更换虚拟机以后操作的步奏
1.到每一台机器上修改ip地址 ,然后修改hosts
1.5 给每台机器配置免密码登录
2.修改hadoop 的配置文件,发送到每台机器上
3.启动dfs start-dfs.sh
PS:Netty现在已经成为大数据的主角了
PS:安装时hadoop格式化错误的解决方案, 说明 yarn没有起来

http://blog.csdn.net/weiyongle1996/article/details/74094989
安装Hadoop可能遇到的问题
1/运行mr程序出错, yarn没有启动 connecting to resoucemanager retrying .... retrying ..... 原因是没有启动yarn或者启动失败 2/初始化工作目录结构 hdfs namenode -format 只是初始化了namenode的工作目录 而datanode的工作目录是在datanode启动后自己初始化的 3/datanode不被namenode识别的问题 namenode在format初始化的时候会形成两个标识: blockPoolId: clusterId: 新的datanode加入时,会获取这两个标识作为自己工作目录中的标识 一旦namenode重新format后,namenode的身份标识已变,而datanode如果依然 持有原来的id,就不会被namenode识别 4/datanode下线后多久看到效果 datanode不是一下线就会被namenode认定为下线的,有一个超时时间 5/关于副本数量的问题 副本数由客户端的参数dfs.replication决定(优先级: conf.set > 自定义配置文件 > jar包中的hdfs-default.xml)
-------------------------------------------------离线计算系统-----------------------
0.Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
1.Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
2.
HDFS
NameNode
DataNode
1.1 什么是HADOOP
- HADOOP是apache旗下的一套开源软件平台-------也可以说是中间件
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统) 要统计数据在一台机器上存不下,那么就要分块,还要记住文件在哪台机器上
- YARN(运算资源调度系统) 需要一种制度来管理硬件资源 resource manager、node manager
- MAPREDUCE(分布式运算编程框架) 任务的执行分为两个阶段,一个是maptask阶段,reducetask阶段。逻辑就写在 Mapreduce框架中。
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
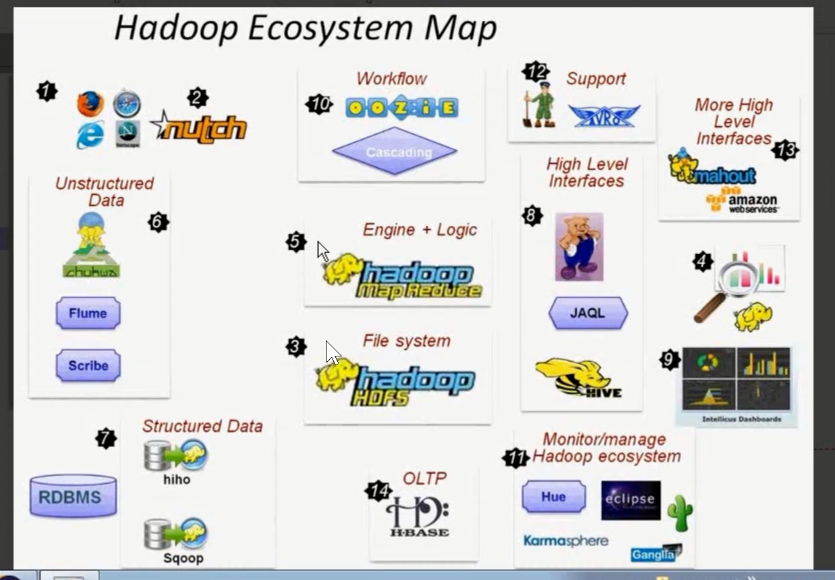
PS: hadoop的生态圈 1. Hive是查询数据库的一个框架,(HDFS+MapReduce)的一个替代,用sql执行操作。
- 2. Workflow就是做工作流的问题, 用阿斯卡板,不用 乌贼(因为比较框架太重)
- 3. 右上角就是机器学习。

