一、回顾
1、Pod是标准的kubernetes资源,因此其遵循为其资源清单配置定义的基本格式,包含:apiVersion,kind,metadata,spec,status(只读)
2、spec的内嵌字段
containers:
name
image
imagePullPolicy:Always,Never,IfNotPresent
ports:name,containerPort
livenessProbe
readinessProbe
liftcycle
ExecAction: exec
TCPSocketAction:tcpSocket
HTTPGetAction:httpGet
nodeSelector
nodeName
restartPolicy(重启策略):Always,Never,OnFailure
二、pod控制器:前面介绍的创建pod的方式创建的为自主式pod,而不是控制器控制管理的pod,当我们删除后其不会再启动。
1、pod控制器用于实现代我们去管理pod的中间层,并帮我们确保每一个pod资源始终保持我们所定义或者所期望的目标状态,万一这个pod资源出现故障那么首先会尝试重启容器,如果一直重启有问题那其可能会基于某种策略进行重新编排。如果pod的副本数量低于用户所定义的目标数量那么他也会自动补全,若多余那么也会自动终止多余的资源。
2、ReplicaSet:pod控制器有多种类型,第一种为ReplicaSet:其核心作用在于,待用户创建指定数量的pod副本,并确保pod副本一直处于满足用户数量的状态,并且支持副本多退少补,并且支持自动扩缩容机制。ReplicaSet被称为是新一代的ReplicationController,在最早时候,k8s只有一种控制器叫ReplicationController,但是后来发现ReplicationController设计目标过于庞大,要一个来完成所有的功能不怎么现实,因此目前其基本已经废弃了,所以推荐使用ReplicaSet(其相当于是新一代的ReplicationController)。他主要是帮助用户管理无状态的pod资源,并确保其能够精确反应用户所定义的目标数量,其由三个组件组成:
a、用户定义的由其管控的pod副本有几个
b、标签选择器,怎么判定哪些pod是由自己管理的
c、pod资源模板:集群的现存的pod副本不够我们定义的期望数量时怎么办,一般是基于pod模板新建
3、Deployment :k8s不建议我们直接使用ReplicaSet而是使用deployment,其也是一个控制器,比较诡异的是其工作在ReplicaSet之上,因此,deployment是直接通过控制ReplicaSet来控制pod,因此其能够提供比ReplicaSet更为强大的功能,比如ReplicaSet支持的扩缩容其也是支持的,而Deployment还支持滚动更新回滚等众多更为强大的功能,并且其还提供了声明式配置的功能,这种声明式配置使得我们将来创建资源时可以基于声明的逻辑来定义。我们那些所有更新的资源可以随时重新进行声明,随时改变我们在api server上定义的目标期望状态,只要资源支持动态运行时修改。因此其是帮我们管理无状态应用的目前来讲最好的控制器。
4、DaemonSet:用于确保集群每一个节点只运行一个特定的pod副本,因此他们通常是用来实现系统级别的后台任务,将其托管到k8s上的好处是可以用守护进程的方式运行它,并且当有新节点加入集群时他会自动在上面启动一个此类的pod副本。因此DaemonSet来讲你就不能定义所期望的数量,因为其数量不是取决于我们定义而是取决于集群规模。但是pod模板肯定是要存在的,因为只有有了pod模板才能在节点上建立起pod资源来。另外标签选择器也是需要的,毕竟每个节点上有没有符合我们所指定条件的pod资源是要考标签选择器来判定的。也可以设置只部分节点运行一个指定的pod副本。
5、无论是Deployment还是DaemonSet,他们都有以下特点:
a、这种服务是无状态的。
b、这种服务是守护进程类的,必须持续运行在后台,没有终止的这一刻。
6、Job控制器:我们k8s集群可以按照用户指定的数量启动指定数量的pod资源。这个pod资源启动起来后就可以执行其应该完成的任务。假如任务还没有完成的情况下出现异常问题导致pod被删除,但是其任务还没有完成的情况下其会重建pod,但是当其任务执行完成后正常退出的情况下就不会再进行重建。因此其要不要重建的前提是其任务是否完成。但是其只能执行一次性的作业。
7、Cronjob:周期性运行任务的控制器,和job一样
8、StatefulSet控制器:管理我们的有状态应用。像Deployment管理的是相同规格的无状态的群体,如nginx集群,而此控制器管理的为有状态的个体副本,比如redis 集群中的节点,其定义的每一个pod副本都是被单独管理的,他拥有自己独有的标识和独有的数据集,一旦这个节点出现故障,那么加进来可能要做很多操作,比如管理的redis集群中的单个节点宕机后需要将集群中故障节点的从节点设置为主节点。此时需要很多的运维任务或操作过程来实现,此时就需要进行定义。这个使用比较困难,需要很高的运维技能。
9、k8s还支持另一种资源TPR(Third Party Resources,第三方资源):从1.2+版本开始支持,到1.7又被废了,因为其有了更新的功能,叫CDR(Custom Defined Resources,用户自定义资源):从1.8+开始支持。用户可以自定义资源,可以将我们的运维操作技能封装进去,定义成一种特殊类型的资源,或者是把我们要管理的目标资源的管理方式定义成一种独特的管理逻辑来实现。而后,我们还可以借助于COR研发的一种Operator的东西来实现封装我们的运维技能(其比我们直接使用StatefulSet要强大的多),到今天为止,成熟的Operator支持的也不过是etcd 普罗米修斯(Prometheus)等几个,还有很多还在实验性使用阶段。因此要把有状态应用托管在k8s上还是很考验能力的。
