RAID 几种常见的类型

安装的megacli,之前先查看系统硬盘个数和RAID级别
[root@localhost Linux]# cat /proc/scsi/scsi
Attached devices:
Host: scsi2 Channel: 00 Id: 00 Lun: 00
Vendor: VMware, Model: VMware Virtual S Rev: 1.0
Type: Direct-Access ANSI SCSI revision: 02
Host: scsi1 Channel: 00 Id: 00 Lun: 00
Vendor: NECVMWar Model: VMware IDE CDR10 Rev: 1.00
Type: CD-ROM ANSI SCSI revision: 05
[root@localhost Linux]# dmesg |grep -i raid

由于是虚拟机没有做raid ,不显示raid级别
二进制安装
http://pan.baidu.com/s/1mgBO3aS
1、解压
/opt/# tar -zxvf MegaCli8.07.10.tar.gz
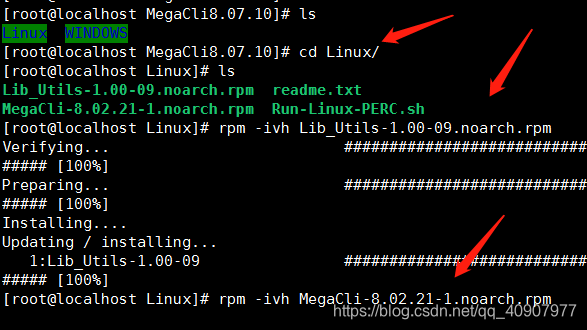
#cd MegaCli8.07.10/Linux
Linux]# ls
Lib_Utils-1.00-09.noarch.rpm readme.txt
MegaCli-8.02.21-1.noarch.rpm Run-Linux-PERC.sh
#rpm -ivh Lib_Utils-1.00-09.noarch.rpm
#rpm -ivh MegaCli-8.02.21-1.noarch.rpm
[root@localhost opt]# ls #回到opt目录下,查看是否生成MegaRAID目录,
lsi MegaCLI MegaCli8 MegaRAID

2、执行MegaCli命令
/opt/MegaRAID/MegaCli#ls
