ResNet的梯度计算
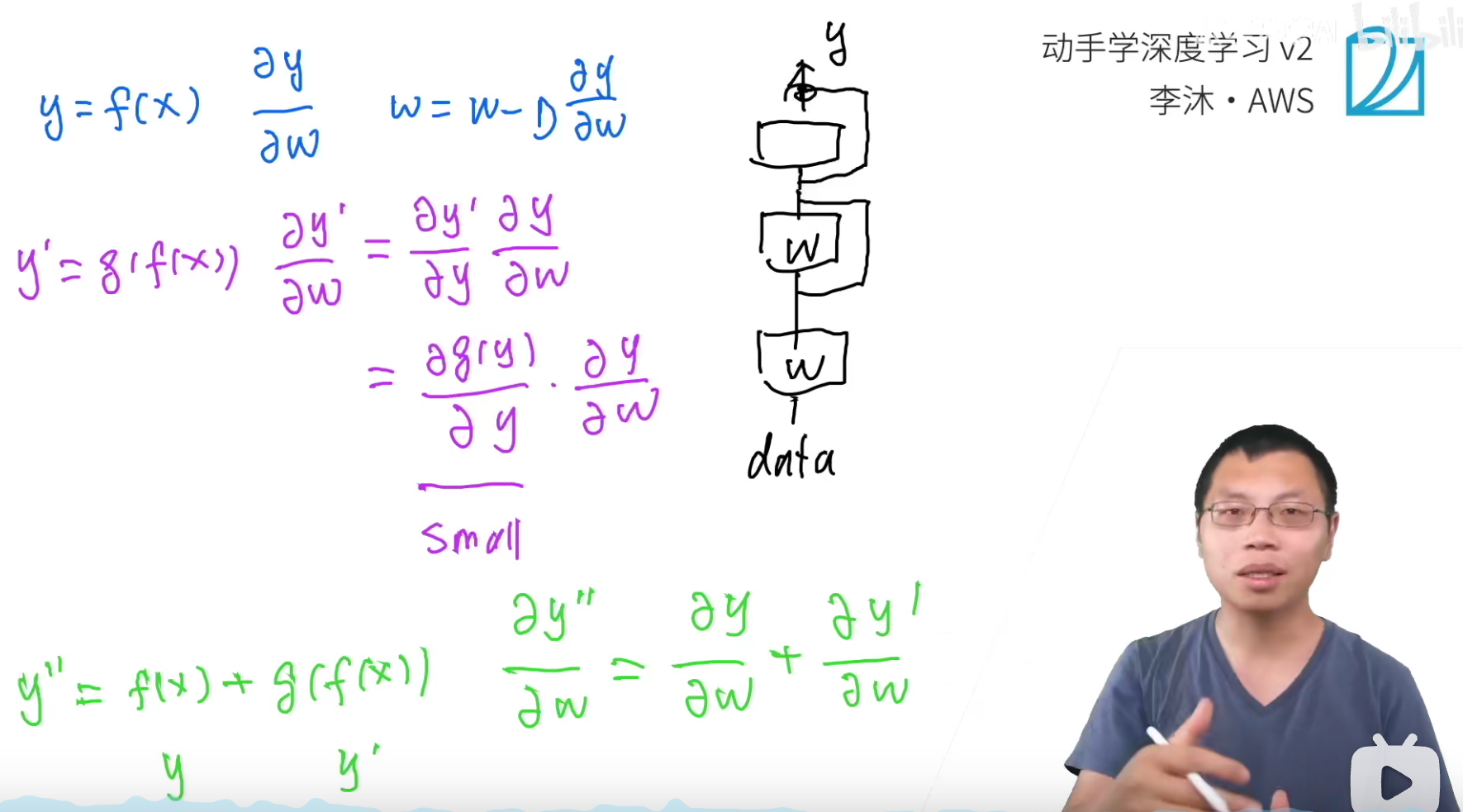
最最核心的思想就是乘法变加法。

如果是这种情况,加入g()这一层已经学的很好了,那么梯度就会变小,这样就对f()的梯度也会越来越小(相当于小数字的累乘)
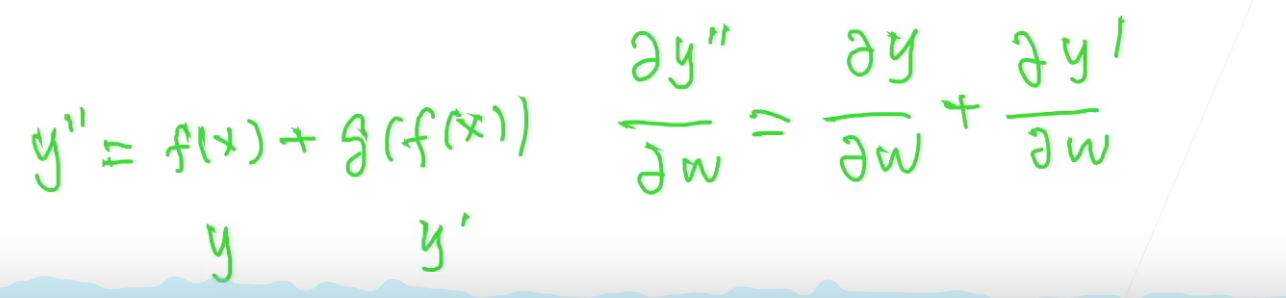
但是如果是残差结构的话,直接使用加法,那么即使g()学的很好,其梯度很小,也不会影响f()的梯度。
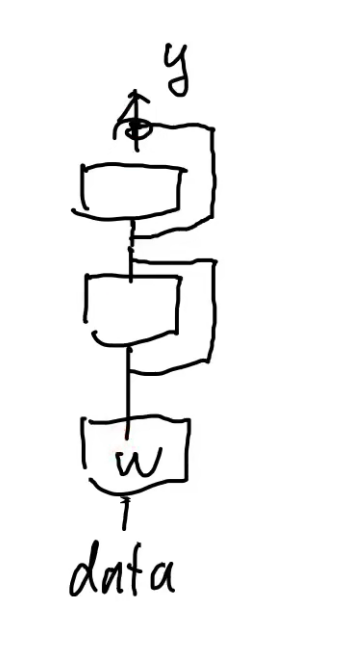
正常的深度结构只能是从上至下,但是残差的这个跳转结构,相当于数据可以从这条跳转的“高速公路”直接下来。(原来的深层神经网络最大的问题也是底层的参数更新)
QA
- 学习率可不可让靠近输出的小一些,靠近输入的大一些,这样会不会缓解梯度消失的问题?
可以的。但是它的问题是你不是那么好设置它的数值。
- 为什么深层的网络,底层比较难训练?是因为它拿到的梯度一般比较小?
是的。
梯度消失:小数值累乘。
梯度爆炸:大数值累乘。