数据类型
-
string
- 创建:
tmp=' ' / tmp=str(a)
- 切片:
a ='abcde'
a[0:3] 表示取下标 0-2 的字符 左闭右开
a[0:3:1] 表示取下标0-2的字符,步长为1
- 常见操作:
![[图片上传中...(-39165d-1560650555924-0)]](https://upload-images.jianshu.io/upload_images/11743438-ef73d7f576daa266.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)


- 循环遍历
字符串的遍历将会是把字符串拆分成最小单位
- 转义字符串

- 备注
- 中文字符串处理:
在网络上发送字符串时要求必须转换成(bytes)形式,用字符串的encode()方法,返回值是字节串(bytes)
encode(encoding = 'utf-8',errors = 'strict')
encoding 默认编码为utf-8,其他还有gbk,gb2312
errors编码错误的处理方式,默认为strict(报错),也可以是ignore,replace
反之,从网络上接收到的字符串(bytes)若为字符串,则要使用字节串(bytes)的decode方法来解码,才能看到原来的字符串
decode(encoding = 'utf-8',errors='strict')
编码解码时要一致,否则不能还原或者报错
bytes = str.encode()
str = bytes.decode()
- 当py脚本中有中文数据,不能执行时,需要在文件头声明:
# coding=gbk

-
字符串填充
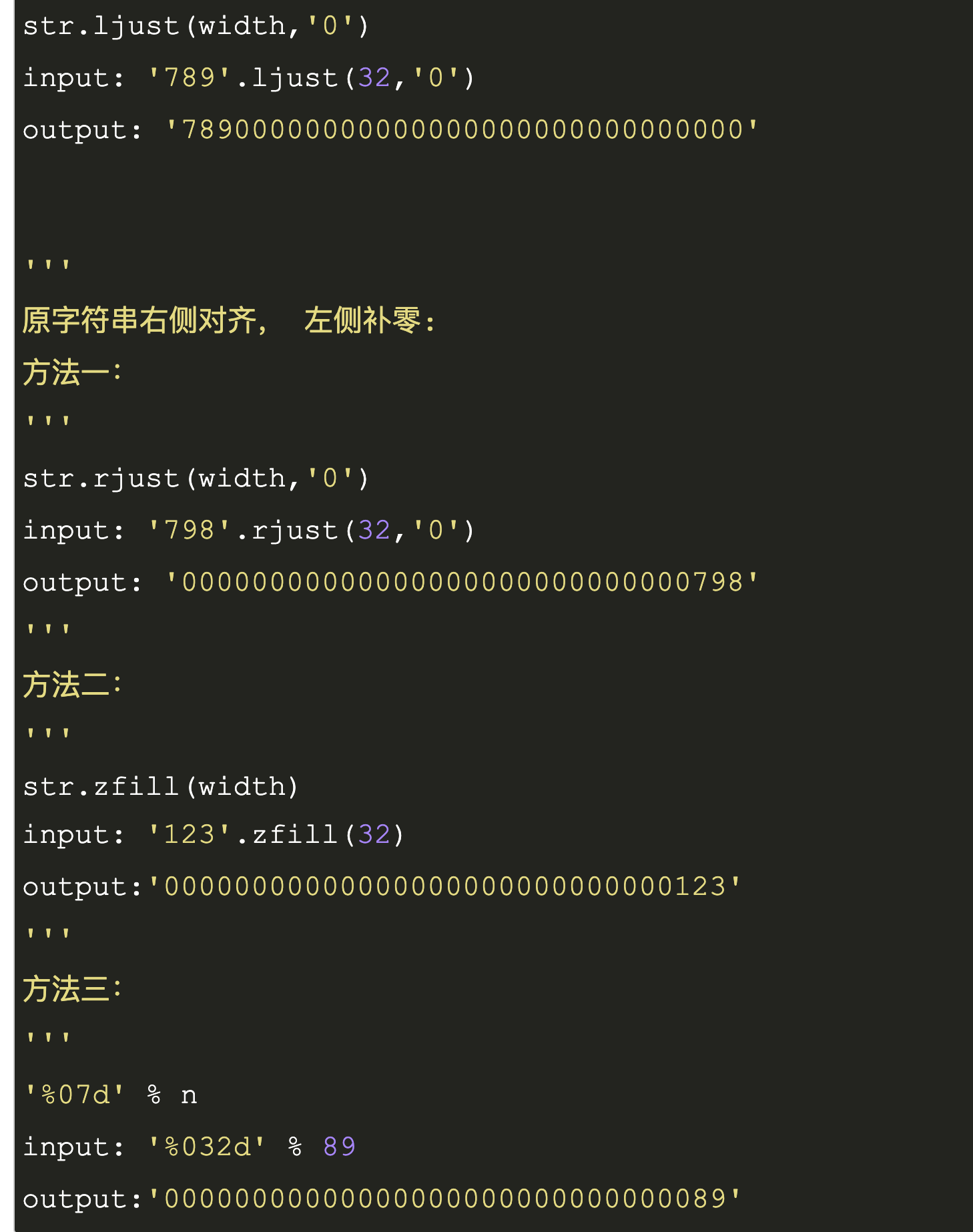
-
list
- 创建
a = list() a = [ ] (列表中的元素可以使不同类型的)
- 常用操作
问题:

a = [1,2,3,4,5,6]
print(a)
for i in a:
if i > 3:
a.remove(i)
print(a)
输出:
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 5]
按照正常理解,大于3的数据对象是要在列表中删除的,但是输出内容中还存在了5,5小于3?不可能,
原因:在数据对象遍历到4的时候,列表执行了remove函数,删除了4,列表中的元素就只剩下了 12356,原来是有6个元素,现在只有5个,但是for是按照数据索引走的,原来4的索引是3,for在遍历过3之后,是要遍历4的,但是在删除了4之后,5成了列表中的索引(3),for就把5给跳了过去,直接遍历到了元素6,然后在删除了4 6。剩下了5
要达到设想中的目的,从索引做文章,或者列表拷贝。
2019年12月22日23:04:23
可以使用列表的反转来实现
a = [1,2,3,4,5,6]
print(a)
for i in a[::-1]:
if i > 3:
a.remove(i)
print(a)
[1,2,3]
为啥?
- 列表的嵌套
import random
#三个空教室
offices = [[],[],[]]
#八个老师
names = [a,b,c,d,e,f,g,h,]
i = 0
for name in names:
index = random.randint(0,2)
offices[index].append(name)
i=1
for tempNames in offices:
print('办公室%d的人数为:%d' % (i ,len(tempNames)))
i+=1
for name in tempNames:
print('%d'name)
- 备注
- 列表的乘法
[1]*5 ->[1,1,1,1,1]
-列表推导式
[ <i相关表达式> for i in xx]
[i*2 for i in range(4)]
[0, 2, 4, 6]
用循环变量i去遍历xx,将i相关表达式的值放入到一个列表中
xx:可遍历的对象,列表,元组,range函数
-
dict
- 创建
a={a:b,b:2} a = {}
特点:

- 常用方法:

普通创建字典的方法
users = dict(zhang=10000,wang=10000,li=10000,zhao=10000)
更优雅的方式
names=["rr","ee,"ww","qq"]
user1.dict().formatkeys(names,10000)
获取字典的值
a={'a':1,'b':'to','c':'63'}
a['b']
>>> output: to
"""
上面的这种value值获取方式较为常见,但如果a中没有b,
或者在字典的使用过程中b 这个key被del了呢?
这是会报一个KeyError的错误,所以养成好习惯,使用下面的方式
当key值不存在时,返回none,或者自定义一个默认值。
"""
a.get('b',[default_no可选...])
更新与删除
# 更新
a={'a':1,'b':'to','c':'63'}
a.update('a':2)
a.update(a=2) # 这种方式同样适用与更新操作
# 删除某个键值对
del a['a']
pop('a')
"""
两者都可以达到删除某个键值对的操作,
但后者相当于去除后删除,具备返回值
"""
del a 删除字典a
a.clear()清空字典a
has_key操作
"""
python2中,判断字典是否存在某个值,可以使用has_key('key'),
但在python3中取消了该参数,如果我们想判断可以使用以下方式:
"""
a={'a':1,'b':'to','c':'63'}
'b' in a.keys()
a.__contains__('b')
字典的enumerate
a = {'a': 1, 'b': 'to', 'c': '63'}
for line, item in enumerate(a.items(), start=1):
print("[{}] {} --> {}".format(line, *item))
>>> output:
"""
[1] a --> 1
[2] b --> to
[3] c --> 63
"""
- 循环遍历

