created_at:2020/20/23 (右下角可展开目录)
刘海龙
1.视频学习心得
在深度学习的数学基础当中,数据的特征捕捉成为了对线性代数中的矩阵作变换。因为视频中的矩阵是看作一个个的向量组成的,对矩阵做变换实则是对这些特征进行某种操作,这些操作如果对一张图片进行的话我能大概知道是对这张图片做了什么,但如果是机器学习种的某些数据,我就不清楚他到底对这些原始数据做了什么处理。看完数学基础我才知道什么叫“学好数理化,走遍天下都不怕”,深度学习当中蕴含很多的数学原理,感觉很多数学概念都学过,但从没见过这么多东西同时出现在同一个事件当中,所以想要弄懂它的底层原理恐怕得在数学上下挺大的功夫。
传统神经网络中的神经元需要处理的训练集参数量过多,会使得训练速度慢,卷积神经网络使用局部关联、参数共享的方式减少训练集的参数量。卷积这一运算更适合让机器依据卷积核获得数据特征,也便于我们编程实现。不同的卷积核对数据做卷积可以得到不同的数据特征。池化在减少参数的前提上仍能保留主要特征,可以提高模型的泛化能力,一般有最大值池化和平均池化,这个在亓琳老师的C++实验里接触过类似的图片处理方法。视频中也解释了ReLU激活函数的优越性,但还是用一堆其他我不是很懂的概念来解释的,因此还是有些疑惑。对于激活函数在深度学习当中充当着什么样的角色感到好奇。
2.问题
神经网络的层数于深度学习对数据集特征的捕捉而言有什么效益?
机器是如何处理这些获得的特征?
3.代码运行
- 卷积神经网络
对图片做了打乱像素处理
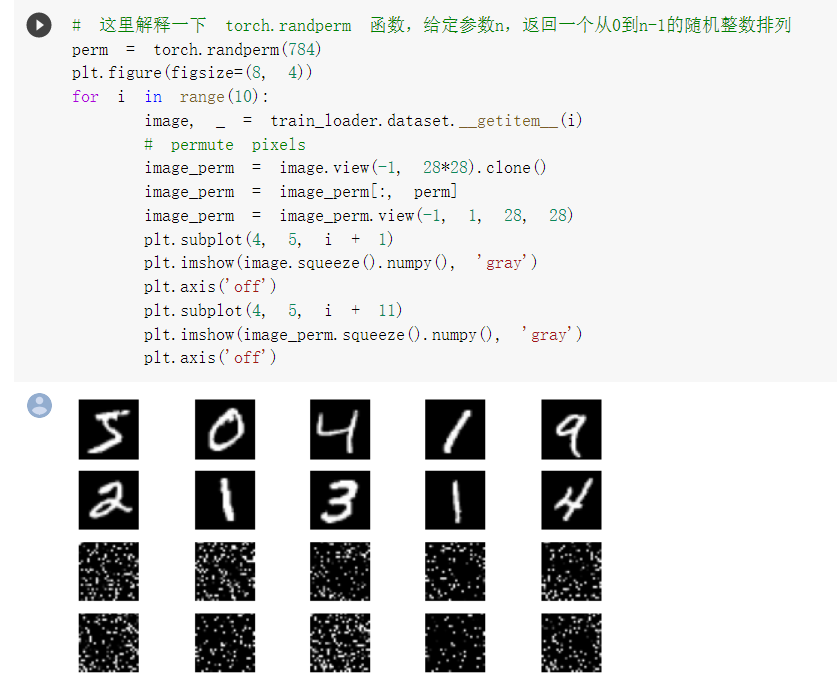
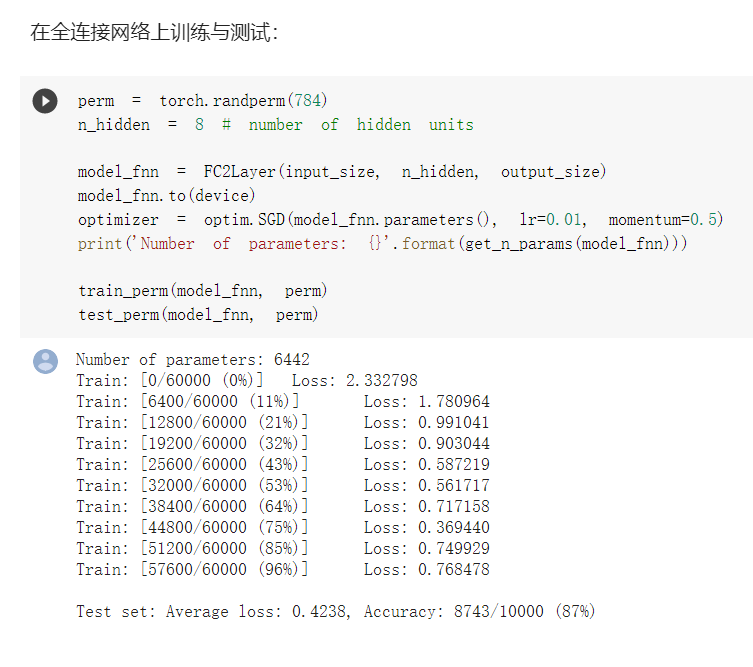
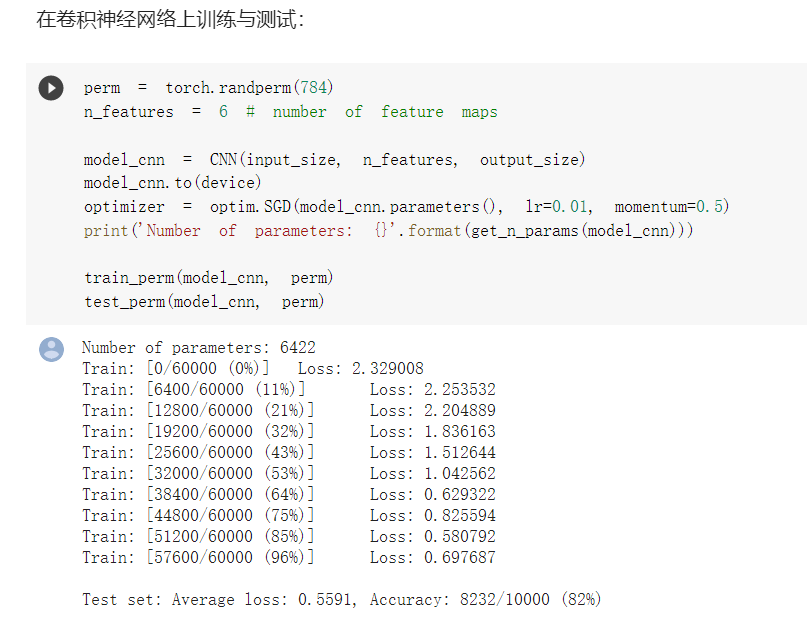
对比两次训练测试,在图片像素被打乱之后,卷积神经网络的速度明显慢了下来。因为卷积神经网络在这类像素间不存在某种关系的处理当中发挥不出优势。所以相当一部分操作是没有用的。
- CIFAR10数据分类
总体来说准确率还算可以。
- 使用 VGG16 对 CIFAR10 分类
在VGG16网络中,准确率再一步提升,但训练的速度也随之增加了。
吕晓龙
part one
第一个视频提到了深度学习的各种数学基础
首先是矩阵的特征矩阵和特征值 矩阵的秩 奇异值 等等涉及线性代数的知识
之后提到了两点设计的原理
无免费午餐原理:当考虑问题的平均性能时,任意两个模型都是相同的。
奥卡姆剃刀原理:如无必要,勿增实体。
降低模型复杂度的策略有很多种 像是使用决策树进行剪枝,使用更大的数据集,优化目标加入正则项。
第二个视频介绍了
传统神经网络和卷积神经网络区别
1.搭建神经网络结构
2.找到一个合适的损失函数(衡量吻合度)
调整参数/权重W,使得映射的结果和实际类别吻合。
交叉熵损失,均方误差
分类损失:交叉熵损失,
回归损失:MSE均方误差,MAE平均绝对值误差。
3.找到一个合适的优化函数,更新参数
反向传播,随机梯度下降
全连接网络处理图像的问题
参数过多,可能会导致过拟合
卷积神经网络的解决方式
局部关联,参数共享
一维卷积
一维卷积经常用在信号处理中,用于计算信号的延迟累积
信息的衰减率为fk,则经过k-1个时间步长后,信息衰减为原来的fk倍。
