关键词:
DMA: Direct Memory Access
零拷贝实现:依赖 Linux操作系统 sendfile System Call
Java支持零拷贝的方法 Transferto()
适用场景
Many Web applications serve a significant amount of static content, which amounts to reading data off of a disk and writing the exact same data back to the response socket. This activity might appear to require relatively little CPU activity, but it’s somewhat inefficient: the kernel reads the data off of disk and pushes it across the kernel-user boundary to the application, and then the application pushes it back across the kernel-user boundary to be written out to the socket. In effect, the application serves as an inefficient intermediary that gets the data from the disk file to the socket.
Each time data traverses the user-kernel boundary, it must be copied, which consumes CPU cycles and memory bandwidth. Fortunately, you can eliminate these copies through a technique called — appropriately enough —zero copy. Applications that use zero copy request that the kernel copy the data directly from the disk file to the socket, without going through the application. Zero copy greatly improves application performance and reduces the number of context switches between kernel and user mode.
The Java class libraries support zero copy on Linux and UNIX systems through the transferTo() method in java.nio.channels.FileChannel. You can use the transferTo() method to transfer bytes directly from the channel on which it is invoked to another writable byte channel, without requiring data to flow through the application. This article first demonstrates the overhead incurred by simple file transfer done through traditional copy semantics, then shows how the zero-copy technique using transferTo() achieves better performance.
应用产品:
Kafka:通常情况下,Kafka的消息会有多个订阅者,生产者发布的消息会被不同的消费者多次消费,为了优化这个流程,Kafka使用了“零拷贝技术”; 如果有10个消费者,传统方式下,数据复制次数为4*10=40次,而使用“零拷贝技术”只需要1+10=11次,一次为从磁盘复制到页面缓存,10次表示10个消费者各自读取一次页面缓存。
Date transfer:传统方案

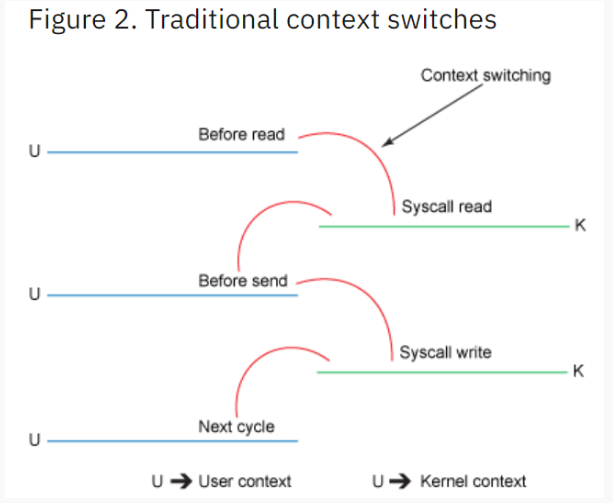
1、The read() call causes a context switch (see Figure 2) from user mode to kernel mode. Internally a sys_read() (or equivalent) is issued to read the data from the file. The first copy (see Figure 1) is performed by the direct memory access (DMA) engine, which reads file contents from the disk and stores them into a kernel address space buffer.
2、The requested amount of data is copied from the read buffer into the user buffer, and the read() call returns. The return from the call causes another context switch from kernel back to user mode. Now the data is stored in the user address space buffer.
3、The send() socket call causes a context switch from user mode to kernel mode. A third copy is performed to put the data into a kernel address space buffer again. This time, though, the data is put into a different buffer, one that is associated with the destination socket.
4、The send() system call returns, creating the fourth context switch. Independently and asynchronously, a fourth copy happens as the DMA engine passes the data from the kernel buffer to the protocol engine.
