Amazon DynamoDB 是一个键/值和文档数据库,可以在任何规模的环境中提供个位数的毫秒级性能。它是一个完全托管的多区域多主数据库,具有适用于 Internet 规模的应用程序的内置安全性、备份和恢复和内存缓存。DynamoDB 每天可处理超过 10 万亿个请求,并可支持每秒超过 2000 万个请求的峰值。
许多全球发展最快的企业,如 Lyft、Airbnb 和 Redfin,以及 Samsung、Toyota 和 Capital One 等企业,都依靠 DynamoDB 的规模和性能来支持其关键任务工作负载。
数十万 AWS 客户选择 DynamoDB 作为键值和文档数据库,用于其移动、Web、游戏、广告技术、物联网以及其他需要任何规模的低延迟数据访问的应用程序。为您的应用程序创建一个新表,其他的交给 DynamoDB。
DynamoDB 通过在任意规模环境中提供一致的个位数毫秒响应时间,支持世界上一些最大规模的应用程序。您可以构建吞吐量和存储空间几乎无限的应用程序。DynamoDB 全局表可跨多个 AWS 区域复制您的数据,使您能够快速在本地访问全局分布的应用程序的数据。对于需要以微秒级延迟执行更快访问的使用案例,DynamoDB Accelerator (DAX) 提供了完全托管的内存缓存。
DynamoDB 支持 ACID 事务,使您能够大规模构建业务关键型应用程序。DynamoDB 默认加密所有数据,并为您的所有表提供细粒度的身份和访问控制。您可以立即创建数百 TB 数据的完整备份,而不会对您的表性能产生影响,并且可以恢复到先前的 35 天内的任何时间点,而无需停机。DynamoDB 还提供有服务级别协议,从而确保可用性。
Amazon DynamoDB 是一个 NoSQL 数据库,它支持键-值和文档数据模型,并使开发人员能够构建无服务器的现代化应用程序,这些应用程序可以从小规模开始,然后扩展到全球范围以支持每秒数 PB 的数据和数千万条读取和写入请求。DynamoDB 可运行 Internet 规模的高性能应用程序,这些应用程序将为传统的关系数据库带来沉重的负担。
新增功能:
- 按需容量模式
- 对 ACID 事务的内置支持
- 按需备份和时间点恢复
- 静态加密
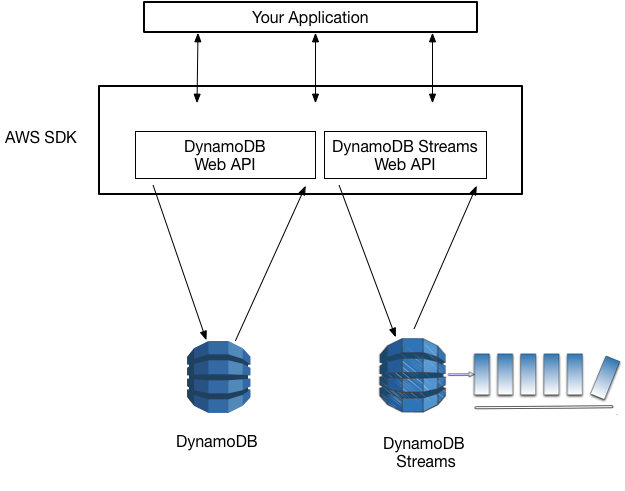
DynamoDB Streams 可在任何 DynamoDB 表中捕获按时间排序的项目级修改序列,并将这类信息存储在日志中长达 24 个小时。当存储在 DynamoDB 表中的项目发生更改时,应用程序会因能够捕获此类更改而受益。当存储在 DynamoDB 表中的项目发生更改时,许多应用程序都会因能够捕获此类更改而受益。以下是一些示例使用案例:
-
一个 AWS 区域中的一个应用程序将修改 DynamoDB 表中的数据。另一个 AWS 区域中的另一个应用程序将读取这些数据修改并将数据写入另一个表中,并创建一个与原始表保持同步的副本。
-
一个热门移动应用程序以每秒数千次更新的速率修改 DynamoDB 表中的数据。另一个应用程序捕获和存储有关这些更新的数据,并提供针对该移动应用程序的实时用量指标。
-
一种全球多人游戏具有多主机拓扑结构,并将数据存储在多个 AWS 区域中。每个主机通过使用并重放远程区域中发生的更改来保持同步。
-
一旦某个好友上传新图片,一个应用程序就会自动向群组中的所有好友的移动设备发送通知。
-
一个新客户将数据添加到 DynamoDB 表。此事件调用另一个应用程序,以便向该新客户发送欢迎电子邮件。
DynamoDB 流 支持诸如此类的解决方案以及许多其他解决方案。DynamoDB 流 在任何 DynamoDB 表中捕获按时间排序的项目级修改序列,并将此类信息存储在日志中长达 24 小时。应用程序可访问此日志并在数据项目修改前后显示时实时查看数据项目。
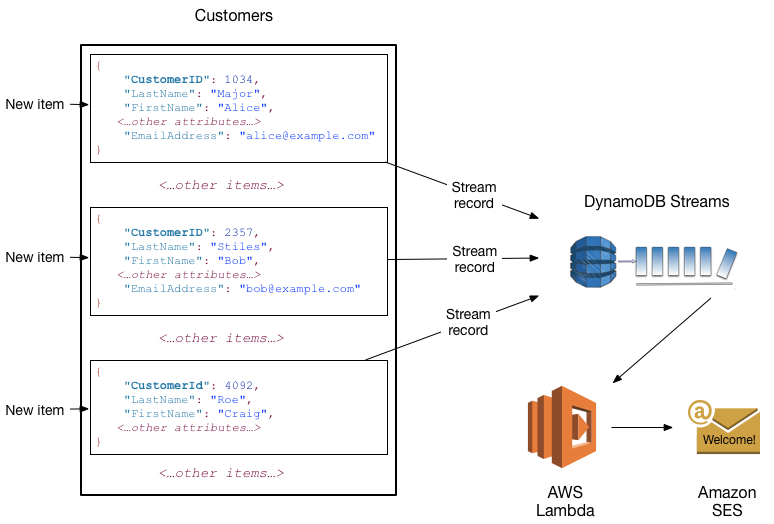