f filter被成为滤波器或者卷积核
卷积操作:对两个实变函数的一种数学操作
池化:保留了主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力
他一般处于卷积层和卷积层之间,全连接层和全连接层之间。
类型: Max pooling and Average pooling
分类任务中使用max pooling更好
经典的卷积网络是由卷积层、池化层和全连接层交叉堆叠而成的
(N-F) / stride +1
(N+padding*2-F) / stride +1
全连接通常放在卷积神经网络尾部
sigmoid函数 ReLU函数
解决了梯度消失的问题(在正区间)
计算速度特别快,只需要判断是否大于0
收敛速度远快于sigmoid
dropout 随机失活
训练时随机关闭部分神经元 测试时整合所有神经元
数据增强 平移 翻转 对称 随机crop 进行裁剪 高斯扰动
用小的卷积核代替大的卷积核
降低参数量;增加非线性激活函数:增加非线性激活函数使网络产生更多独立特征,表述能力更强,训练更快。
最后介绍了一些历史上重要的的模型
AlexNet VGG GoogleNet ResNet
提出的问题:
老师可以详细讲讲可能我们课设会用到的模型。
part two
第一部分代码
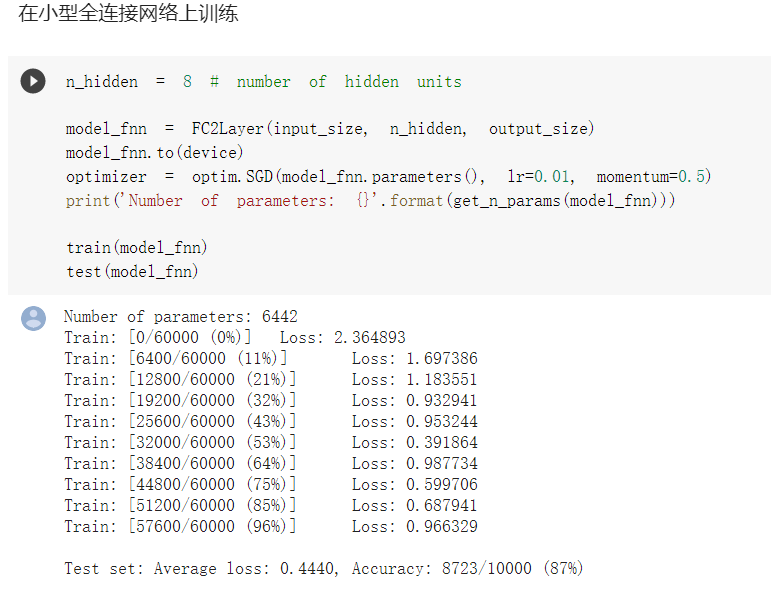
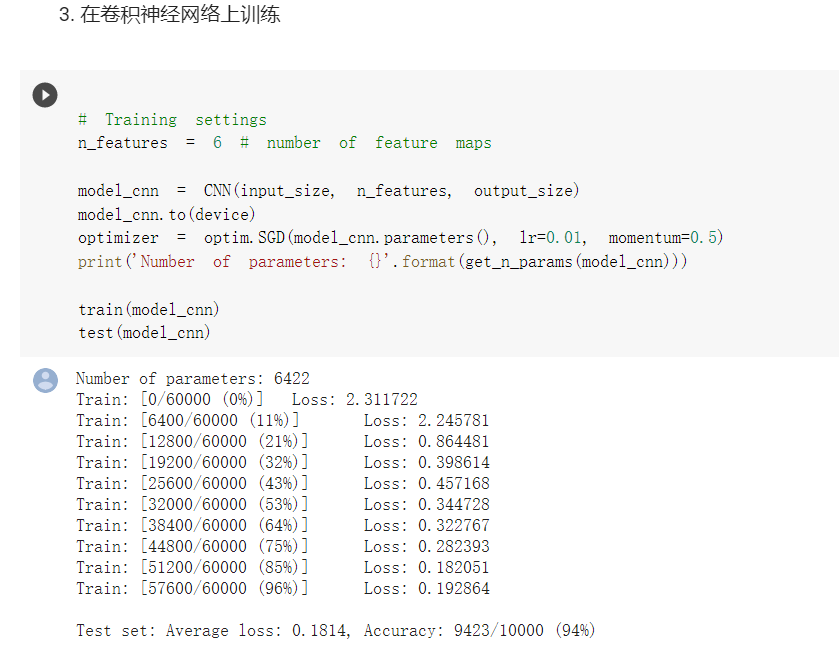
分别使用了全连接以及卷积神经网络对于同样任务的处理,结果是在参数相同的情况下,卷积神经网络得到了更好的效果,这体现了卷积网络的特点:相同情况下参数更少,而且对于过拟合等情况的处理更好。(以下部分都是先全连接,再CNN)
之后选择了打乱像素顺序再次训练和测试,打乱了像素顺序的结果是全连接和卷积神经网络得到了基本相似的结果,甚至全连接优于CNN,打乱像素实际上是为了证实卷积网络的卷积和池化的重要作用。
第二部分代码
主要给我们介绍了对于视觉网络,pytorch提供的数据集,其中著名的应该是Imagenet,MNIST等
这次主要使用了CIFA10,同时进行了数据的归一化
在导入数据后,开始具体的模型的构筑,其实pytorch给我们的便利性以及很好了,我们没有必要自己写很多的代码,更多地像是拼凑各个函数,网络,损失函数和优化器等等。经过训练后我们得到了CNN的实验结果。可以发现其实只是单纯的CNN效果不是很好。
第三部分代码
使用了简化过后的VGG
仍然是做的识别任务,基本代码和第二部分相似,只是更改了模型。
实验结果是VGG的识别正确率大大提高。
写代码遇到的错误:
1.调用函数 torch.utils.data.DataLoader() 参数num_workers设置为2,但是会导致进程打架,虽然我也不知是为什么,可能是本地运行的原因?但是参数恢复为默认的0就可以正常运行。
2.应该不是我的问题 老师写错了? 应该最后的全连接层要设置为(512,10)
一开始的(2048,10)有一些问题,训练的时候报错mismatch。
马良吉
视频学习心得及问题总结