传统的读取文件数据并发送到网络的步骤如下:
(1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存;
(2)应用程序将数据从内核空间读入用户空间缓冲区;
(3)应用程序将读到数据写回内核空间并放入socket缓冲区;
(4)操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送。
(1)操作系统将数据从磁盘文件中读取到内核空间的页面缓存;
(2)应用程序将数据从内核空间读入用户空间缓冲区;
(3)应用程序将读到数据写回内核空间并放入socket缓冲区;
(4)操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络发送。
Use of the intermediate kernel buffer (rather than a direct transfer of the data into the user buffer) might seem inefficient. But intermediate kernel buffers were introduced into the process to improve performance. Using the intermediate buffer on the read side allows the kernel buffer to act as a “readahead cache” when the application hasn’t asked for as much data as the kernel buffer holds. This significantly improves performance when the requested data amount is less than the kernel buffer size. The intermediate buffer on the write side allows the write to complete asynchronously.
Unfortunately, this approach itself can become a performance bottleneck if the size of the data requested is considerably larger than the kernel buffer size. The data gets copied multiple times among the disk, kernel buffer, and user buffer before it is finally delivered to the application.
Zero copy improves performance by eliminating these redundant data copies.
2、零拷贝方案
If you re-examine the traditional scenario, you’ll notice that the second and third data copies are not actually required.
The transferTo() method transfers data from the file channel to the given writable byte channel. Internally, it depends on the underlying operating system’s support for zero copy; in UNIX and various flavors of Linux, this call is routed to the sendfile() system call, shown in Listing 3, which transfers data from one file descriptor to another:
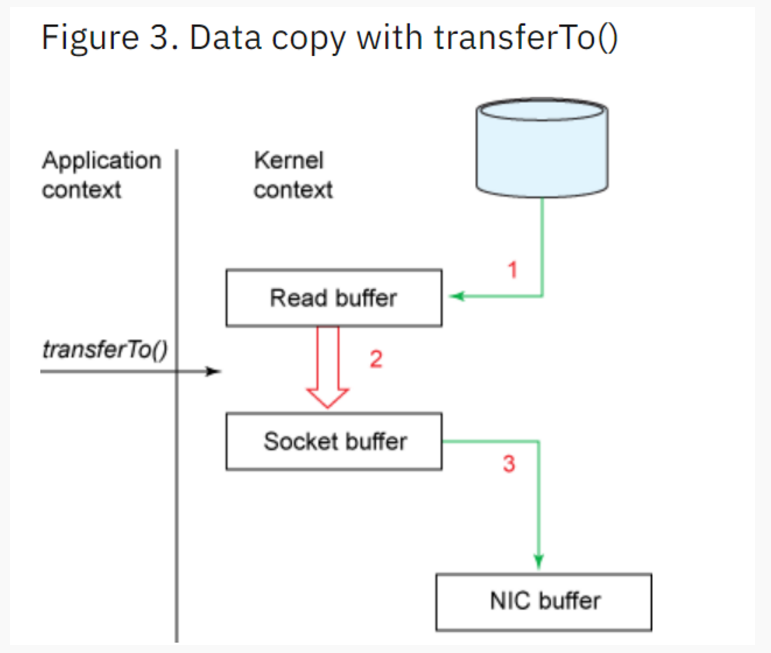
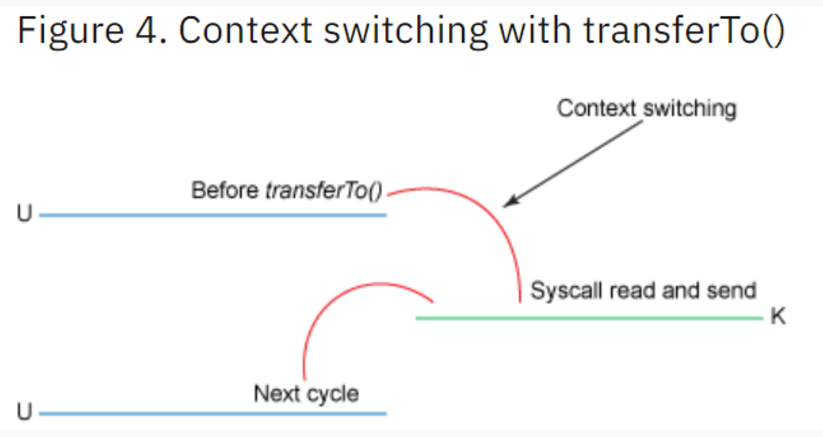
上下文切换数量从4次到2次;数据拷贝次数从4次到3次
1、The transferTo() method causes the file contents to be copied into a read buffer by the DMA engine. Then the data is copied by the kernel into the kernel buffer associated with the output socket.