install.log libstorelibir-2.so.14.07-0
libstorelibir-2.so MegaCli64
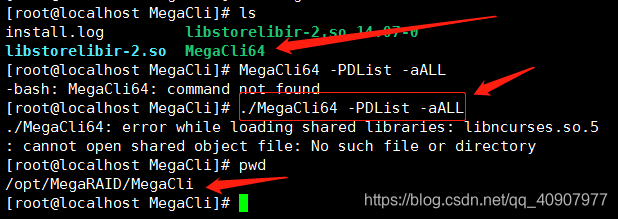
3、处理报错信息./MegaCli64: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory
[root@localhost MegaCli]# ./MegaCli64 -PDList -aALL
./MegaCli64: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory
解决办法 :
安装libncurses.so.5之后,还是报错。
#yum install libncurses.so.5
# megacli -PDList -aALL
megacli: error while loading shared libraries: libncurses.so.5: cannot open shared object file: No such file or directory
#yum install ncurses-libs.i686 libstdc++.i686 libgcc.i686
安装libncurses相关软件包
#yum install libncurses*
# megacli -PDList -aALL
Exit Code: 0x00

虚拟机中RAID1
虚拟机添加两块硬盘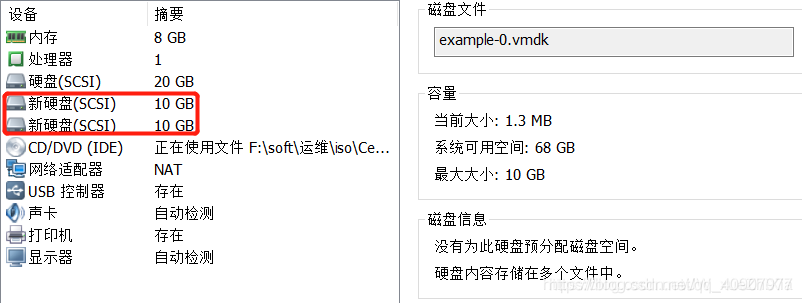
安装raid管理工具mdadm
yum install -y mdadm
- 1
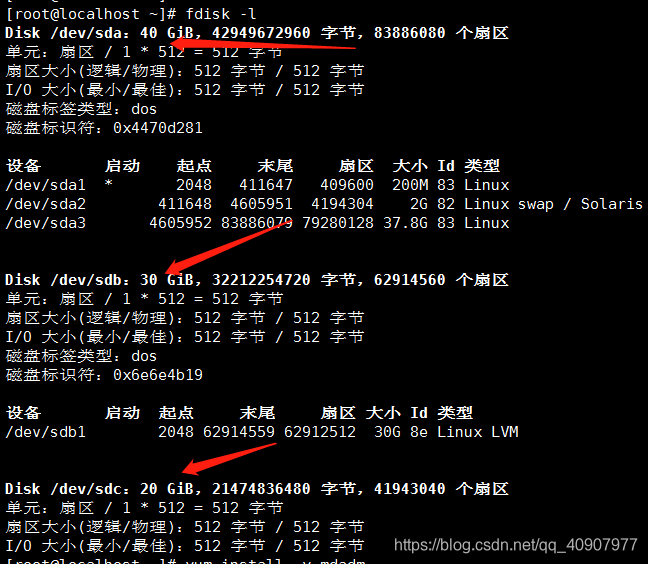
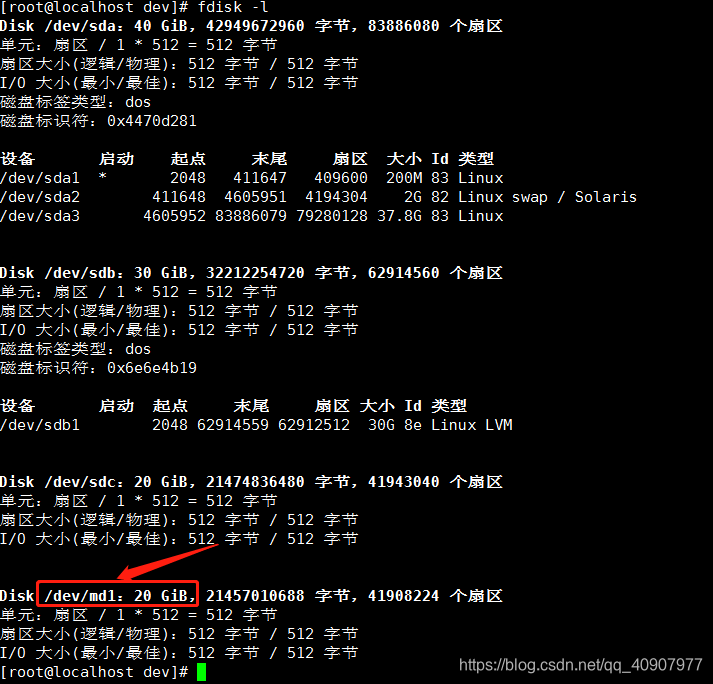
查看磁盘情况
fdisk -l
创建raid1