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,可以解决由于网络深度增加导致的参数量增加的问题,使得神经网络更加容易的应用到现实场景中。
CNN的出现减少了参数量同时也减少了全连接层的数量(两个左右)。CNN对参数量的减少体现在卷积和Pooling部分,利用卷积层代替全连接层、利用卷积共享权值。
池化层的主要作用是下采样,通过去掉特征图中不重要的样本,进一步减少参数数量。常用平均池化和最大池化。
代码练习

宋江
视频
玻尔兹曼机的理论和应用意义
网络拓扑结构优化
非线性优化过程近似
自编码器变种
正则自编码器:使提取特征表达符合某种特质
稀疏自编码器:提取稀疏特征表达
去噪自编码器:提取鲁棒特征表达
变分自编码器
深层网络的局部极小值主要是由于多个隐层符合导致
低秩近似的意义:保留决定信息分布的最主要的模式/方向(图像去噪)
机器学习从有限的观测数据中学习出规律,并将总结的规律推广到未观测样本上,表现为追求泛化性能。机器学习的目的就是获得足够小的泛化误差。
通过训练误差判别泛化误差,最终目的是达到训练误差小,泛化误差小。
如果对于模型一般性质没有学习好,则是欠拟合;如果对于模型的特点当成一般化学习,则是过拟合。
欠拟合需要提高模型复杂度,过拟合需要降低模型复杂度。
卷积神经网络
基本应用:分类,检索,检测,分割
深度学习:搭建神经网络结构,找到合适的损失函数,找到合适的优化函数
卷积神经网络可以解决全连接网络处理图像由于参数过多而导致的过拟合的问题。
解决方式:局部关联,参数共享
池化:保留主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力
AlexNet
解决了梯度消失的问题
计算速度特别快,只需要判断输入是否大于零
收敛速度远快于sigmoid
代码
将像素打乱之后,卷积和池化难以发挥作用。全连接网络的性能基本上没有发生变化。
正常:

打乱:

全连接网络:

电脑配置原因导致62%准确率?应该可以通过算法改变。

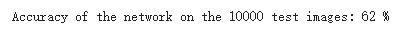

余泽芃
1. 视频学习
(1) 深度学习的数学基础
关于深度学习的数学原理包括线性代数,概率统计,微积分。数学原理好多没怎么听懂,后面会好好的再看一遍。
(2) 卷积精神网络
· CNN的基本结构
· 卷积
通过卷积操作对输入图像进行降维和特征抽取。卷积运算是线性操作,可以捕捉图像的局部、 细节信息,即输出图像每个像素。无论输入图片多大,卷积的参数都是固定的。
· 池化
池化是对图像的某一个区域用一个值代替,如最大值或平均值。如采用最大值就是max池化,如采用均值就是均值池化。池化可以降维,缩减模型大小,提高计算速度。池化也可以降低过拟合概率,提升特征提取鲁棒性。
· 全连接
全连接就是个矩阵乘法,相当于一个特征空间变换,可以把前面所有有用的信息提取整合。全连接的一个作用是维度变换,尤其是可以把高维变到低维,同时把有用的信息保留下来。全连接另一个作用是隐含语义的表达,把原始特征映射到各个隐语义节点。
· 典型网络结构
· AlexNet
AlexNet 包含八层前五层是卷积层,之后一些层[最大池化层,最后三层是全连接层。
· VGG
运用小卷积核,小池化核和全连接转卷积。
· GoogleNet
inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
· ResNet
ResNet是一种残差网络,咱们可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。
2. 代码练习
· MNIST 数据集分类
PyTorch里包含了 MNIST, CIFAR10 等常用数据集,调用 torchvision.datasets 即可把这些数据由远程下载到本地。
input_size = 28*28 # MNIST上的图像尺寸是 28x28
output_size = 10 # 类别为 0 到 9 的数字,因此为十类
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=1000, shuffle=True)
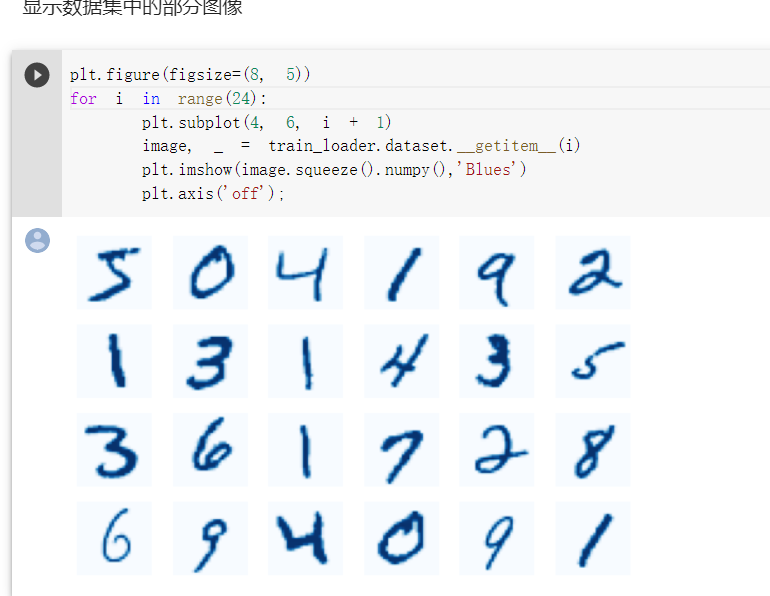
显示数据集中的图像。
plt.figure(figsize=(8, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
image, _ = train_loader.dataset.__getitem__(i)
plt.imshow(image.squeeze().numpy(),'gray')
plt.axis('off');

实验中每张图片大小是28*28像素,黑色像素值为0,白色像素值为1,数据集是长度为10的一维数组。将数据集输入神经网络,然后显示数据集中的图像。
· CIFAR10 数据集分类
下面将使用CIFAR10数据集,它包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。CIFAR-10 中的图像尺寸为3x32x32,也就是RGB的3层颜色通道,每层通道内的尺寸为32*32。
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false
# 训练时可以打乱顺序增加多样性,测试是没有必要
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
展示CIFAR10的图片
def imshow(img):
plt.figure(figsize=(8,8))
img = img / 2 + 0.5 # 转换到 [0,1] 之间
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 得到一组图像
images, labels = iter(trainloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示第一行图像的标签
for j in range(8):
print(classes[labels[j]])

定义网络,损失函数和优化器
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
训练网络
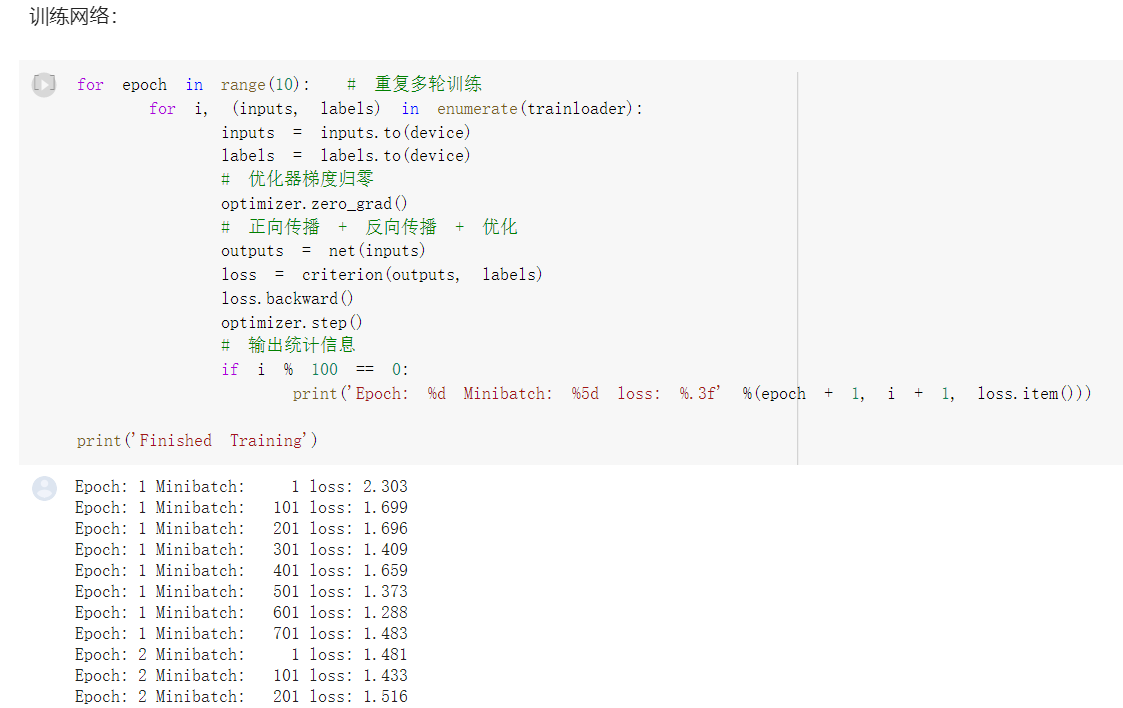