 您可以将 DynamoDB 流 与 AWS Lambda 结合使用以创建触发器 — 在流中有您感兴趣的事件出现时自动执行的代码。例如,假设有一个包含某公司客户信息的 Customers 表。假设您希望向每位新客户发送一封“欢迎”电子邮件。您可对该表启用一个流,然后将该流与 Lambda 函数关联。Lambda 函数将在新的流记录出现时执行,但只会处理添加到 Customers 表的新项目。对于具有 EmailAddress 属性的任何项目,Lambda 函数将调用 Amazon Simple Email Service (Amazon SES) 以向该地址发送电子邮件。
您可以将 DynamoDB 流 与 AWS Lambda 结合使用以创建触发器 — 在流中有您感兴趣的事件出现时自动执行的代码。例如,假设有一个包含某公司客户信息的 Customers 表。假设您希望向每位新客户发送一封“欢迎”电子邮件。您可对该表启用一个流,然后将该流与 Lambda 函数关联。Lambda 函数将在新的流记录出现时执行,但只会处理添加到 Customers 表的新项目。对于具有 EmailAddress 属性的任何项目,Lambda 函数将调用 Amazon Simple Email Service (Amazon SES) 以向该地址发送电子邮件。
最终一致性读取
当您从 DynamoDB 表中读取数据时,响应反映的可能不是刚刚完成的写入操作的结果。响应可能包含某些陈旧数据。如果您在短时间后重复读取请求,响应将返回最新的数据。
强一致性读取
当您请求强一致性读取时,DynamoDB 会返回具有最新数据的响应,从而反映来自所有已成功的之前写入操作的更新。如果网络延迟或中断,可能会无法执行强一致性读取。全局二级索引 (GSI) 不支持一致性读取。
读/写容量模式
Amazon DynamoDB 具有两个读/写容量模式来处理表的读写:
按需模式
按需 Amazon DynamoDB 是一个灵活的结算选项,可以每秒处理数千个请求而不需要进行容量规划。按需 DynamoDB 针对读写请求提供按需支付定价,以便您只需为您使用的资源付费。
在选择按需模式时,DynamoDB 会随着工作负载的增加或减少,根据之前达到的任意流量水平即时调节工作负载。如果某个工作负载的流量级别达到一个新的峰值,DynamoDB 将快速调整以适应该工作负载。使用按需模式的表可提供 DynamoDB 已经提供的相同个位数毫秒级延迟、服务等级协议 (SLA) 承诺和安全性。您可以同时对新表和现有表选择按需模式,并可以继续使用现有的 DynamoDB API 而不更改代码。
-
按需
-
预置(默认,符合免费套餐的要求)
读/写容量模式控制对读写吞吐量收费的方式以及管理容量的方式。您可以在创建表时设置读/写容量模式,也可以稍后更改。
如果满足以下任意条件,则按需模式是很好的选项:
-
您创建工作负载未知的新表。
-
您具有不可预测的应用程序流量。
-
您更喜欢只为您使用的容量付费。
预置模式
如果您选择预置模式,则指定您的应用程序需要的每秒读取和写入次数。您可以使用 Auto Scaling 根据流量变化自动调整表的预置容量。这可帮助您控制您对 DynamoDB 的使用,使之保持或低于定义的请求速率,以便获得成本可预测性。
如果满足以下任意条件,则预置模式是很好的选项:
-
您具有可预测的应用程序流量。
-
您运行流量比较稳定或逐渐增加的应用程序。
-
您可以预测容量要求以控制成本。
DynamoDB Auto Scaling
DynamoDB Auto Scaling 主动管理表和全局二级索引的吞吐容量。使用 Auto Scaling,您可以为读取和写入容量单位定义一个范围 (上限和下限)。您还可以在该范围内定义目标利用率百分比。即使在应用程序工作负载增加或减少的情况下,DynamoDB Auto Scaling 也会努力维持目标利用率。
利用 DynamoDB Auto Scaling,表或全局二级索引可以增加其预置读写容量,以处理突增流量,而不限制请求。当工作负载减少时,DynamoDB Auto Scaling 可以减少吞吐量,这样您就无需为未使用的预置容量付费。