mdadm -C /dev/md1 -n 2 -l 1 -a yes /dev/sd{b,c}
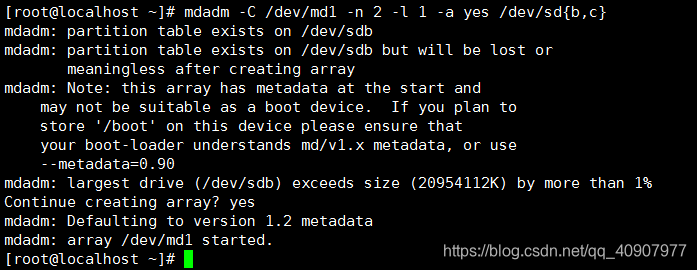
查看raid信息
cat /proc/mdstat

格式化
mkfs.ext4 -j -b 4096 /dev/md1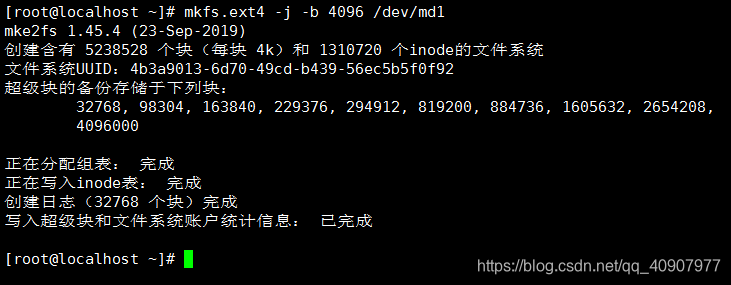
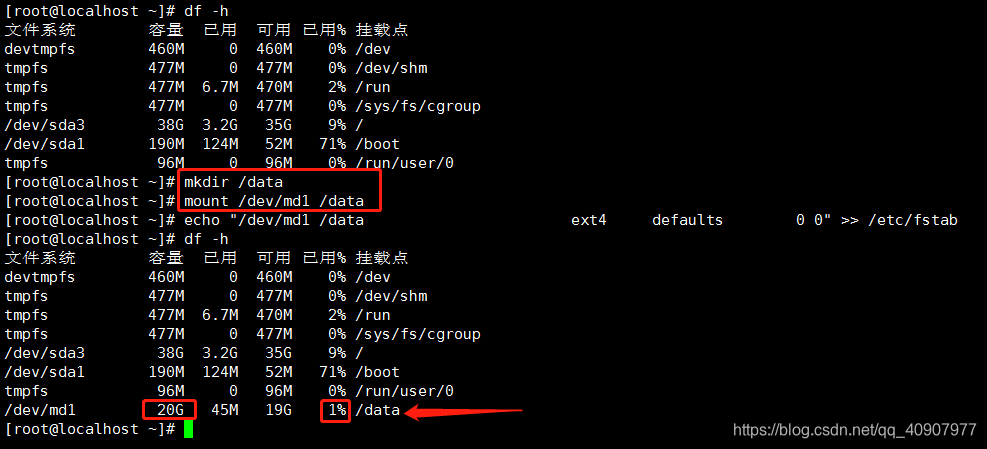
挂载 (硬盘挂载到data目录成功)
mkdir /data
mount /dev/md1 /data
echo "/dev/md1 /data ext4 defaults 0 0" >> /etc/fstab
写数据
mkdir /data/abc && touch /data/abc/123
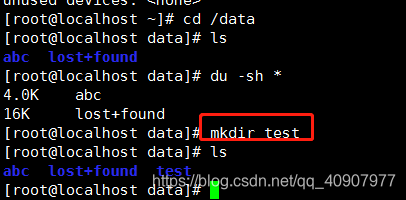
模拟损坏其中一个磁盘块
mdadm /dev/md1 -f /dev/sdc

查看raid信息
mdadm -D /dev/md1
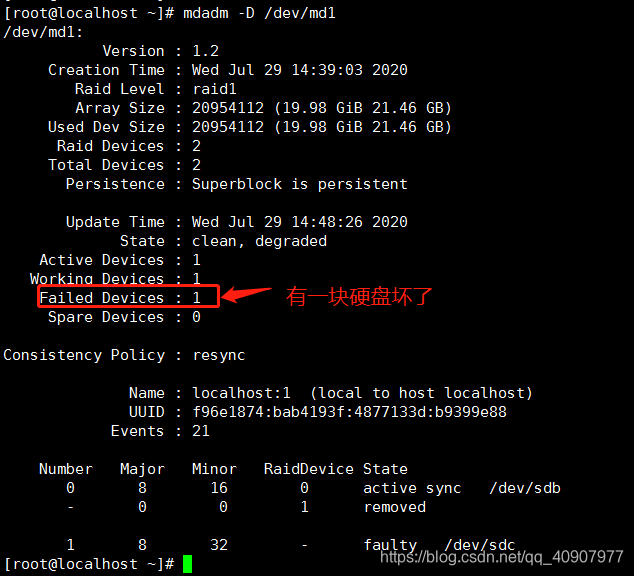
新增磁盘设备,添加到md1
#mdadm /dev/md1 -a /dev/sdb
mdadm: Cannot open /dev/sdb: Device or resource busy

软Raid创建的时候出现mdadm: Cannot open /dev/sde1: Device or resource busy
用一下命令可以解决:mdadm --stop /dev/md1
[root@localhost dev]# mdadm --stop /dev/md1
mdadm: Cannot get exclusive access to /dev/md1:Perhaps a running process, mounted filesystem or active volume group?
