Given an array of integers citations where citations[i] is the number of citations a researcher received for their ith paper, return compute the researcher's h-index.
According to the definition of h-index on Wikipedia: A scientist has an index h if h of their n papers have at least h citations each, and the other n − h papers have no more than h citations each.
If there are several possible values for h, the maximum one is taken as the h-index.
Example 1:
Input: citations = [3,0,6,1,5] Output: 3 Explanation: [3,0,6,1,5] means the researcher has 5 papers in total and each of them had received 3, 0, 6, 1, 5 citations respectively. Since the researcher has 3 papers with at least 3 citations each and the remaining two with no more than 3 citations each, their h-index is 3.
Example 2:
Input: citations = [1,3,1] Output: 1
Constraints:
n == citations.length1 <= n <= 50000 <= citations[i] <= 1000
H 指数。
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。且其余的 N - h 篇论文每篇被引用次数 不超过 h 次。
例如:某人的 h 指数是 20,这表示他已发表的论文中,每篇被引用了至少 20 次的论文总共有 20 篇。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/h-index
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
两种思路,第一种是排序;第二种是用到计数排序。
排序法:例子,
[3,0,6,1,5]
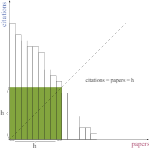
按照从大到小排序,排序过后的数组为 [6, 5, 3, 1, 0]。此时扫描数组,判断下标 i 是否 >= citation[i]。因为一共有 n 篇论文,所以判断的是是不是至少有 i 篇论文,被引用的次数大于等于 i 次。用这个图帮助理解,
citation, https://leetcode-cn.com/problems/h-index/solution/hzhi-shu-by-leetcode/
时间O(nlogn)
空间O(1)
JavaScript实现
1 /** 2 * @param {number[]} citations 3 * @return {number} 4 */ 5 var hIndex = function(citations) { 6 citations = citations.sort((a, b) => b - a); 7 let len = citations.length; 8 for (let i = 0; i < len; i++) { 9 if (i >= citations[i]) { 10 return i; 11 } 12 } 13 return len; 14 };
Java实现
1 class Solution { 2 public int hIndex(int[] citations) { 3 Arrays.sort(citations); 4 int res = 0; 5 while (res < citations.length && citations[citations.length - 1 - res] > res) { 6 res++; 7 } 8 return res; 9 } 10 }
计数排序
建立一个 [citations.length + 1] 长度的数组 buckets,表示被引用的次数。遍历 citations,根据每篇文章的引用次数,将文章累加到每一个 bucket 里面。按照上面的例子,数组本身的长度为 5,如果遇到被引用次数大于 5 的,也一律放在下标为 5 的位置上,因为引用次数大于 5 的文章再多,都不会影响这个作者的 H 指数。解释参见这个帖子的方法二。从右往左再次遍历这个 buckets 并开始累加(注意这里累加的是文章的数量)。如果累加和大于或等于当前的i - 也就是当前的被引用次数,我们就找到了这个 H 指数。
时间O(n)
空间O(n)
JavaScript实现
1 /** 2 * @param {number[]} citations 3 * @return {number} 4 */ 5 var hIndex = function(citations) { 6 const buckets = Array(citations.length + 1).fill(0); 7 citations.forEach(citation => { 8 buckets[citation >= citations.length ? citations.length : citation]++; 9 }); 10 let count = 0; 11 for (let i = citations.length; i >= 0; i--) { 12 count += buckets[i]; 13 if (count >= i) { 14 return i; 15 } 16 } 17 return 0; 18 };
Java实现
1 class Solution { 2 public int hIndex(int[] citations) { 3 int n = citations.length; 4 int[] bucket = new int[n + 1]; 5 for (int c : citations) { 6 if (c >= n) { 7 bucket[n]++; 8 } else { 9 bucket[c]++; 10 } 11 } 12 int count = 0; 13 for (int i = n; i >= 0; i--) { 14 count += bucket[i]; 15 if (count >= i) { 16 return i; 17 } 18 } 19 return 0; 20 } 21 }
相关题目