注意
如果您使用 AWS 管理控制台创建表或全局二级索引,默认情况下将启用 DynamoDB Auto Scaling。
您可以随时使用控制台、AWS CLI 或其中一个 AWS 开发工具包管理 Auto Scaling 设置。
分区和数据分配
DynamoDB 将数据存储在分区。分区 是为表格分配的存储,由固态硬盘 (SSD) 提供支持,并可在 AWS 区域内的多个可用区中自动进行复制。分区管理由 DynamoDB 全权负责 — 您从不需要亲自管理分区。
在您创建表时,表的初始状态为 CREATING。在此期间,DynamoDB 会向表分配足够的分区,以便满足预置吞吐量需求。表的状态变为 ACTIVE 后,您可开始读取和写入表数据。
在以下情况下,DynamoDB 会向表分配额外的分区:
-
您增加的表的预置吞吐量设置超出了现有分区的支持能力。
-
现有分区填充已达到容量上限,并且需要更多的存储空间。
分区管理在后台自动进行,对程序是透明的。您的表将保留可用吞吐量并完全支持预置吞吐量需求。
数据分配:分区键
如果表具有简单主键 (只有分区键),DynamoDB 将根据其分区键值存储和检索各个项目。
DynamoDB 使用分区键的值作为内部散列函数的输入值,从而将项目写入表中。散列函数的输出值决定了项目将要存储在哪个分区。
要从表中读取某个项目,您必须为该项目指定分区键值。DynamoDB 使用此值作为其哈希函数的输入值,从而生成可从中找到该项目的分区。
下图显示了名为 Pets 的表,该表跨多个分区。表的主键为 AnimalType(仅显示此键属性)。在这种情况下,DynamoDB 会根据字符串 Dog 的哈希值,使用其哈希函数决定新项目的存储位置。请注意,项目并非按排序顺序存储的。每个项目的位置由其分区键的哈希值决定。
下表显示了关系数据库管理系统 (RDBMS) 和 DynamoDB 之间的一些高级区别:
| 特征 | 关系数据库管理系统 (RDBMS) | Amazon DynamoDB |
|---|---|---|
| 最佳工作负载 | 临时查询;数据仓库;OLAP (联机分析处理)。 | Web 规模级应用程序,包括社交网络、游戏、媒体共享和 IoT (物联网)。 |
| 数据模型 | 关系模型需要一个明确定义的架构,其中,数据将标准化为表、列和行。此外,在表、列、索引和其他数据库元素之间定义所有关系。 | DynamoDB 没有架构。每个表必须具有一个用来唯一标识每个数据项目的主键,但对其他非键属性没有类似的约束。DynamoDB 可以管理结构化或半结构化的数据,包括 JSON 文档。 |
| 数据访问 | SQL (结构化查询语言) 是存储和检索数据的标准。关系数据库提供一组丰富的工具来简化数据库驱动型应用程序的开发,但所有这些工具都使用 SQL。 | 您可以使用 AWS 管理控制台或 AWS CLI 来操作 DynamoDB 并执行临时任务。应用程序可以利用 AWS 开发工具包 (SDK),通过基于对象的、以文档为中心的或低级别的接口来操作 DynamoDB。 |
| 性能 | 关系数据库已针对存储进行优化,因此,性能通常取决于磁盘子系统。开发人员和数据库管理员必须优化查询、索引和表结构以实现最高性能。 | DynamoDB 已针对计算进行优化,因此,性能主要取决于基础硬件和网络延迟。作为一项托管服务,DynamoDB 可使您和您的应用程序免受这些实施详细信息的影响,以便您能够专注于设计和构建可靠的、高性能的应用程序。 |
| 扩展 | 利用更快的硬件进行向上扩展是最轻松的。此外,数据库表可以跨越分布式系统中的多个主机,只不过这需要额外的投资。关系数据库设定了文件数和文件大小的最大值,这将对可扩展性施加上限。 | DynamoDB 设计为使用硬件的分布式集群来向外扩展。此设计可提高吞吐量而不会增加延迟。客户指定其吞吐量要求,DynamoDB 会分配足够的资源来满足这些要求。对于每个表的项目数和表的总大小都不施加上限。 |