PS:传统的机器算法,和现在都差不多。都是在样本基础的上,分析样本的距离。
但是,hadoop出来以后,可以把所有的传统的计算算法进行实现,那么,速度执行效率有很大的提升,因为机器学习本身就是非常耗费机器资源的, 因为数据量的计算问题。
4.flume主要解决大数据的日志问题,因为大数据项目,日志必然很多,所以使用这个框架日志
5.左下角 sqoop解决的是数据的迁移问题,我们可以把传统的数据转移到关系型数据库,也可以把数据转移到hadoop数据库
-
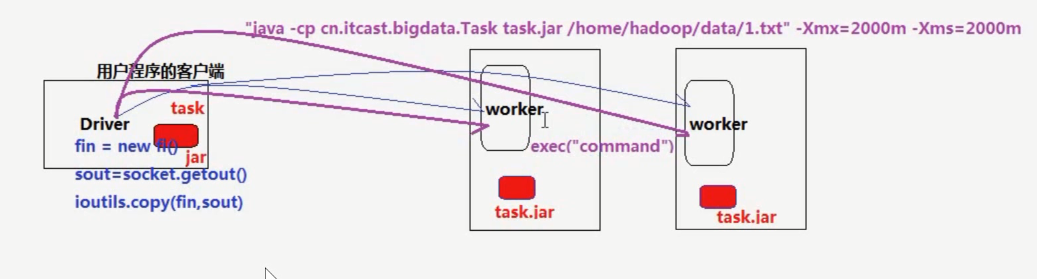
PS:hadoop的框架引出, 比如说客户端有个任务统计字符,然后把人物分别打成jar包,放在每个服务器上。最后把做好数据返回给服务器。
但是比如说中间某台集群的机器挂了,就急需一个框架来解决问题。hadoop来了,我们只需关心业务逻辑,无需关心其他的复杂的问题。
PS:hadoop是一种框架,但是与传统的框架有不太一样。 因为传统 的框架需要导包,但是hadoop不一样,他需要多态服务器集群然后才可以利用相应的api。
像一个中间件,做离线的数据分析处理。
1.3 HADOOP在大数据、云计算中的位置和关系
- 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
- 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
- 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
--------------------------分布式系统----------------------------------
PS:我的理解就是把一个大的 问题 分解为 多个小的问题 然后再汇总回来 ,完成并行计算。
----------------------------------------------------------------------------------------
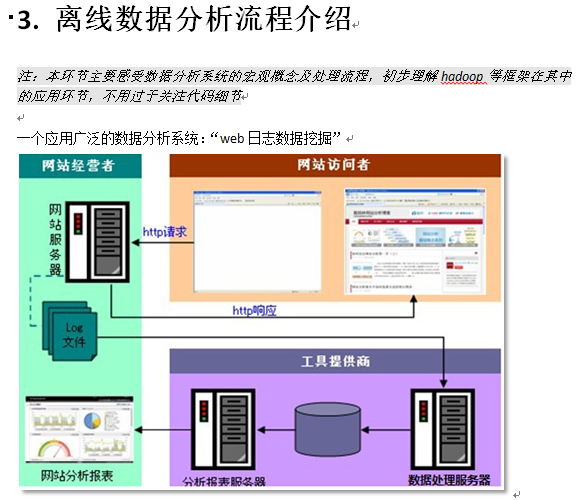
3.1.2 案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
3.1.3 数据来源
本案例的数据主要由用户的点击行为记录
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
|
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0" |
3.2 数据处理流程
3.2.1 流程图解析
本案例跟典型的BI系统极其类似,整体流程如下:
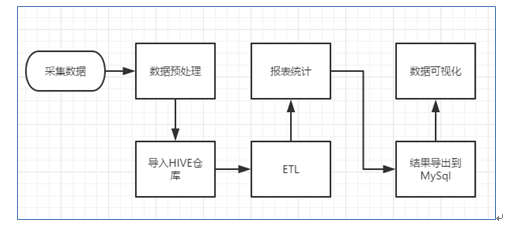
但是,由于本案例的前提是处理海量数据,因而,流程中各环节所使用的技术则跟传统BI完全不同,后续课程都会一一讲解:
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
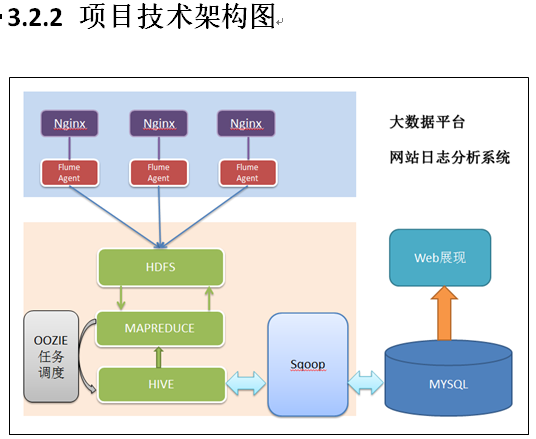
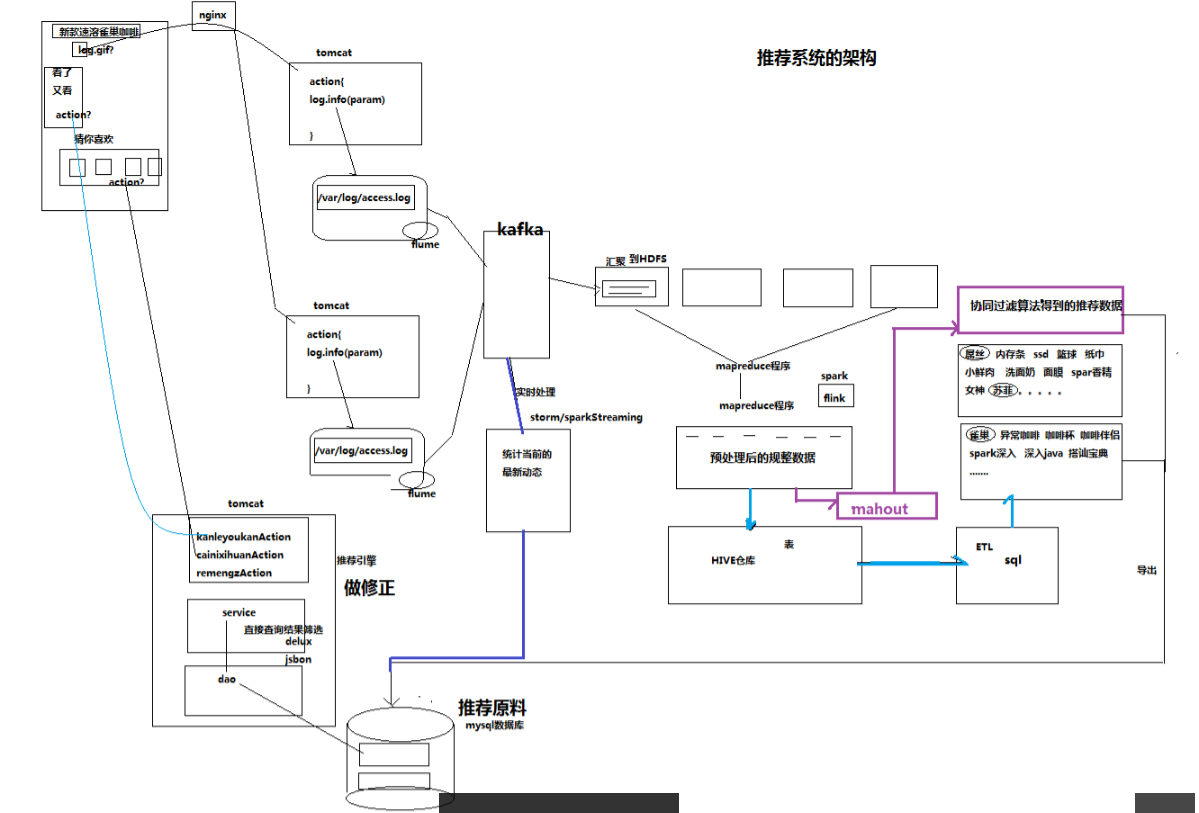
PS:首先在 web系统的图片上预埋链接,记录到各个系统的分布式框架中的日志文件中。 如果是直接离线处理的话,就在HDFS系统中接着处理,后面使用mapreduce都数据进行分析,
在这里可以直接保存到Hive数据库中,也可以通过mahout对数据处理,最后导入mysql数据库中,进行数据可视化; 如果是实时对数据处理的话,使用kafka和spark直接汇入mysql,
到推荐界面(比如锤子手机说科大讯飞,使得科大讯飞用户猛增)
