使用关键字volatile可以禁止代码的重排序;
在Java程序运行时,JIT(即使编译器)可以动态地改变程序代码运行地顺序;例如,有如下代码:
A代码-重耗时 B代码-轻耗时 C代码-重耗时 D代码-轻耗时
在多线程环境下,JIT有可能进行代码重排序,重排序后地代码顺序有可能如下:
B代码-轻耗时 D代码-轻耗时 A代码-重耗时 C代码-重耗时
这样做地主要原因是CPU流水线是同时执行这4个指令的,那么轻耗时的代码在很大程度上先执行完成,以让出CPU流水线给其他指令,所以代码重排序是为了追求更高的程序运行的效率;
重排序发生在没有依赖关系时,例如,对于上面的A,B,C,D代码,B,C,D代码不依赖A代码的结果,C,D代码不依赖A,B代码的结果,D代码不依赖A,B,C代码的结果,这种情况下就会发生重排序,如果代码之间有依赖关系,则代码不会重排序;
使用关键字volatile可以禁止代码重排序,例如,有如下代码:
A变量的操作 B变量的操作 volatile Z变量的操作 C变量的操作 D变量的操作
那么会有4种情况发生:
- A,B可以重排序
- C,D可以重排
- A,B不可以重排到Z的后面
- C,D不可以重排到Z的前面
换言之,变量Z是一个屏障,Z变量之前或之后不可以跨越Z变量,这就是屏障的作用,关键字synchronized具有同样的特性;
1.关键字synchronized之前的代码不可以重排到synchronized之后
2.关键字synchronized之后的代码不可以重排到synchronized之前
使用双重检查锁实现多线程环境下的延迟加载单例模式
public class Singleton {
private static volatile Singleton singleton;
private Singleton() {
}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
使用volatile修饰变量singleton使该变量在多个线程间达到可见性,另外也禁止了singleton = new Singleton()的代码重排序,singleton = new Singleton()代码在内部分为3部分:
1.memory = allocate(); //分配对象的内存空间 2.ctorInstance(memory); //初始化对象 3.instance = memory; //设置instance指向刚分配的内存地址
在一些JIT编译器上,这种指令重排是真实发生的;
1.memory = allocate(); //分配对象的内存空间 3.instance = memory; //设置instance指向刚分配的内存地址 2.ctorInstance(memory); //初始化对象
所有线程在执行Java程序时都必须要遵守intra-thread semantics;intra-thread semantics保证重排序不会改变单线程内的程序结果;换句话说,intra-thread semantics允许那些在单线程内,不会改变单线程程序执行结果的重排序;
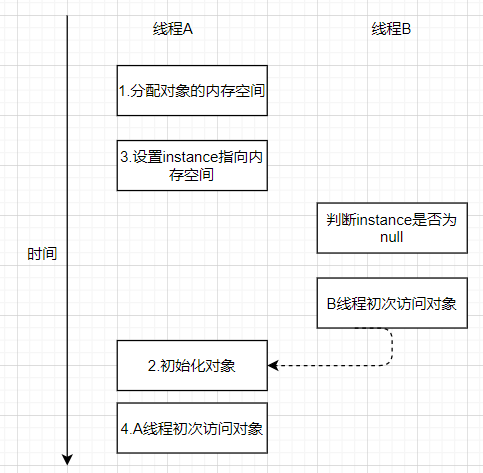
当线程A,线程B执行时,B线程访问instance所引用的对象,但这个对象没有被线程A初始化,线程B将看到一个还没有被初始化的对象;
这里的A2和A3虽然重排序了,但Java内存模型的intra-thread semantics将确保A2一定会排在A4前面执行;因此,线程A的intra-thread semantics没有改变,但A2和A3的重排序,将会导致线程B判断instance实例不为空,线程B接下来将访问instance引用的对象(上图中线程B中的虚线),此时线程B访问到的是一个没有没有初始化的对象(没有进行赋值的对象),返回的是一个空的对象;