常用属性
-
dtype
返回Series的数据类型 -
dtypes
返回DataFrame每一列的数据类型 -
index
返回0轴索引,可以使用list()将其变为列表形式 -
columns
返回1轴索引,可以适应list将其变为列表类型 -
values
返回值,是一个array类型 -
shape
返回维度 -
T
行列转置
常用的方法
-
head()
参数: 数字
默认查看前五行,可是加参数来改变查看的行数 -
tail()
参数: 数字
默认查看最后五行,可以添加参数指定查看的行数 -
describe()
查看数据的描述信息,包括计数,均值,最大最小值,分布 -
info()
查看数据的基本信息 -
sort_index()
参数: axis, ascending
按索引进行排序,默认是按照0轴升序
可以指定参数来实现是0/1轴,升降序df.sort_index() # 默认是0轴,升序 df.sort_index(ascending=False) # 指定0轴,降序 df.sort_index(axis=1) # 指定1轴,默认升序 df.sort_index(axis=1, ascending=False) # 指定1轴,降序 -
sort_values()
参数: by, axis, ascending
按值进行排序,默认是0轴升序
可以指定参数来实现0/1轴,升降序
另外,均需要额外指定排序基准,即按照什么值进行排序。df.sort_values(by='A') # 默认是0轴,升序,按照A列 df.sort_values(ascending=False) # 指定0轴,默认降序 df.sort_values(axis=1) # 指定1轴,升序 df.sort_values(axis=1, ascending=False) # 指定1轴,降序 -
reindex()
参数:index/columns
使用列表重新排列索引的顺序,index是0轴方向,columns是1轴方向 -
drop()
参数: value/axis
默认情况下,删除的是行,可以指定axis=1来删除列
需要注意的是,drop()返回的是一个副本,即drop命令并不会直接在原数据上修改。

-
rename()
参数:index/columns
对行或者列索引进行更改,以字典的形式,主要运用于较少的更改
当对多个索引进行更改的时候,可以使用df.columns = [...] -
value_counts()
对出现的值进行计数
这个方法只能对Series类型进行计数,DataFrame类型你只需要先选取一行或者一列不就变成Series了么。 -
字符串方法
对字符串进行处理,包括大小写变换等等。
同样只对Series有效,就是说,你需要先选取某一行或者列,在使用这个方法。

-
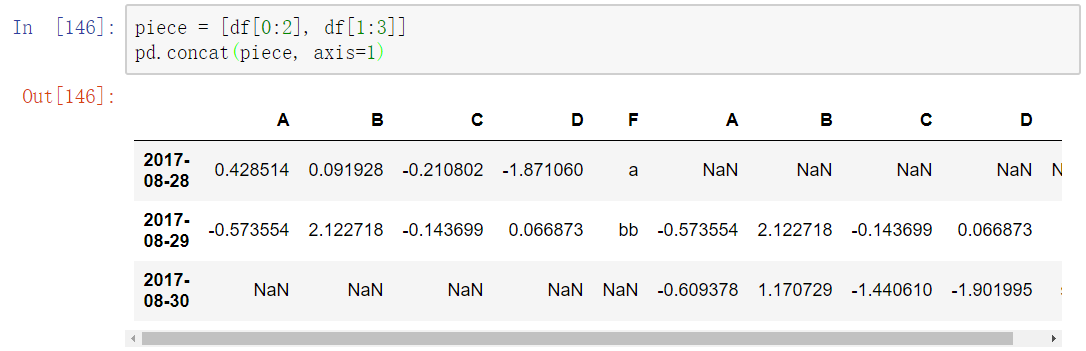
concat()
这个方法是将多组Series或者DataFrame联结,可以指定axis联结到行或者列。
默认合并到行