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.301
Epoch: 1 Minibatch: 101 loss: 1.736
Epoch: 1 Minibatch: 201 loss: 1.715
Epoch: 1 Minibatch: 301 loss: 1.528
Epoch: 1 Minibatch: 401 loss: 1.760
Epoch: 1 Minibatch: 501 loss: 1.489
Epoch: 1 Minibatch: 601 loss: 1.461
Epoch: 1 Minibatch: 701 loss: 1.448
Epoch: 2 Minibatch: 1 loss: 1.517
Epoch: 2 Minibatch: 101 loss: 1.212
Epoch: 2 Minibatch: 201 loss: 1.493
Epoch: 2 Minibatch: 301 loss: 1.225
Epoch: 2 Minibatch: 401 loss: 1.395
Epoch: 2 Minibatch: 501 loss: 1.470
Epoch: 2 Minibatch: 601 loss: 1.158
Epoch: 2 Minibatch: 701 loss: 1.041
Epoch: 3 Minibatch: 1 loss: 1.225
Epoch: 3 Minibatch: 101 loss: 1.157
Epoch: 3 Minibatch: 201 loss: 1.248
Epoch: 3 Minibatch: 301 loss: 1.205
Epoch: 3 Minibatch: 401 loss: 1.393
Epoch: 3 Minibatch: 501 loss: 1.234
Epoch: 3 Minibatch: 601 loss: 1.344
Epoch: 3 Minibatch: 701 loss: 1.163
Epoch: 4 Minibatch: 1 loss: 1.099
Epoch: 4 Minibatch: 101 loss: 1.243
Epoch: 4 Minibatch: 201 loss: 1.413
Epoch: 4 Minibatch: 301 loss: 1.206
Epoch: 4 Minibatch: 401 loss: 1.371
Epoch: 4 Minibatch: 501 loss: 1.251
Epoch: 4 Minibatch: 601 loss: 1.183
Epoch: 4 Minibatch: 701 loss: 1.012
Epoch: 5 Minibatch: 1 loss: 0.975
Epoch: 5 Minibatch: 101 loss: 1.119
Epoch: 5 Minibatch: 201 loss: 1.119
Epoch: 5 Minibatch: 301 loss: 1.233
Epoch: 5 Minibatch: 401 loss: 0.873
Epoch: 5 Minibatch: 501 loss: 0.997