在推荐界面,还有自己的service进行干预,进行数据推荐(比如天冷就卖手套,情人节卖巧克力)
--------------------------------Hadoop集群安装-------------------------------------------------------
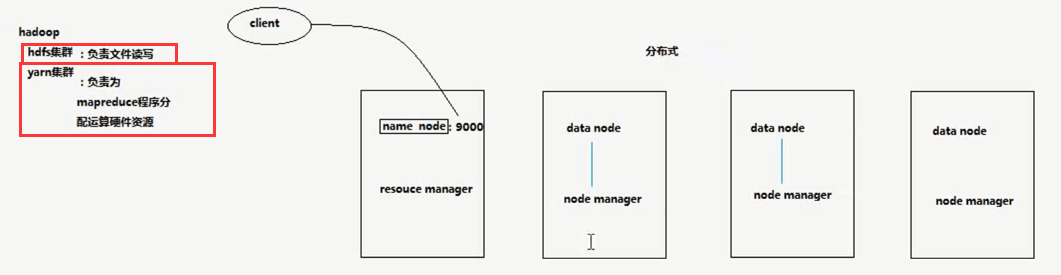
PS:Hadoop集群的 其实就是 hdfs的集群(name node)和yarn的集群(resource manager和 nodenanager)
PS:Hadoop的api非常多,但是我们只用常用的那几个就行了。在视频中都会讲解到。
4. 集群搭建
4.1 HADOOP集群搭建
4.1.1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
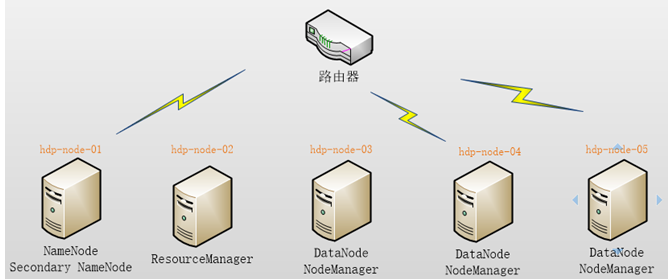
本集群搭建案例,以5节点为例进行搭建,角色分配如下:
|
hdp-node-01 NameNode SecondaryNameNode hdp-node-02 ResourceManager hdp-node-03 DataNode NodeManager hdp-node-04 DataNode NodeManager hdp-node-05 DataNode NodeManager |
部署图如下:
--------------------------------Hadoop 安装----------------------------
1.准备Linux环境
1.0先将虚拟机的网络模式选为NAT
1.1修改主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=itcast ###
1.2修改IP
两种方式:
第一种:通过Linux图形界面进行修改(强烈推荐)
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.1.101 子网掩码:255.255.255.0 网关:192.168.1.1 -> apply
第二种:修改配置文件方式(屌丝程序猿专用)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.1.101" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.1.1" ###
1.3修改主机名和IP的映射关系
vim /etc/hosts
192.168.1.101 itcast
1.4关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
1.5 修改sudo
su root
vim /etc/sudoers
给hadoop用户添加执行的权限
关闭linux服务器的图形界面:
vi /etc/inittab
1.5重启Linux
reboot
2.安装JDK
2.1上传alt+p 后出现sftp窗口,然后put d:xxxyylljdk-7u_65-i585.tar.gz
2.2解压jdk
#创建文件夹
mkdir /home/hadoop/app
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
2.3将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
-----------------------------------------------------------------------------------------------