意思就是停止Raid,停止先前创建的,
停止Raid后不提示就用上面的命令 md_d1是生成Raid重启后有的

查看硬盘类型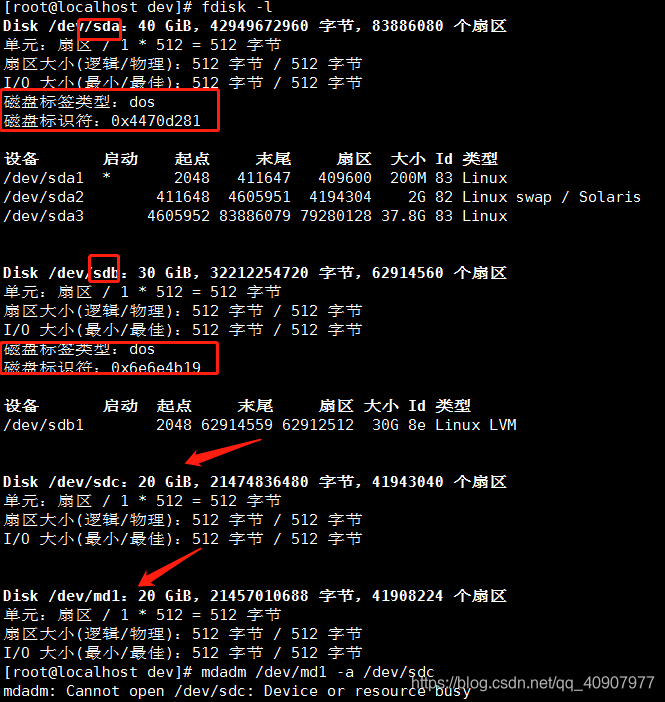
三个硬盘,一个模拟坏盘,一个是系统盘正在运行,一个是刚刚挂载的data
报错:系统正在使用中。
解决办法 :添加完硬盘后,需要重启才能识别这些硬盘设备。
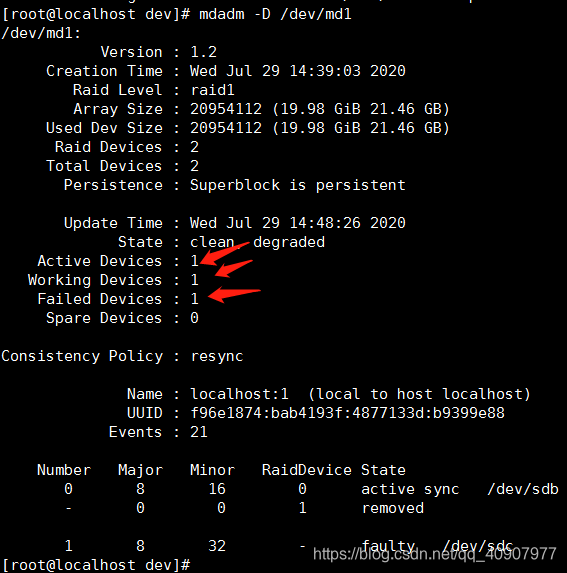
查看raid信息
mdadm -D /dev/md1
删除已损坏的硬盘
#mdadm /dev/md1 -r /dev/sdc
mdadm: hot remove failed for /dev/sdc: Device or resource busy
#/dev/sdc正在使用中
#mdadm -D /dev/md1 #查看损坏的硬盘,是否被删除。


停止md1磁盘
mdadm --stop /dev/md1
mdadm: Cannot get exclusive access to /dev/md1:Perhaps a running process, mounted filesystem or active volume group?