2、The third copy happens as the DMA engine passes the data from the kernel socket buffers to the protocol engine.
But this does not yet get us to our goal of zero copy.
3、更优方案

We can further reduce the data duplication done by the kernel if the underlying network interface card supports gather operations. In Linux kernels 2.4 and later, the socket buffer descriptor was modified to accommodate this requirement. This approach not only reduces multiple context switches but also eliminates the duplicated data copies that require CPU involvement
1、The transferTo() method causes the file contents to be copied into a kernel buffer by the DMA engine.
2、No data is copied into the socket buffer. Instead, only descriptors with information about the location and length of the data are appended to the socket buffer. The DMA engine passes data directly from the kernel buffer to the protocol engine, thus eliminating the remaining final CPU copy.
“零拷贝技术”只用将磁盘文件的数据复制到页面缓存中一次,然后将数据从页面缓存直接发送到网络中(发送给不同的订阅者时,都可以使用同一个页面缓存),避免了重复复制操作。
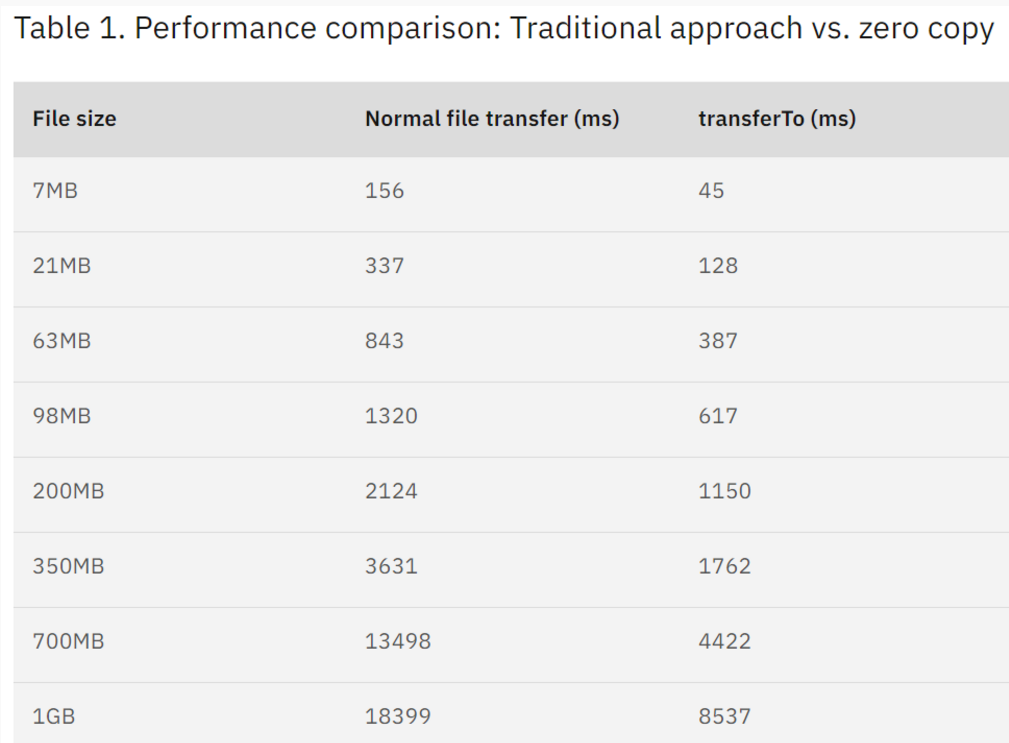
4、采用零拷贝效率对比