Epoch: 5 Minibatch: 601 loss: 1.028
Epoch: 5 Minibatch: 701 loss: 0.788
Epoch: 6 Minibatch: 1 loss: 1.099
Epoch: 6 Minibatch: 101 loss: 1.001
Epoch: 6 Minibatch: 201 loss: 0.876
Epoch: 6 Minibatch: 301 loss: 1.037
Epoch: 6 Minibatch: 401 loss: 0.948
Epoch: 6 Minibatch: 501 loss: 0.882
Epoch: 6 Minibatch: 601 loss: 1.043
Epoch: 6 Minibatch: 701 loss: 1.092
Epoch: 7 Minibatch: 1 loss: 0.974
Epoch: 7 Minibatch: 101 loss: 0.847
Epoch: 7 Minibatch: 201 loss: 0.834
Epoch: 7 Minibatch: 301 loss: 0.795
Epoch: 7 Minibatch: 401 loss: 0.964
Epoch: 7 Minibatch: 501 loss: 1.221
Epoch: 7 Minibatch: 601 loss: 1.013
Epoch: 7 Minibatch: 701 loss: 0.964
Epoch: 8 Minibatch: 1 loss: 0.936
Epoch: 8 Minibatch: 101 loss: 0.992
Epoch: 8 Minibatch: 201 loss: 0.905
Epoch: 8 Minibatch: 301 loss: 0.927
Epoch: 8 Minibatch: 401 loss: 1.057
Epoch: 8 Minibatch: 501 loss: 0.898
Epoch: 8 Minibatch: 601 loss: 0.899
Epoch: 8 Minibatch: 701 loss: 0.778
Epoch: 9 Minibatch: 1 loss: 0.982
Epoch: 9 Minibatch: 101 loss: 0.925
Epoch: 9 Minibatch: 201 loss: 1.224
Epoch: 9 Minibatch: 301 loss: 0.544
Epoch: 9 Minibatch: 401 loss: 0.983
Epoch: 9 Minibatch: 501 loss: 0.961
Epoch: 9 Minibatch: 601 loss: 0.761
Epoch: 9 Minibatch: 701 loss: 0.981
Epoch: 10 Minibatch: 1 loss: 1.051
Epoch: 10 Minibatch: 101 loss: 0.761
Epoch: 10 Minibatch: 201 loss: 0.904
Epoch: 10 Minibatch: 301 loss: 1.213
Epoch: 10 Minibatch: 401 loss: 0.942