1.cd /home/
2. D:/Study/Java/chuanzhiboke大数据/视频/day06Hadoop/day06/软件/cenos-6.5-hadoop-2.6.4.tar.gz
mv /home/cenos-6.5-hadoop-2.6.4.tar.gz /root/cenos-6.5-hadoop-2.6.4.tar.gz
3.tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C apps/

PS:Hadoop虽然是用java 写的(跨平台),但是使用的时候还是要编译一下(需要安装很多的配置环境)。本人学习使用的是上面的tar包,centos6.5, 6.7也能用
3.安装hadoop2.4.1
先上传hadoop的安装包到服务器上去/home/hadoop/
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
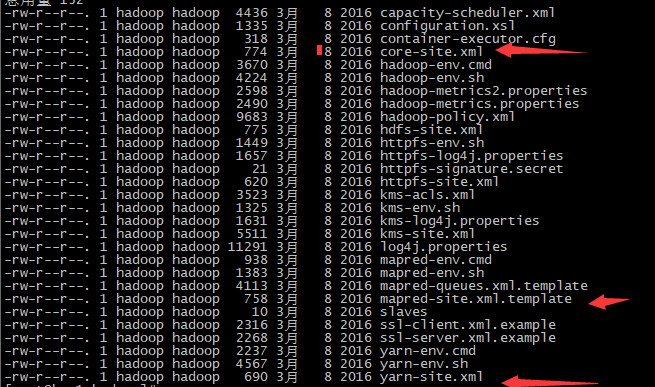
伪分布式需要修改5个配置文件

