身份证识别
一、tesseract-ocr简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
下载地址:http://www.softpedia.com/get/Programming/Other-Programming-Files/Tesseract-OCR.shtml
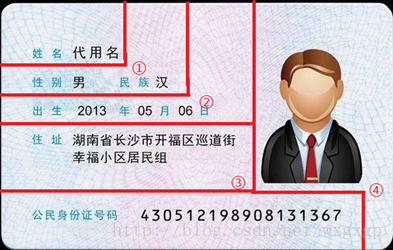
二、身份证特征
长:856mm
宽:540mm
厚:1mm
各个区域定点对应的坐标及比例如下(以左上角为原点):(单位:mm,W:宽,H:高)
① (32,11.5) W:0.374 H:0.213
② (42,18) W:0.491 H:0.333
③ (51,24.3) W:0.596 H:0.45
④ (51,38) W:0.619 H:0.704
⑤ (78,54) W:0.911 H:0.704
三、识别原理及流程
- 识别流程:
① 提取原图中身份证所在的四个角点,进行仿射变换矫正。
② 将矫正后的图像进行灰度化、高斯滤波以及自适应二值化等去噪处理。
③ 获取图像的尺寸,计算各个信息区域矩形的坐标,并将目标区域裁剪出 来保存。
④ 向tesseract-ocr命令行传送保存图片路径、识别结果路径以及识别语言等参数。
⑤ 获取识别结果。 - tesseract-ocr用法:
tesseract 图片路径 输出文件 -l “chi_sim”;
图片路径:要识别的图片路径。
输出文件:包含识别结果的txt文件(不需要写.txt)
“chi_sim”:设置识别语言为中文。
四:识别效果
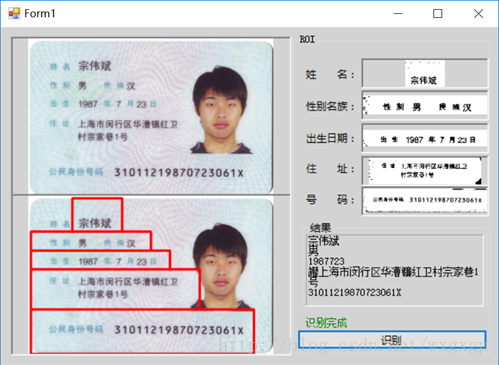
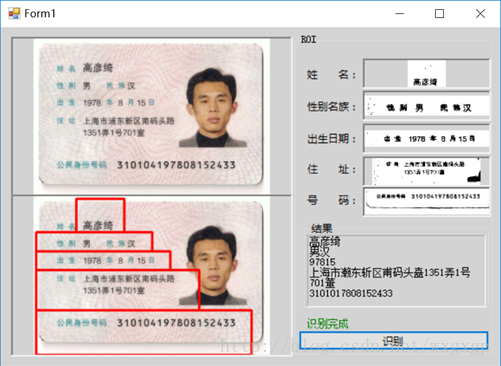
(图片来自网络)