Epoch: 10 Minibatch: 501 loss: 0.804
Epoch: 10 Minibatch: 601 loss: 1.043
Epoch: 10 Minibatch: 701 loss: 0.804
Finished Training
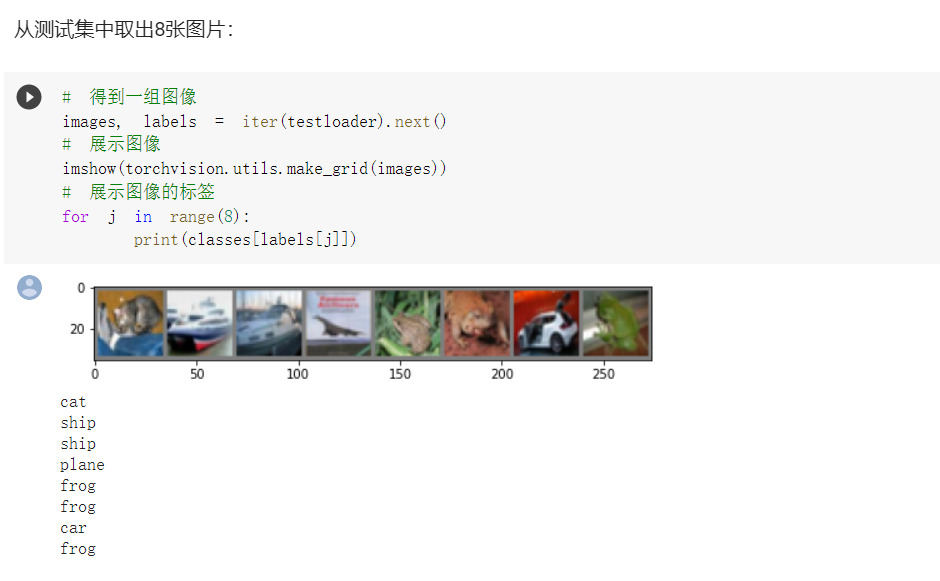
取出测试集中的8张图片
# 得到一组图像
images, labels = iter(testloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示图像的标签
for j in range(8):
print(classes[labels[j]])

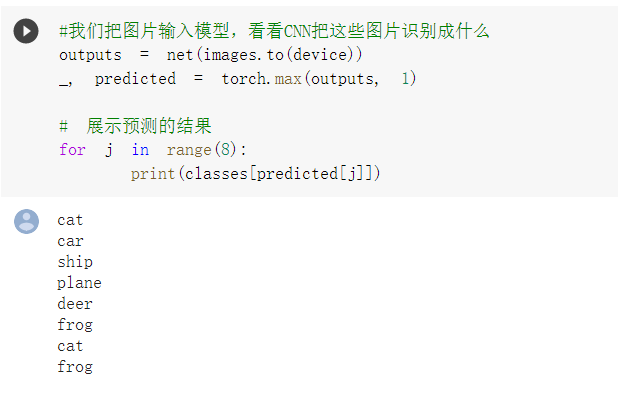
把图片输入模型,再看 CNN 将图像识别成什么
outputs = net(images.to(device))
_, predicted = torch.max(outputs, 1)
# 展示预测的结果
for j in range(8):
print(classes[predicted[j]])

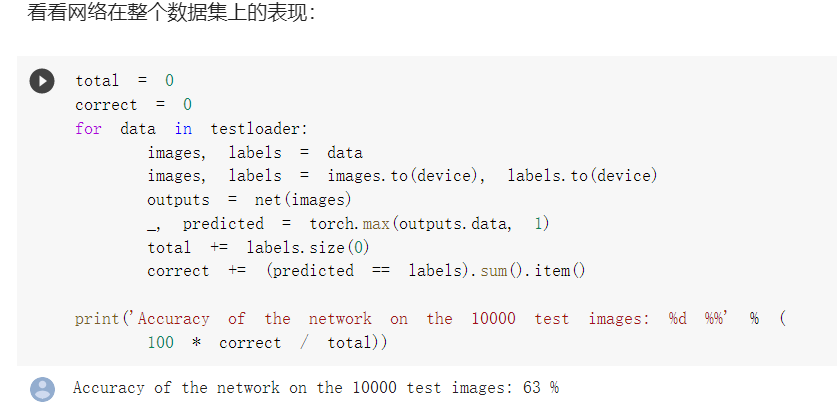
看看网络在整个数据集的表现。
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))

CIFAR10 数据集是用于识别物体的小型数据集,有10类 RGB 图像。通过训练网络来识别数据集中图像的种类。
· VGG16对CIFAR10分类
1. 定义 dataloader
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
2. VGG 网络定义
class VGG(nn.Module):
def __init__(self):
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(cfg)
self.classifier = nn.Linear(512, 10)
# self.classifier = nn.Linear(2048, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
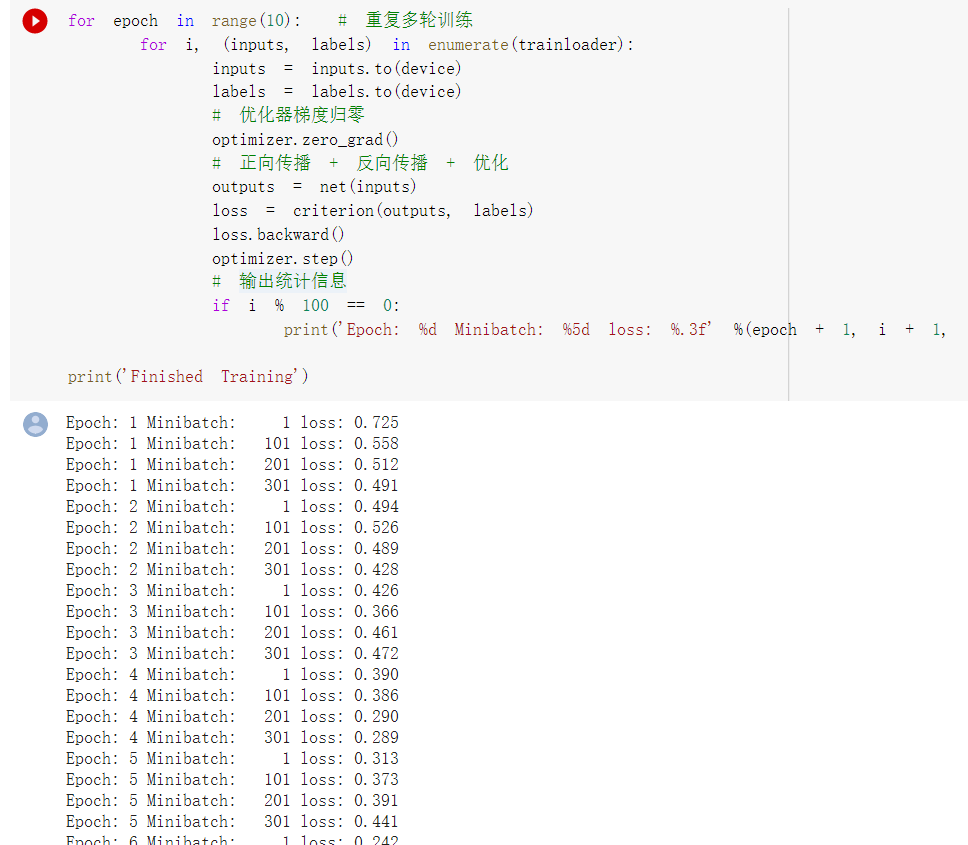
3. 网络训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.391
Epoch: 1 Minibatch: 101 loss: 1.397
Epoch: 1 Minibatch: 201 loss: 1.511
Epoch: 1 Minibatch: 301 loss: 1.057
Epoch: 2 Minibatch: 1 loss: 1.110
Epoch: 2 Minibatch: 101 loss: 0.884
Epoch: 2 Minibatch: 201 loss: 0.878
Epoch: 2 Minibatch: 301 loss: 0.749
Epoch: 3 Minibatch: 1 loss: 0.821