3.1配置hadoop
第一个:hadoop-env.sh
vim hadoop-env.sh
#第27行
export JAVA_HOME=/root/apps/jdk1.7.0_45
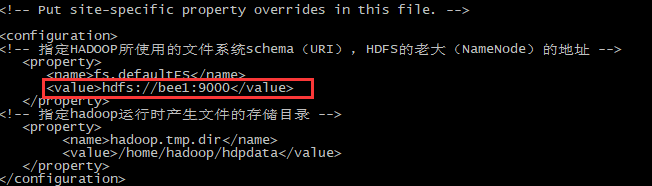
第二个:core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bee1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量,其实是可以不用配置 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.1.152:50090</value>
</property>
第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml //因为不编辑模板是空的
vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
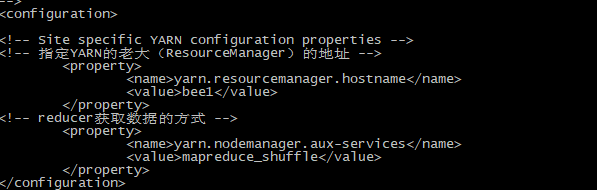
第五个:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bee1</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
PS:配置好以后给每个机器传一份 scp -r apps bee3:/root
-------------------------------------------------------------------------------------
3.2将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/root/java/jdk1.7.0_65
export HADOOP_HOME=/itcast/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

export JAVA_HOME=/root/apps/jdk1.7.0_45
export HADOOP_HOME=/root/apps/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
把配置文件发给每台机器 sudo scp /etc/profile bee2:/etc 为了每台机器都能使用hadoop
source /etc/profile
3.3格式化namenode(是对namenode进行初始化,对配置文件初始化)
hdfs namenode -format (hadoop namenode -format)

-------------------------------------------------------------
PS:没有配置其他小弟,启动的话,可以在任何的机器上去启动
hadoop-daemon.sh start namenode 启动每一台机器
hadoop-daemon.sh stop namenode 关闭每一台机器


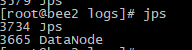
PS: 输入JMS测试系统是否启动,上图证明机器启动起来了
------------------------------------------------------------------------------
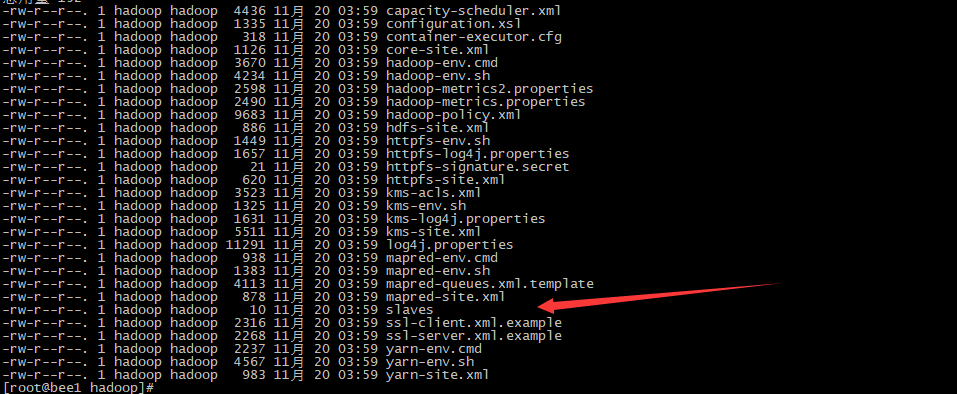
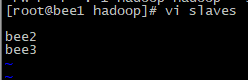
PS:如果这样启动的话,太浪费时间,我们需要脚本全部启动,slavs文件放所有的配置机器
PS:然后为老大,和小弟之间配置免密码登录。然后就可以 start-dfs.sh
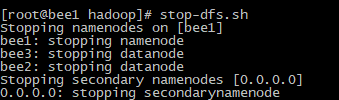
关闭 stop-dfs.sh
-----------------------------

