在将古诗插入到MySQL数据库后,出现了中文乱码的问题。解决过程中,主要参考了下面几个文章。
字符集与字符编码
http://cenalulu.github.io/linux/character-encoding/(重点参考)
解决MySQL乱码问题
http://cenalulu.github.io/mysql/mysql-mojibake/(重点参考)
http://www.ha97.com/5359.html(重点参考)
一.字符集与字符编码
字符集规定某个文字对应的二进制数字存放方式(编码)和某串二进制数值代表了哪个文字(解码)的转换关系。
字符集只是一个规则的集合的名字,对应到真实的生活中,字符集就是对某种语言称呼,如英语,汉语。一个字符集有三个关键的元素:
字库表:所有可读或者可以显示的字符的数据库,决定了这个字符集能够展现的所有字符的范围。
编码字符集:用一个编码值(code point)来表示一个字符在字库表中的位置。
字符编码:编码字符集与实际存储数值之前的转换关系,一般来说都是将code point值作为编码后的值直接存储。如A 在ASCII的表中排第65位,而编码后的A就是65。
问题:字库表中每个字符都有一个自己的序号,直接将序号作为存储内容就可以了,为什么还要通过字符编码把序号转换成另外一种存储格式呢?
原因:统一字库表的目的是能够含有所有的字符,但是实际使用时只会使用一小部分,如中文地区不会使用日语,而一些英语国家甚至只用简单的ASCII字库表就可以了,如果把每个字符都用字库表中的序号来表示,则每个字符都要3个字节(unicode字库为例子),这种情况对原来只战胜一个字符的ASCII编码的国家显然是一个浪费。
二.UTF-8和Unicode的关系
Unicode
编码字符集,随着互联网的发展,对同一字库集的要求越来越迫切,因此出现了Unicode标准,它几乎涵盖了各个国家的语言可能出现的符号与文字,并将它们进行编号。
UTF-8
字符编码,是Unicode规则字库的一种实现形式。虽然它现在是接受度最好的一个字符集编码,但是并没有涵盖整个Unicode的字库。
三.UTF-8编码实现
下面介绍下UTF-8的编码实现,也就是它的物理存储和Unicode序号的转换关系。
UTF-8编码为变长编码,最小编码单位(code unit)为一个字节,一个字节的前1-3个bit为描述性部分,后面为实际序号部分。
- 如果一个字节的第一位为0,那么代表当前字符为单字节字符,占用一个字节的空间。0之后的所有部分(7个bit)代表在Unicode中的序号。
- 如果一个字节以110开头,那么代表当前字符为双字节字符,占用2个字节的空间。110之后的所有部分(5个bit)加上后一个字节的除10外的部分(6个bit)代表在Unicode中的序号。且第二个字节以10开头
- 如果一个字节以1110开头,那么代表当前字符为三字节字符,占用2个字节的空间。110之后的所有部分(5个bit)加上后两个字节的除10外的部分(12个bit)代表在Unicode中的序号。且第二、第三个字节以10开头
- 如果一个字节以10开头,那么代表当前字节为多字节字符的第二个字节。10之后的所有部分(6个bit)和之前的部分一同组成在Unicode中的序号。
可以看到,UTF-8字符编码是以一定方式实现了Unicode规则的字库。
四.乱码的出现
出现的原因:在编码与解码时使用了不同或者不兼容的字符集。
就如同英语的bless与法语的bless,意思不同一样,同一个汉字在UTF-8中的编码与在GBK中的编码不同,就会出现筹码。
五.MySQL出现乱码的原因
主要分析:从客户端发起请求,到MySQL存储数据,再到下一次从表中取出数据到客户端,中间那些环节出现了编码/解码。
(1)存入MySQL的过程
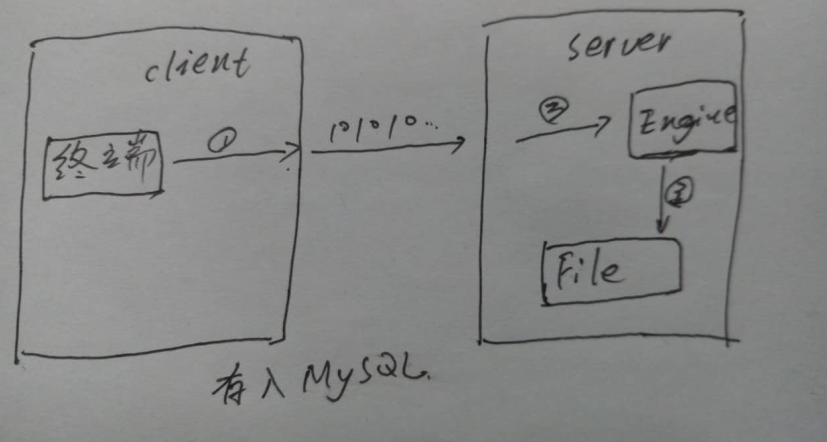
1.客户端(也就是用户端)编码成二进制流。
2. MySQL Server解码。
3.Client编码向表编码转换。
详细的过程为:
- 在terminal中使用输入法输入
- terminal中气字符编码转换成二进制流
- 二进制流通过MySQL客户端传输到MySQL Server
- Server通过character-set-client解码
- 判断character-set-client和目标表的charset是否一致
- 如果不一致则进行一次从client-charset到table-charset的字符编码转换
- 将转换后的字符编码二进制流保存到文件中
(2)从MySQL表中取出数据的过程
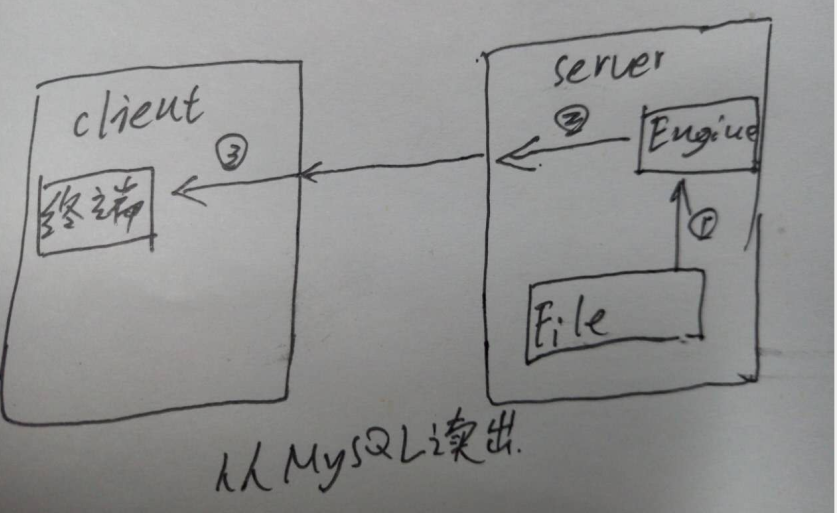
1.table-charset向character-set-client编码的转换。
2.MySQL Server根据character-set-client编码得到二进制流。
3.client解码展示。
详细过程为:
从文件读出二进制数据流
用表字符集编码进行解码
将数据转换成character-set-client的编码
使用character-set-client编码为二进制流
Server通过网络等传输到远端的client
client通过bash配置的字符编码展示结果
(3)造成MySQL乱码的原因
1.存入和取出时对应环节的编码不一致
如在存入时,我们客户端使用的UTF-8编码,而读出时,客户端却使用的windows的GBK编码。则会出现乱码。
2.单个流程中三步的编码不一致
上面的任意一幅图中的同方向的三步中,只有两步或者两步以上的编码有不一致,就有可能出现编码解码错误。如果不同的两个字符集之前无法进行无损编码转换,则一定会
出现乱码。如:bash 是UTF8编码,MySQL的character-set-client配置成了GBK,而表结构的编码又是charaset=utf8,则肯定会出现乱码。
(4)关于MySQL编码解码的问题
从上面的图中可以看到,系统之前是用二进制流进行传输的,那为什么不直接将这串二进制流存入表文件,而还要在存储前进行两次编解码呢?
1.Client to Server的编码解码原因是MySQL要对传来的二进制流做语法和词法解析,如果不做编码解码和校验,我们甚至不知道传输来的二进制流是insert 还是update。
2.File to Engine的编码解码是为知道二进制流内的分词情况,例如从表里面取出某个字段的前两个字符的命令:select left(col,2) from table ,存储引擎从文件诗篇这个column的值,再按照相应的编码进行分割,不同的编码分割的结果是不一样的(有的一个字符为两字节,有的为三字符等)。因此,在从数据文件读取数据后,如果不进行编码解码的话,在存储引擎同是无法进行字符级别的操作的。
(5)如何避免乱码
从上面的分析可以看出,只要做到:客户端,MySQL character-set-client,table-charset三个字符集完全一致就可以保证不出现乱码了。
六 .Linux下修改字符集编码为UTF8,解决中文乱码问题
(1)查看当前数据库的相关编码集