Epoch: 3 Minibatch: 101 loss: 0.764
Epoch: 3 Minibatch: 201 loss: 0.742
Epoch: 3 Minibatch: 301 loss: 0.854
Epoch: 4 Minibatch: 1 loss: 0.726
Epoch: 4 Minibatch: 101 loss: 0.671
Epoch: 4 Minibatch: 201 loss: 0.605
Epoch: 4 Minibatch: 301 loss: 0.508
Epoch: 5 Minibatch: 1 loss: 0.575
Epoch: 5 Minibatch: 101 loss: 0.656
Epoch: 5 Minibatch: 201 loss: 0.570
Epoch: 5 Minibatch: 301 loss: 0.555
Epoch: 6 Minibatch: 1 loss: 0.624
Epoch: 6 Minibatch: 101 loss: 0.623
Epoch: 6 Minibatch: 201 loss: 0.792
Epoch: 6 Minibatch: 301 loss: 0.551
Epoch: 7 Minibatch: 1 loss: 0.510
Epoch: 7 Minibatch: 101 loss: 0.528
Epoch: 7 Minibatch: 201 loss: 0.431
Epoch: 7 Minibatch: 301 loss: 0.483
Epoch: 8 Minibatch: 1 loss: 0.446
Epoch: 8 Minibatch: 101 loss: 0.511
Epoch: 8 Minibatch: 201 loss: 0.551
Epoch: 8 Minibatch: 301 loss: 0.489
Epoch: 9 Minibatch: 1 loss: 0.434
Epoch: 9 Minibatch: 101 loss: 0.621
Epoch: 9 Minibatch: 201 loss: 0.443
Epoch: 9 Minibatch: 301 loss: 0.368
Epoch: 10 Minibatch: 1 loss: 0.378
Epoch: 10 Minibatch: 101 loss: 0.357
Epoch: 10 Minibatch: 201 loss: 0.551
Epoch: 10 Minibatch: 301 loss: 0.413
Finished Training
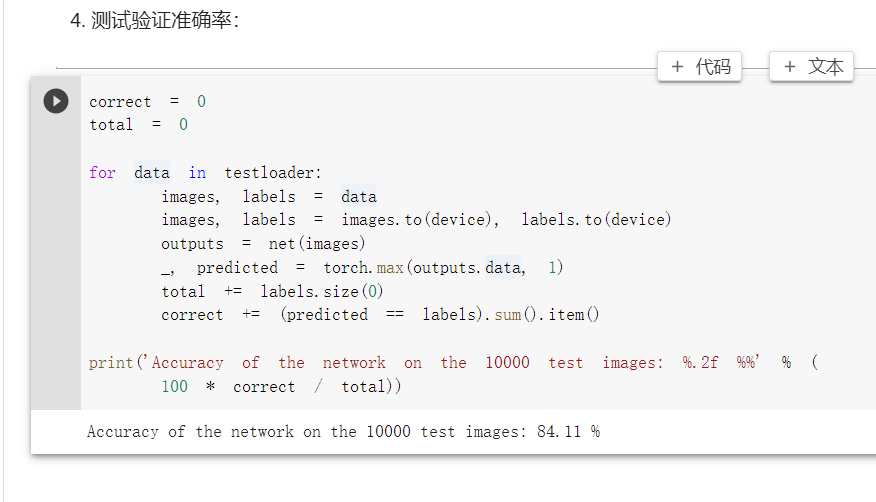
4. 测试验证准确率
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))

VGG 用连续 3*3 小卷积来代替较大卷积核,提升了网络的深度,带来了较大程度的增益,但参数量需要更大的存储空间来存储。
这次学习了深度学习的数学原理,还有一些没有怎么弄明白,之后还要在好好看看,还学习了各种深度学习的模型,了解了深度学习相关的代码。从现在开始就开始慢慢的学习深度学习的相关知识了。