PS: 这个启动的过程很慢
PS:关闭分布式系统
3.4启动hadoop
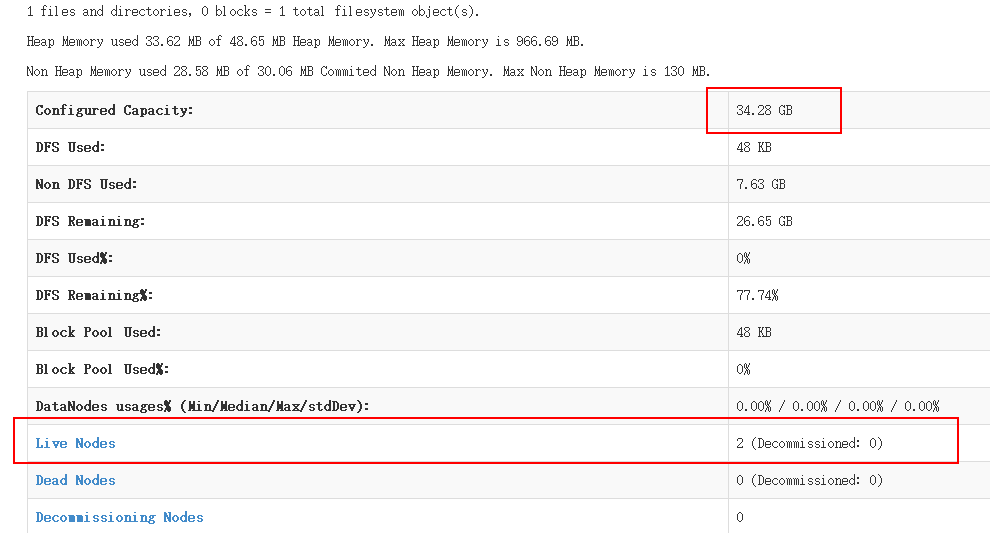
先启动HDFS
sbin/start-dfs.sh