下面是指定axis联结到列
-
merge()
这是SQL类型的合并
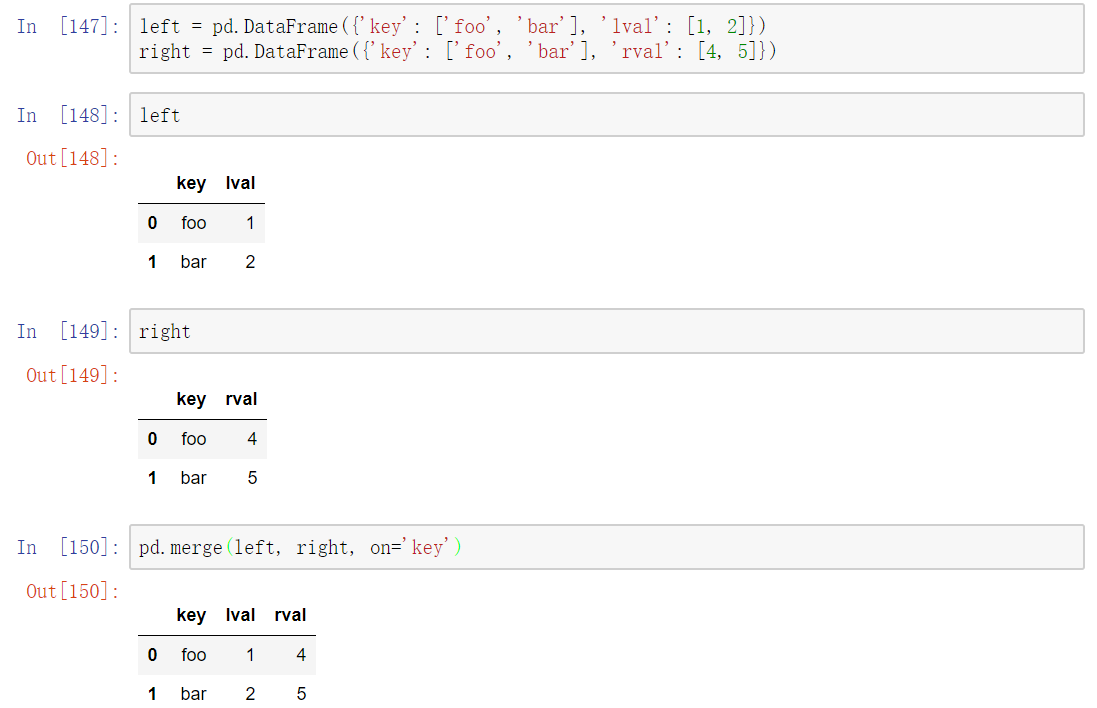
其中,on参数指定合并的基准列 -
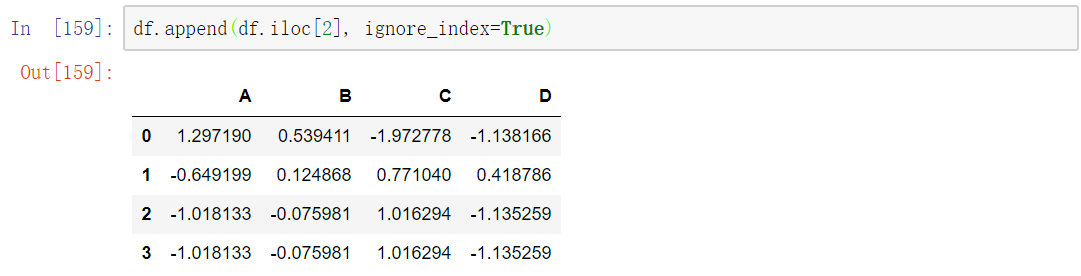
append()
在数据的后面追加
-
groupby()
分组操作 -
transform()
对分组进行转换,不会进行整体的转换,每个分组作为一个小的整体,下面的例子是使用每个分组的中位数来对当前分组进行空值填充,而不是使用整体的中位数来进行填充。features['LotFrontage'] = features.groupby("Neighborhood")["LotFrontage"].transform(lambda x:x.fillna(x.median())) -
to_datetime()
日期转换方法,将某一列转换成日期类型或者将某一个字符型的日期转换成日期格式。经过日期转换之后,便可以执行相应的日期操作。df['time'] = pd.to_datetime(df['time']) df['time'].dt.year # 获取日期里面的年份 df['time'].dt.mongth # 获取月份 df['time'].dt.day # 获取某一天 df['time'].dt.weekday_name # 获取星期几(英文) df['time'].dt.weekday # 获取周几(数字) df['time'].dt.dayofyear # 获取一年的第几天 -
date_range()
参数: 日期,periods
创建日期类型的索引

-
DatetimeIndex()
创建日期类型的索引time_index = pd.DatetimeIndex(df['time'])以上是将time这一列变成日期类型的索引,将其命名为time_index,值的注意的是,在这里,并不需要覆盖原来的index,但是依然可以使用这个日期类型的索引对原来的数据进行操作。
time_index.year # 获取年份 time_index.month # 获取月份 -
duplicated()
查看是否存在重复行,如果存在重复行,返回True,否则返回False。
如果是对Series操作,则只对Series进行重复行检查,如果是对DataFrame操作,则是对整行进行检查。可以使用下面的方法查看具体的重复行的数据。
train.loc[train.duplicated(), :]参数keep指定重复行的保留情况,可以是'first','last', False,False是将全部重复行列出。
参数subset以一个列表的形式,可以指定仅对列表出现的行,进行重复检查,比如 subset=['column1', 'column2'],意思是只对column1,column2进行重复检查。
-
drop_duplicated()
将DataFrame重复行进行删除,keep参数指定保留的行,'first', 'last'... -
get_option()
pandas的选项工具,下面是查看最大的显示行数。pd.get_option('display.max_rows')以上的方法显示最大显示的行数
-
set_option()
pandas的选项设置函数
下面是设置最大显示的行数为无,即全部显示。pd.set_option('display.max_rows', None)