10、任何一个工具或系统不把用户当傻瓜而让用户做二次开发那么注定用户就不会太多,也不可能有太多的市场占有率,为了解决这样的问题,k8s后来提供了一种功能叫Helm(头盔,外壳)。其类似于我们linux的yum,比如要在k8s上部署一个redis集群,那么我们直接使用Helm命令来安装即可。
三、控制器详解
1、ReplicaSet (可通过 kubectl explain ReplicaSet(或简写rs)来查看其字段)
[root@k8smaster manifests]# cat rs-demo.yaml apiVersion: apps/v1 kind: ReplicaSet metadata: name: myapp namespace: default spec: replicas: 2 selector: matchLabels: #匹配下面标签键值对,并且下面的标签键值对是逻辑与关系,意思是只有app标签值为myapp并且release标签值为canary才能匹配。 app: myapp #所有应用程序拥有app标签并且其值为myapp release: canary #所有应用程序拥有release标签并且值为canary template: #定义pod模板 metadata: #由此模板创建出来的pod的元数据,其会和控制器处于同一个namespace中 name: myapp-pod #这个name其实没什么用,因为启动的pod的名字是以控制器的名字加后面随机字符串进行命名的 labels: #这个标签必须要创建,并且要符合上面的selector标签选择器来写,不然发现创建pod所用的标签都不符合此标签选择器就白创建了,因此模板定义的创建的pod的标签一定要符合其所定义的selector,当然也可以有更多的标签,但是必须要包含selector中所定义的标签内容。
app: myapp release: canary environment: qa spec: containers: - name: myapp-container image: ikubernetes/myapp:v1 ports: - name: http containerPort: 80 [root@k8smaster manifests]# kubectl get pods -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE LABELS liveness-httpget-pod 1/1 Running 1 1d 10.244.2.18 k8snode2 <none> myapp-2qwtd 1/1 Running 0 47s 10.244.2.22 k8snode2 app=myapp,environment=qa,release=canary myapp-nqj5p 1/1 Running 0 47s 10.244.1.26 k8snode1 app=myapp,environment=qa,release=canary pod-demo 2/2 Running 11 2d 10.244.1.24 k8snode1 app=myapp,tier=frontend poststart-pod 1/1 Running 6 1d 10.244.2.21 k8snode2 <none> readiness-httpget-pod 1/1 Running 0 1d 10.244.2.19 k8snode2 <none> [root@k8smaster manifests]# curl 10.244.2.22 Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a> #删除pod后会自动重建 [root@k8smaster manifests]# kubectl delete pod myapp-2qwtd pod "myapp-2qwtd" deleted [root@k8smaster manifests]# kubectl get pods -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE LABELS liveness-httpget-pod 1/1 Running 1 1d 10.244.2.18 k8snode2 <none> myapp-nqj5p 1/1 Running 0 10m 10.244.1.26 k8snode1 app=myapp,environment=qa,release=canary myapp-xtd67 1/1 Running 0 7s 10.244.2.23 k8snode2 app=myapp,environment=qa,release=canary pod-demo 2/2 Running 11 2d 10.244.1.24 k8snode1 app=myapp,tier=frontend poststart-pod 1/1 Running 6 1d 10.244.2.21 k8snode2 <none> readiness-httpget-pod 1/1 Running 0 1d 10.244.2.19 k8snode2 <none>