查看状态,一切正常:
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md1 : active raid5 sdf[4] sdg[3] sdi[2] sdj[1] sdh[0]
3907045376 blocks super 1.2 level 5, 256k chunk, algorithm 2 [5/5] [UUUUU]
unused devices: <none>
查看挂载点,也未发现有mount;也没有使用LVM管理该设备。
查看是否有用户正在使用该设备:
#fuser -vm /dev/md1
- 1
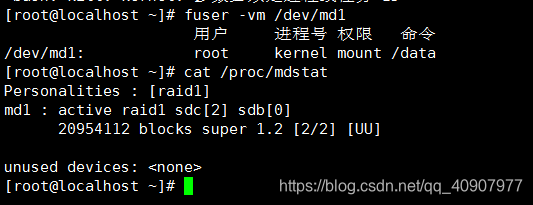
显示root用户正在操作该设备,kill掉该进程,再次stop该设备成功。
megacli用法
执行状态检测命令:
/opt/MegaRAID/MegaCli/MegaCli64 -pdlist -aall |grep 'Firmware state'
Firmware state: Unconfigured(good), Spun Up
Firmware state: Online, Spun Up
Firmware state: Online, Spun Up
执行导入命
/opt/MegaRAID/MegaCli/MegaCli64 -CfgForeign -Import -aall
Foreign configuration is imported on controller 0.
Exit Code: 0x00
再次执行状态检测命令:
/opt/MegaRAID/MegaCli/MegaCli64 -pdlist -aall |grep 'Firmware state'
Firmware state: Rebuild
Firmware state: Online, Spun Up
Firmware state: Online, Spun Up
查询 Rebuild 进度:
/opt/MegaRAID/MegaCli/MegaCli64 -pdrbld -showprog -physdrv[32:0] -a0
显示如下:
Rebuild Progress on Device at Enclosure 32, Slot 0 Completed 38% in 54 Minutes.
Exit Code: 0x00
或者
/opt/MegaRAID/MegaCli/MegaCli64 -pdrbld -ProgDsply -physdrv[32:0] -a0显示如下:
Rebuild progress of physical drives...
Enclosure:Slot Percent Complete Time Elps
032 :00 ####################***40 %*********************** 00:56:40
Press <ESC> key to quit...
备注:
Enclosure Device ID: 32
Slot Number: 0
以上两条信息通过/opt/MegaRAID/MegaCli/MegaCli64 -pdlist -aall |less 来查看
扫描外来配置的个数:
# /opt/MegaRAID/MegaCli/MegaCli64 -cfgforeign -scan -a0
- 1
清除外来配置:
# /opt/MegaRAID/MegaCli/MegaCli64 -cfgforeign -clear -a0
再次扫描外来配置的个数:
# /opt/MegaRAID/MegaCli/MegaCli64 -cfgforeign -scan -a0
1.显示Rebuid进度
/opt/MegaRAID/MegaCli/MegaCli64 -PDRbld -ShowProg -physdrv[20:2] -aALL
2.查看E S
/opt/MegaRAID/MegaCli/MegaCli64 -PDList -aAll -NoLog | grep -Ei "(enclosure|slot)"
3.查看所有硬盘的状态
/opt/MegaRAID/MegaCli/MegaCli64 -PDList -aAll -NoLog
4.查看所有Virtual Disk的状态
/opt/MegaRAID/MegaCli/MegaCli64 -LdPdInfo -aAll -NoLog
5.在线做Raid
/opt/MegaRAID/MegaCli/MegaCli64 -CfgLdAdd -r0[0:11] WB NORA Direct CachedBadBBU -strpsz64 -a0 -NoLog
/opt/MegaRAID/MegaCli/MegaCli64 -CfgLdAdd -r5 [12:2,12:3,12:4,12:5,12:6,12:7] WB Direct -a0
6.点亮指定硬盘(定位)
/opt/MegaRAID/MegaCli/MegaCli64 -PdLocate -start -physdrv[252:2] -a0
7.清除Foreign状态
