一、基础环境配置
虚拟机:VMware 15.0
Linux系统版本:CentOS 6.5 (CentOS 7 的话对分布式做了优化 和7以下不同,这里以6.5为基准)
二、准备工作
1.在 /opt/install 下存放相关软件
在 /opt/models 下存放上传到服务器的工具
2.配置虚拟机的IP地址,HostName,HostMap,FireWale,Selinux,Jdk
IP地址:ifconfig 查看
vi /etc/sysconfig/network-scripts/ifcfg-eth0 设置永久的IP地址 ,如何配置,自行百度
HostName:hostname 查看
vi /etc/sysconfig/network 修改
HostMap:vi /etc/hosts 设置IP与HostName的映射关系
FireWale:service iptables status 查看防火墙的状态
chkconfig iptbles off 永久关闭防火墙
Selinux:vi /etc/selinux/config 查看与修改
修改字段:SELINUX=disabled
Jdk:ech0 $JAVA_HOME 测试java安装 返回jsva安装的路径
java/javac -Version 也可以测试java是否安装成功
三、安装Tar包与修改配置文件
1.解压缩Hadoop.tar
tar -zxvf hadoop2.5.2.tar.gz -C /opt/install # -C的意思是指定安装的路径
2.修改配置文件(6个)
①hadoop-evn.sh ,修改配置文件如下:
1 export JAVA_HOME=/usr/java/jdk1.7.0_80

②core-site.xml , 修改配置文件如下:
1 <configuration> 2 <property> 3 <name>fs.default.name</name> 4 <value>hdfs://cmx002.ai179.com:8020</value> 5 </property> 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>/opt/install/hadoop-2.5.2/data/tmp</value> 9 </property> 10 </configuration>

③hdfs-site.xml ,修改配置文件如下:
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>1</value> 5 </property> 6 </configuration>

④yarn-site.xml ,修改配置文件如下:
1 <configuration> 2 3 <property> 4 <name>yarn.nodemanager.aux-services</name> 5 <value>mapreduce_shuffle</value> 6 </property> 7 8 </configuration>

⑤mapred-site.xml ,该文件在原目录下名字为 “mapred-site.xml.template”,将“.tempalte”后缀名去掉即可,修改配置文件如下:
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 </configuration>

⑥slaves (datanode) ,修改配置文件如下:

3.格式化文件系统 hadoop_home
bin/hdfs namenode -format
成功的标志:出现 has been successfuly format ,即表示成功
4.启动Hadoop相关进程
1 sbin/hadoop-daemon.sh start namenode 2 sbin/hadoop-daemon.sh start datanode 3 sbin/yarn-daemon.sh start resourcemanager 4 sbin/yarn-daemon.sh start nodemanager
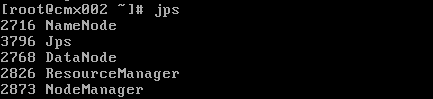
5.验证
输入jps,弹出五个进程,即表示成功
四、编写启动、停止脚本程序
在Hadoop_Home目录下,建立 hadoop-start.sh 文件,内容如下:
1 sbin/hadoop-daemon.sh start namenode 2 sbin/hadoop-daemon.sh start datanode 3 sbin/yarn-daemon.sh start resourcemanager 4 sbin/yarn-daemon.sh start nodemanager
然后,对该文件进行权限修改:chmod 744 hadoop-start.sh ,将其变为可执行文件
最后,拷贝此文件为hadoop-stop.sh,将文件中的start 全部变成 stop 即可。