若集群中定义的副本数为2,但是某pod的标签刚好又匹配到该控制器导致副本数变为3,那么该控制器会随机删除一个pod
当我们修改了控制器中的模板中的镜像版本后只有重建pod资源才会基于新镜像创建,否则还是开始镜像启动的Pod资源。可以利用此功能进行灰度发布(金丝雀发布),一点一点pod的删除,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。当然也可以用蓝绿的方式进行:再创建一个rs,新的rs与老的rs的标签不完全一样,但和前端的service都能兼容,然后我们先创建rs2,再删rs1,这种就叫蓝绿发布。或者让service只符合rs1的,然后创建一个不符合service的rs2,等rs2的功能没问题了再改一下service选择器,改为能匹配到rs2不能匹配到rs1,这种才是标准的蓝绿发布。
[root@k8smaster manifests]# kubectl get pods -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE LABELS liveness-httpget-pod 1/1 Running 1 1d 10.244.2.18 k8snode2 <none> myapp-wwh84 1/1 Running 0 19m 10.244.1.27 k8snode1 app=myapp,environment=qa,release=canary myapp-xtd67 1/1 Running 0 35m 10.244.2.23 k8snode2 app=myapp,environment=qa,release=canary poststart-pod 1/1 Running 6 1d 10.244.2.21 k8snode2 <none> readiness-httpget-pod 1/1 Running 0 1d 10.244.2.19 k8snode2 <none> [root@k8smaster manifests]# kubectl get rs NAME DESIRED CURRENT READY AGE myapp 2 2 2 49m [root@k8smaster manifests]# kubectl edit rs myapp replicaset.extensions/myapp edited [root@k8smaster manifests]# kubectl get rs -o wide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR myapp 2 2 2 50m myapp-container ikubernetes/myapp:v2 app=myapp,release=canary [root@k8smaster manifests]# curl 10.244.1.27 Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
2、将来我们使用控制器创建一组不分彼此的pod资源,并且我们这一组pod要想被客户端不受pod生命周期影响所访问。因此为了让用户有个固定的访问端点我们需要在外面加上一个service组件,并且这个service所使用的标签选择器和该控制器是相同的,以便去选择这些pod资源。关联到这些pod资源才能把来自于客户端的请求端口代理至后端pod资源,但是service和控制器并没有一一对应关系,若有两个控制器,一个标签为app=myapp,release=cnary,另一个控制器标签为app=myapp,release=贝塔,而service只有一个标签选择器为app=myapp那么那两个控制器下的pod都能被其选中。因此service和控制器并没有对应关系,只不过service可以使用控制器创建的pod资源作为后端而已。
3、deployment :建立在rs之上,一个deployment直接管理多个rs(目前默认为10个),但是存活的当前正在使用的只有一个,因此当需要更新到新版本的时候其创建一个新的rs,把老的rs给替换掉,不是覆盖掉,而是把老的rs中的资源逐一的替换掉。并且一旦发现v2有问题还能回滚到v1,通常只保留历史版本中的10个。并且deployment能提供声明式中心配置,声明式创建我们一般是用apply而不是create,对于apply管理的我们将来还可以使用patch打补丁来实现修改,而不用edit,我们完全可以在命令行中通过纯命令的方式直接完成对应资源版本内容的修改。说白了我们可以直接通过post方式提交内容进行修改而不是直接改配置文件。因此:
a、deployment能提供滚动式自定义自控制的更新
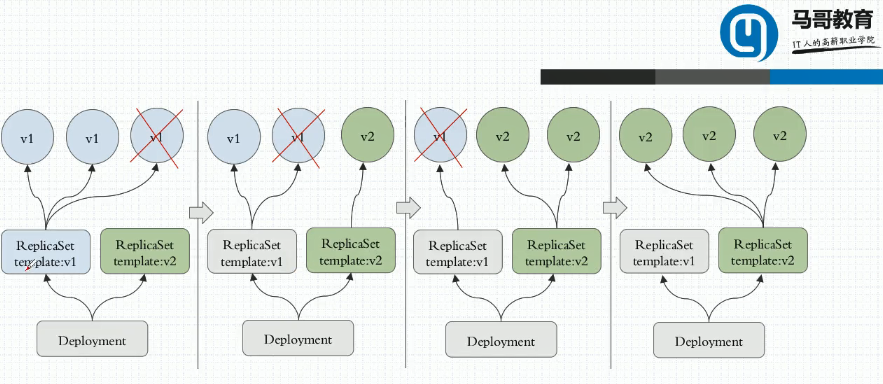
b、对于deployment来讲,我们在实现所谓的更新时,还能实现控制更新节奏和更新逻辑。比如我们replicset控制有5个pod资源副本,刚才我们手动更新的方式是删一个让它自动创建一个,然后再删一个再自动创建一个,若5个pod刚好能提供用户流量需求,若删除其中一个有可能会导致访问超时等问题。因此我们需要加一个删一个,此时我们需要临时加一个,因此临时需要加几个,怎么加,也是可以完全支持和控制的,我们可以指定在滚动更新期间最多能多出我们期望副本数的几个(多出几个就先加几个然后再删几个),还能定义能少于副本期望数的几个(少几个就先删几个再加几个)。
c、deployment结构如下