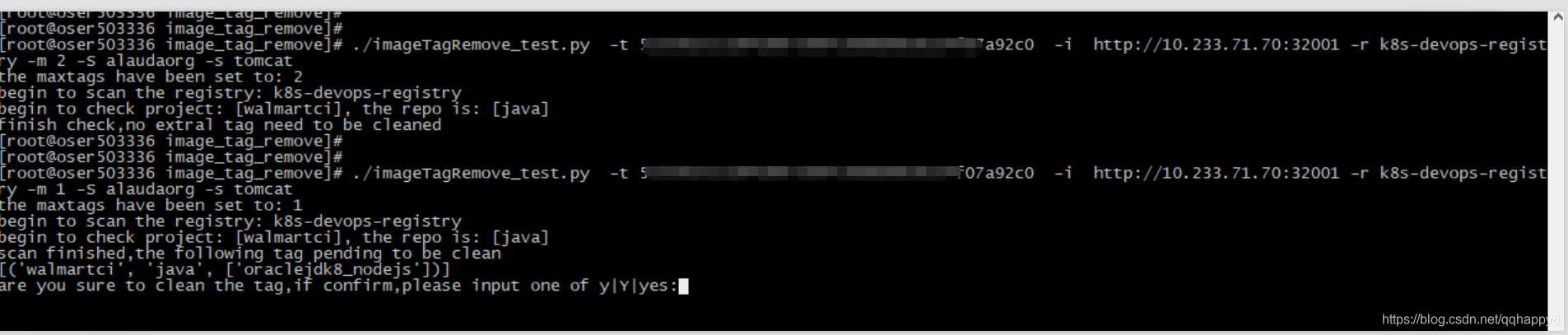
parser.add_argument("-S","--skipproject",dest="skipproject",type=str,help="the project which to be ignored for check")
parser.add_argument("-s","--skiprepo",dest="skiprepo",type=str,help="the repo which to be ignored for check")
args = parser.parse_args()
print "the maxtags have been set to: %d" %args.maxtags
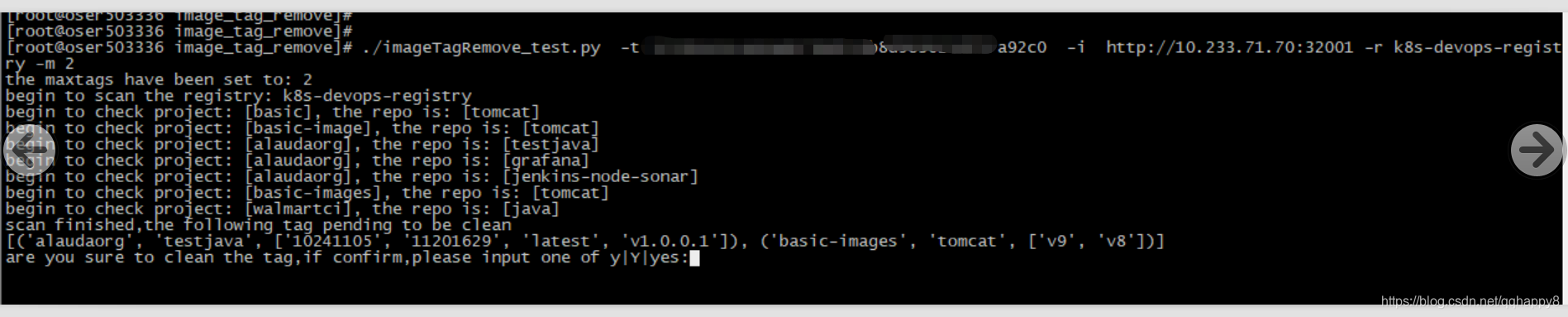
print "begin to scan the registry: %s" %args.registryname
clearner=repoTagClean(args.apiendpoint,args.token,args.registryname,args.maxtags,args.skipproject,args.skiprepo)
clearner.checkInput()
c=clearner.getTagList()
if c:
print "scan finished,the following tag pending to be clean"
print c
r=raw_input("are you sure to clean the tag,if confirm,please input one of y|Y|yes:")
if r=="y" or r=="Y" or r=="yes":
clearner.deleteTag(c)
else:
print "wrong input,quit"
else:
print "finish check,no extral tag need to be cleaned"
exit(0)
if __name__=="__main__":
main()执行效果如下: