环境:CentOS6.6 64位 + FlumeNG 1.6
请参考推荐文档:
Flume-ng的原理和使用 - JunezChen Blog - SegmentFault https://segmentfault.com/a/1190000002532284
已经很全面了,没必要自己写一份文档,更多内容可以参考Flume安装包里doc目录下的自带文档
一、安装
注意:需要预先安装JDK,因为flume是基于Java的;
Flume是没有高可用HA的,但是可以使用拦截器、渠道选择器等高级组件实现负载均衡等功能;
Flume经常和Kafka配合使用。
1、下载并解压FlumeNG


[root@root ~]# wget http://124.205.69.169/files/A1540000011ED5DB/mirror.bit.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz [root@root ~]# tar -zxvf apache-flume-1.6.0-bin.tar.gz -C /opt/ [root@root ~]# cd /opt/ [root@root opt]# mv apache-flume-1.6.0-bin apache-flume
2、修改环境变量、启动
[root@root opt]# cd apache-flume/ [root@root apache-flume]# cp conf/flume-env.sh.template conf/flume-env.sh [root@crxy99 apache-flume]# vim conf/flume-env.sh #修改JAVA_HOME 23行: export JAVA_HOME=/opt/jdk1.7.0_45 [root@crxy99 apache-flume]# vim conf/example.conf #创建agent模板配置文件 [root@crxy99 apache-flume]# bin/flume-ng agent --conf conf/ --conf-file conf/example.conf --name a1 -Dflume.monitoring.type=http -Dflume.monitoring.port=34343 -Dflume.root.logger=INFO,console & #启动脚本
补充:
1)、模板example.conf:
#配置一个agent 名字为a1 #声明这个agent的三个组件 sources 有一个r1,sinks 包含一个 k1,channels包含一个c1 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置r1 使用netcat的source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # 配置k1 使用loggersink a1.sinks.k1.type = logger # 配置c1 使用内存的channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #连线,将三个组件关联起来 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2)、启动脚本的含义:
agent 使用agent数据处理方式
-Dflume.root.logger=INFO,console -D后面的为参数,这里使用打印到控制台的方式,并动态修改log4j的为info级别
3)、关闭服务:
[root@root apache-flume]# jps 2776 Jps 2496 Application [root@root apache-flume]# kill -9 2496 #flume目前没有关闭服务的脚本,只能kill
4)、补充:Telnet
在测试、学习阶段可以使用telnet工具进行模拟,linux下安装方式(Windows下自带了Telnet服务,启用即可,可以百度相关文档)
# yum -y install telnet
二、实例
实例1:一个需求:实时监听一个文件(如/test/logs/access.log)的数据增加
分析:1、由于agent方式能提供持续传输数据的服务,因此采用agent数据处理方式;
2、agent组件:source --> channel --> sink
3、动态监控文件的数据的增加情况可以使用命令tail -F 命令(注意不是tail -f,后者不会retry),因此可以使用exec sink
4、假设内存情况是充裕的,不予考虑,采用memory channel
5、假设数据发送到本地:file roll sink
如下图所示(开发过程中画图可以很好的理解项目数据采集流程,推荐使用):
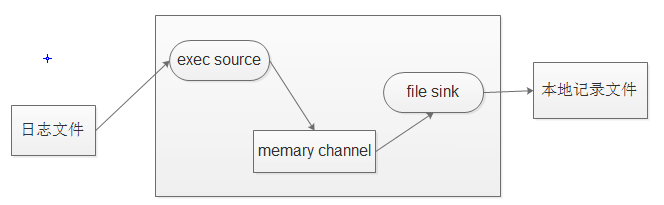
因此:编写agent配置文件:
#配置一个agent 名字为a1 #1、声明这个agent的三个组件 sources 有一个r1,sinks 包含一个 k1,channels包含一个c1 a1.sources = r1 a1.sinks = k1 a1.channels = c1 #2、配置r1 使用exec的source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /test/logs/access.log # 配置c1 使用file的channel a1.channels.c1.type = file a1.channels.c1.checkpointDir = /test/flume_checkpoint #检查点数据存放目录 a1.channels.c1.dataDirs = /test/flume_datadir #数据存储目录 a1.channels.c1.transactionCapacity = 100 # 配置k1 使用file rolling sink a1.sinks.k1.type = file_roll a1.sinks.k1.sink.directory = /test/flumefile #文件存放目录 a1.sinks.k1.sink.rollInterval = 86400 #每天产生一个新文件(单位:s) #3、连线,将三个组件关联起来 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动flume:
$ nohup bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/execsource_filerollsink.conf &
注:flume进程启动动没有关闭的命令,只能kill掉。:
实战2:若上面的文件在某一时刻出现高并发的情况,flume很容易挂掉,如何处理?
说明:在高并发情况下,若不更改默认配置,flume容易出现内存溢出的错误。这是因为它默认的堆初始内存只有20M,可以编辑环境变量
# vim conf/flume-env.sh,去掉下面一行注释的设置,并根据需要调整初始内存和最大分配内存。
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
注:20M源于/bin/flume-ng里的默认设置:JAVA_OPTS="-Xmx20m"
参考:Flume 1.6.0 User Guide — Apache Flume http://flume.apache.org/FlumeUserGuide.html
注:解压后的flume目录下有docs目录,下面的说明文档与该官网的一致,非常人性化!