可以看到,character_set_database和character_set_server的默认字符集还是latin1。
注意:
latin1是8bit 大小的字符集,latin1, ASCII,UTF8字符集的区别参考
http://blog.sina.com.cn/s/blog_5edf2a9f0100sicm.html
(2)修改mysql配置文件
首先我们通过命令whereis找到mysql配置文件的位置。

在/etc/mysql/中找到配置文件my.cnf里说明有
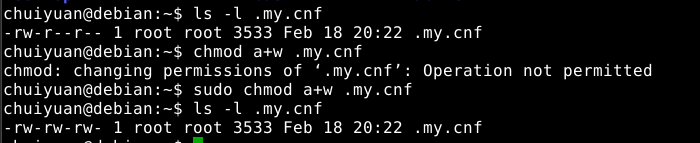
因此我们将其复制到用户目录下,并修改其权限
修改配置中的字符集
在[client]里加入
default-character-set=utf8
在[mydqld]里加入
character-set-server=utf8
在[mysql]里加入
default-character-set=utf8
修改后,重启 mysql服务
sudo /etc/init.d/mysql restart
但是在我们再次使用mysql时,出现了下图中的问题

原因是之前的步骤中我们修改了.my.cnf文件的权限,mysql担心这种文件被其它用户恶意修改,所以选择了忽略,改正这个问题

再次启动,发现修改~/.my.cnf的并没有生效,先忽略这个问题,直接在/etc/mysql/my.cnf中修改,重启,查看字符集

这次正确了。
注意:暂没有发现为什么~/.my.cnf文件修改后没有起到作用。