----------------------启动成功--------------------------------------------------
再启动YARN
sbin/start-yarn.sh
3.5验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.1.101:50070 (HDFS管理界面)
http://192.168.1.101:8088 (MR管理界面)
4.配置ssh免登陆
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id localhost
---------------------------
ssh免登陆:
生成key:
ssh-keygen
复制从A复制到B上:
ssh-copy-id B
验证:
ssh localhost/exit,ps -e|grep ssh
ssh A #在B中执行
PS:其实namenode和datanode就是运行在分布式机器上的软件
PS: jps找出执行 的java进程
PS:
后来安装的时候,遇到了0个datanode
1.最后重新安装解决了问题 2.修改了tmp位置 和删除log 的位置
PS:安装时遇到的问题
1.jps命令找不到 http://blog.csdn.net/zhanglu1236789/article/details/50445261
----------------------------------------------------HDFS SHell-----------------------------------------------------------------------------------------------------------------------------------------------------
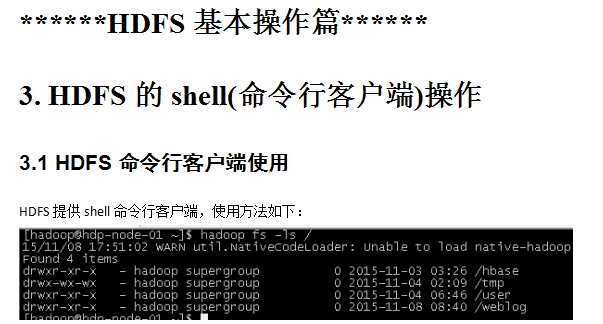
PS:服务端查看文件
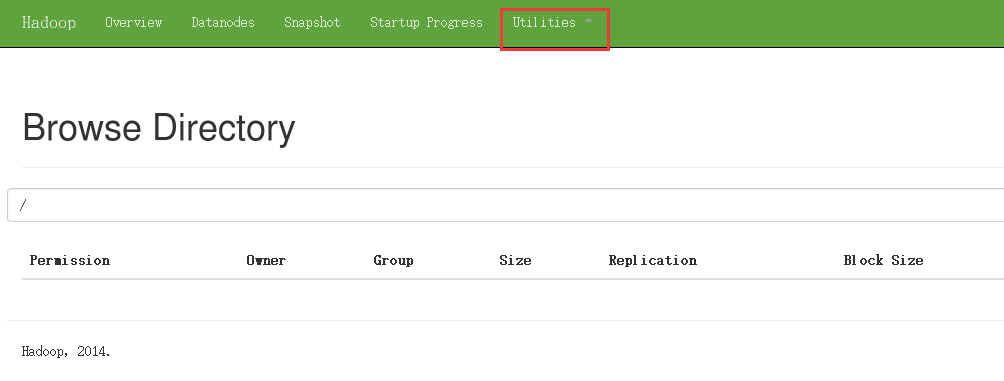
PS: 客户端查看文件 (客户端访问命令使用的是箭头所指的,在hadoop/bin目录下面)
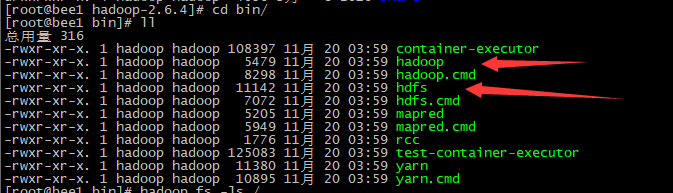

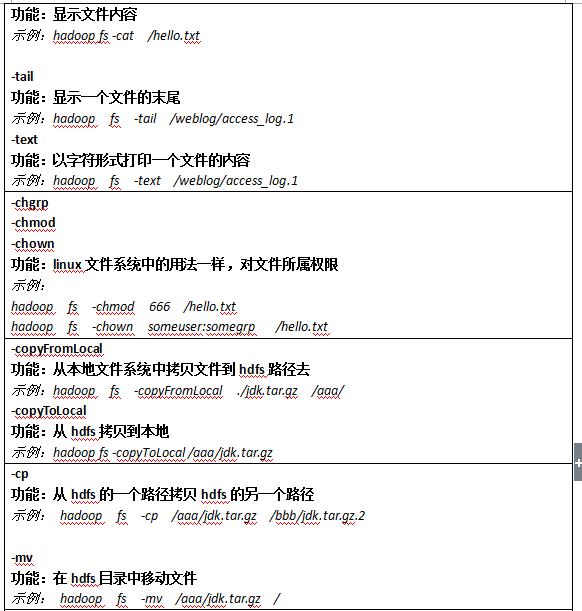
------------------------上传命令
1.hadoop fs -put test.sh / 上传test.sh到 /
PS:在网页端查看