- 有序字典
某些时候我们需要保持dict的有序型,这时候可以使用OrderedDict,这是一个dict的子类
>>> from collections import OrderedDict
# 无序的dict
>>> d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
# 将d按照key来排序
>>> OrderedDict(sorted(d.items(), key=lambda t: t[0]))
OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1)])
# 将d按照value来排序
>>> OrderedDict(sorted(d.items(), key=lambda t: t[1]))
OrderedDict([('pear', 1), ('orange', 2), ('banana', 3), ('apple', 4)])
# 将d按照key的长度来排序
>>> OrderedDict(sorted(d.items(), key=lambda t: len(t[0])))
OrderedDict([('pear', 1), ('apple', 4), ('orange', 2), ('banana', 3)])
"""
使用popitem(last=True)方法可以让我们按照LIFO(先进后出)的顺序删除dict中的key-value,
即删除最后一个插入的键值对,如果last=False就按照FIFO(先进先出)删除dict中key-value。
"""
>>> d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
# 将d按照key来排序
>>> d = OrderedDict(sorted(d.items(), key=lambda t: t[0]))
>>> d
OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1)])
# 使用popitem()方法来移除最后一个key-value对
>>> d.popitem()
('pear', 1)
# 使用popitem(last=False)来移除第一个key-value对
>>> d.popitem(last=False)
('apple', 4)
"""
使用move_to_end(key, last=True)来改变有序的OrderedDict对象的key-value顺序,
通过这个方法我们可以将排序好的OrderedDict对象中的任意一个key-value,
插入到字典的开头或者结尾。
"""
>>> d = OrderedDict.fromkeys('abcde')
>>> d
OrderedDict([('a', None), ('b', None), ('c', None), ('d', None), ('e', None)])
# 将key为b的key-value对移动到dict的最后
>>> d.move_to_end('b')
>>> d
OrderedDict([('a', None), ('c', None), ('d', None), ('e', None), ('b', None)])
>>> ''.join(d.keys())
'acdeb'
# 将key为b的key-value对移动到dict的最前面
>>> d.move_to_end('b', last=False)
>>> ''.join(d.keys())
'bacde'
-
tuple

-
set

-
None

-
slice
例子:

使代码更易读,
内置的slice函数,创建了一个切片对象,可以在任何允许切片的地方使用
items = [0, 1, 2, 3, 4, 5, 6]
a = slice(2,5)
#slice 对象有几个属性
print(a.start) # 2
print(a.step) # 不指定的话默认是None
print(a.stop) # 5
b = slice(2,5,2)
print(b.start) # 2
print(b.step) # 2
print(b.stop) # 5
# print(items[a]) # 跟items[2:5]作用是一样的
# [2, 3, 4]
# print(items[2:5])
# [2, 3, 4]
# 同时还可以替换列表中的内容
# items[a] = [0,0,0] # 直接内存中的值替换
# print(items)
# [0, 1, 0, 0, 0, 5, 6]
# 删除
# del items[a]
# print(items)
#[0, 1, 2, 3, 4, 5, 6] >> [0, 1, 5, 6]
items = [0, 1, 2, 3, 4, 5, 6]
# a = slice(2,5)
#slice 对象有几个属性
# print(a.start) # 2
# print(a.step) # 不指定的话默认是None
# print(a.stop) # 5
# b = slice(2,5,2)
# print(b.start) # 2
# print(b.step) # 2
# print(b.stop) # 5
# print(items[a]) # 跟items[2:5]作用是一样的
# [2, 3, 4]
# print(items[2:5])
# [2, 3, 4]
# 同时还可以替换列表中的内容
# items[a] = [0,0,0] # 直接内存中的值替换
# print(items)
# [0, 1, 0, 0, 0, 5, 6]
# 删除
# del items[a]
# print(items)
#[0, 1, 2, 3, 4, 5, 6] >> [0, 1, 5, 6]
a = slice(15,20,2)
s = 'HelloWorld'
b = a.indices(len(s))
# 会返回一个三元组(start, stop, step) ,如果a的范围超过s提供的长度,那么所有值都会被自动缩小以满足 边界限制,避免出现 IndexError 异常
print(b)
# (10, 10, 2)
# 对返回的三元组进行拆包,三个参数整好事range的三个参数 start, stop, step
for i in range(*a.indices(len(s))):
print(s[i])