/opt/MegaRAID/MegaCli/MegaCli64 -CfgForeign -Clear -a0
8.查看RAID阵列中掉线的盘
/opt/MegaRAID/MegaCli/MegaCli64 -pdgetmissing -a0
9.替换坏掉的模块
/opt/MegaRAID/MegaCli/MegaCli64 -pdreplacemissing -physdrv[12:10] -Array5 -row0 -a0
10.手动开启rebuid
/opt/MegaRAID/MegaCli/MegaCli64 -pdrbld -start -physdrv[12:10] -a0
11.查看Megacli的log
/opt/MegaRAID/MegaCli/MegaCli64 -FwTermLog dsply -a0 > adp2.log
12.设置HotSpare
/opt/MegaRAID/MegaCli/MegaCli64-pdhsp -set[-Dedicated[-Array2]][-EnclAffinity][-nonRevertible]-PhysDrv[4:11]-a0
/opt/MegaRAID/MegaCli/MegaCli64-pdhsp -set[-EnclAffinity][-nonRevertible]-PhysDrv[32:1}]-a0
MegaCli -PDHSP -Set -Dedicated -Array0 -physdrv[E:S] -a0 添加局部热备盘,其中array0表示第0个raid
- 常用命令:
#/opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -Lall -aALL 查raid级别
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpAllInfo -aALL 查raid卡信息
#/opt/MegaRAID/MegaCli/MegaCli64 -PDList -aALL 查看硬盘信息
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpBbuCmd -aAll 查看电池信息
#/opt/MegaRAID/MegaCli/MegaCli64 -FwTermLog -Dsply -aALL 查看raid卡日志
#/opt/MegaRAID/MegaCli/MegaCli64 -adpCount 【显示适配器个数】
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpGetTime �CaALL 【显示适配器时间】
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpAllInfo -aAll 【显示所有适配器信息】
#/opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -LALL -aAll 【显示所有逻辑磁盘组信息】
#/opt/MegaRAID/MegaCli/MegaCli64 -PDList -aAll 【显示所有的物理信息】
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpBbuCmd -GetBbuStatus -aALL |grep ‘Charger Status’ 【查看充电状态】
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpBbuCmd -GetBbuStatus -aALL【显示BBU状态信息】
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpBbuCmd -GetBbuCapacityInfo -aALL【显示BBU容量信息】
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpBbuCmd -GetBbuDesignInfo -aALL 【显示BBU设计参数】
#/opt/MegaRAID/MegaCli/MegaCli64 -AdpBbuCmd -GetBbuProperties -aALL 【显示当前BBU属性】
#/opt/MegaRAID/MegaCli/MegaCli64 -cfgdsply -aALL 【显示Raid卡型号,Raid设置,Disk相关信息】
#/opt/MegaRAID/MegaCli/MegaCli64 -adpallinfo -aall|grep -i temp 查看温度
- 磁带状态的变化,从拔盘,到插盘的过程中
Device |Normal|Damage|Rebuild|Normal
Virtual Drive |Optimal|Degraded|Degraded|Optimal
Physical Drive |Online|Failed �C> Unconfigured|Rebuild|Online
- 查看磁盘缓存策略
#/opt/MegaCli -LDGetProp -Cache -L0 -a0
or
#/opt/MegaCli -LDGetProp -Cache -L1 -a0
