trie树
最近接触到数据处理这一块,也就自然接触到了Trie树。它又称字典树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索系统用于文本词频统计,与比哈希表比查询效率要高。
主要思想
它的主要思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销。
作为一种树型结构,利用不同的节点来保存某一信息的一位信息,该信息的的最大位数决定了tire数的深度。为了能表示所有可能的信息,它的每个节点的出度的最大值就是信息所包含的不同字符的最多个数。在每个单词的结尾我们需要保存这个单词的个数。
从树的根开始查询,按照深度优先来查询,直到无法继续。每一层表示这信息的一位信息,当无法继续向下搜索时候,说明这个信息已经查询完毕。
所以,如果你要保存的是数字,那么我们的每个节点就要包括0-9这十个数字来保证我们信息的完整性;如果你要保存的是英文单词,那么每个节点就要包括26个英文单词了。
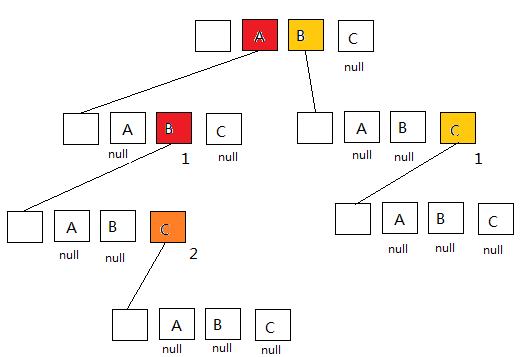
例如:abc,abc,ab,bc要保存在一棵trie树中,那么我们的节点就要包含a,b,c了,那么trie树的结构如下:
优缺点
每个节点都要保存由abc三种字母组成的信息,那么必然会有些节点上的信息未被被使用,tire树会造成空间的浪费。
查询的次数与单词中字母个数相同,这就使得算法的时间复杂度为O(len)。
它在信息检索,字符串匹配等领域有广泛的应用,同时,它也是很多算法和复杂数据结构的基础,如后缀树,AC自动机等。