PS:在客户端查看

PS:文件大小为128M才会对文件切分

PS:经过验证,大文件分成块以后是可以合并的并且使用的。所以框架帮我们做的也是这样的工作。
2. 观察其他机器备份的文件 
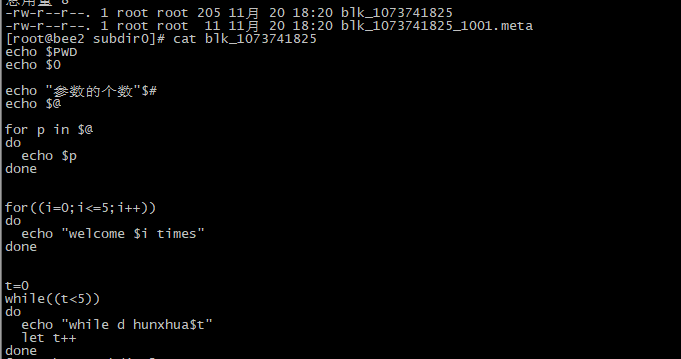
3.1.hadoop fs -put test.sh / 获取文件
------------------------------体验mapreduce wordcount功能------------------------
PS:执行前确保三件事
1.集群的时间同步
2. start-dfs.sh只是启动hdfs
3.start-yarn.sh也应该启动,他启动的的是计算资源
1.cp wordtest.txt wordtest2.txt //创建文件,写入相应的字符,然后复制文件
2.创建 文件和文件夹上传到 /wordcount/input目录下

3.到 hadoop 的 share/mapreduce的目录下找到jar包,执行命令 执行成功就放在/wordcount/output目录下面

hadoop jar hadoop-mapreduce-examples-2.6.4.jar wordcount /wordcount/input /wordcount/output
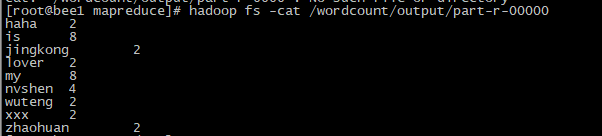
4.查看mapreduce分析过的文件
hadoop fs -cat /wordcount/output/part-r-00000





-------------Java API文件系统的操作
-------------------------------------------
1.首先添加jar包,需要添加common和hdfs的jar和lib中的jar
2.因为windows系统,无法执行hadoop的东西,需要添加添加hadoop环境变量

----------------------------------------------- import java.net.URI; import java.util.Iterator; import java.util.Map.Entry; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.LocatedFileStatus; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.RemoteIterator; import org.junit.Before; import org.junit.Test; /** * * 客户端去操作hdfs时,是有一个用户身份的 * 默认情况下,hdfs客户端api会从jvm中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=hadoop * * 也可以在构造客户端fs对象时,通过参数传递进去 * @author * */ public class HdfsClientDemo { FileSystem fs = null; Configuration conf = null; @Before public void init() throws Exception{ conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://bee1:9000"); //拿到一个文件系统操作的客户端实例对象 /*fs = FileSystem.get(conf);*/ //可以直接传入 uri和用户身份 fs = FileSystem.get(new URI("hdfs://bee1:9000"),conf,"root"); //最后一个参数为用户名 } @Test public void testUpload() throws Exception { Thread.sleep(2000); fs.copyFromLocalFile(new Path("D:/wordtest_PC.txt"), new Path("/wordtest_PC.txt.copy")); fs.close(); } @Test public void testDownload() throws Exception { fs.copyToLocalFile(new Path("/wordtest_PC.txt.copy"), new Path("d:/")); fs.close(); } @Test public void testConf(){ Iterator<Entry<String, String>> iterator = conf.iterator(); while (iterator.hasNext()) { Entry<String, String> entry = iterator.next(); System.out.println(entry.getValue() + "--" + entry.getValue());//conf加载的内容 } } /** * 创建目录 */ @Test public void makdirTest() throws Exception { boolean mkdirs = fs.mkdirs(new Path("/aaa/bbb")); System.out.println(mkdirs); } /** * 删除 */ @Test public void deleteTest() throws Exception{ boolean delete = fs.delete(new Path("/aaa"), true);//true, 递归删除 System.out.println(delete); } @Test public void listTest() throws Exception{ FileStatus[] listStatus = fs.listStatus(new Path("/")); for (FileStatus fileStatus : listStatus) { System.err.println(fileStatus.getPath()+"================="+fileStatus.toString()); } //会递归找到所有的文件 RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); while(listFiles.hasNext()){ LocatedFileStatus next = listFiles.next(); String name = next.getPath().getName(); Path path = next.getPath(); System.out.println(name + "---" + path.toString()); } } /* public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://bee1:9000"); //拿到一个文件系统操作的客户端实例对象 FileSystem fs = FileSystem.get(conf); fs.copyFromLocalFile(new Path("G:/access.log"), new Path("/access.log.copy")); fs.close(); }*/ }