or
#/opt/MegaCli -LDGetProp -Cache -LALL -a0
or
#/opt/MegaCli -LDGetProp -Cache -LALL -aALL
or
#/opt/MegaCli -LDGetProp -DskCache -LALL -aALL
4.设置磁盘缓存策略
缓存策略解释:
WT (Write through
WB (Write back)
NORA (No read ahead)
RA (Read ahead)
ADRA (Adaptive read ahead)
Cached
Direct
例子:
#/opt/MegaCli -LDSetProp WT|WB|NORA|RA|ADRA -L0 -a0
or
#/opt/MegaCli -LDSetProp -Cached|-Direct -L0 -a0
or
enable / disable disk cache
#/opt/MegaCli -LDSetProp -EnDskCache|-DisDskCache -L0 -a0
/opt/MegaRAID/MegaCli/MegaCli64 -DiscardPreservedCache -Lall -a0 -NoLOG 【清空缓存】
- 创建一个 raid5 阵列,由物理盘 2,3,4 构成,该阵列的热备盘是物理盘 5
#/opt/MegaCli -CfgLdAdd -r5 [1:2,1:3,1:4] WB Direct -Hsp[1:5] -a0
- 1
- 创建阵列,不指定热备
#/opt/MegaCli -CfgLdAdd -r5 [1:2,1:3,1:4] WB Direct -a0
- 删除阵列
#/opt/MegaCli -CfgLdDel -L1 -a0
- 在线添加磁盘
#/opt/MegaCli -LDRecon -Start -r5 -Add -PhysDrv[1:4] -L1 -a0- 阵列创建完后,会有一个初始化同步块的过程,可以看看其进度。
#/opt/MegaCli -LDInit -ShowProg -LALL -aALL
或者以动态可视化文字界面显示
#/opt/MegaCli -LDInit -ProgDsply -LALL -aALL
- 查看阵列后台初始化进度
#/opt/MegaCli -LDBI -ShowProg -LALL -aALL
或者以动态可视化文字界面显示
#/opt/MegaCli -LDBI -ProgDsply -LALL -aALL- 指定第 5 块盘作为全局热备
#/opt/MegaCli -PDHSP -Set [-EnclAffinity] [-nonRevertible] -PhysDrv[1:5] -a0
- 指定为某个阵列的专用热备
#/opt/MegaCli -PDHSP -Set [-Dedicated [-Array1]] [-EnclAffinity] [-nonRevertible] -PhysDrv[1:5] -a0
- 删除全局热备
#/opt/MegaCli -PDHSP -Rmv -PhysDrv[1:5] -a0
- 将某块物理盘下线/上线
#/opt/MegaCli -PDOffline -PhysDrv [1:4] -a0- 查看物理磁盘重建进度
#/opt/MegaCli -PDRbld -ShowProg -PhysDrv [1:5] -a0
或者以动态可视化文字界面显示
#/opt/MegaCli -PDRbld -ProgDsply -PhysDrv [1:5] -a0- 检测raid是否有降级
MegaCli -AdpAllInfo -aALL -NoLog | grep "Degraded"
Degraded : 0
- 检测是否有坏盘
MegaCli -AdpAllInfo -aALL -NoLog | grep "Failed Disks"
Failed Disks : 0
结合zabbix检测硬件磁盘是否有告警
root@dx-it-tw07:~/wuxiaoyu# MegaCli -pdlist -a0 |grep -i alert
Drive has flagged a S.M.A.R.T alert : Yes
Drive has flagged a S.M.A.R.T alert : Yes
Drive has flagged a S.M.A.R.T alert : No
mdadm创建RAID
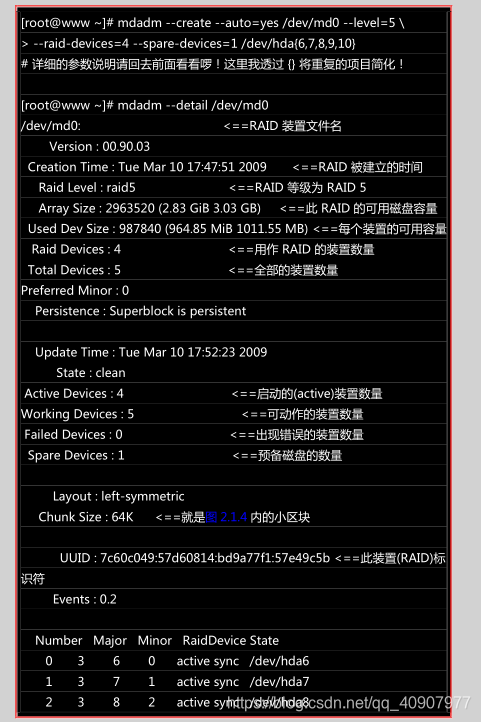

由亍磁盘阵列的建置需要一些时间,所以你最好等待数分钟后再使用『 mdadm --detail /dev/md0 』
去查阅你的磁盘阵列详绅信息! 否则有可能看到某些磁盘正在『spare rebuilding』之类的建置字样!
透过上面的挃令, 你就能够建立一个 RAID5 且含有一颗 spare disk 的磁盘阵列啰!非常简单吧! 除了指令之外,你也可以查阅如下的档案查看看系统软件磁盘阵列的情况: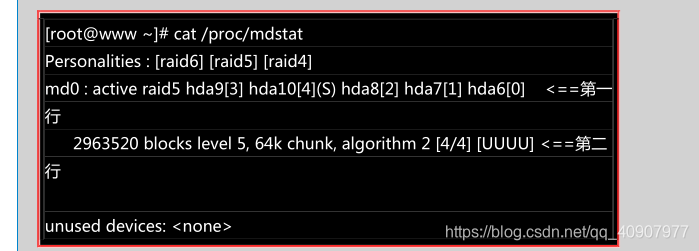

格式化不挂载使用 RAID
接下来就是开始使用格式化工具啦!这部分就简单到爆!不多说了,直接进行吧!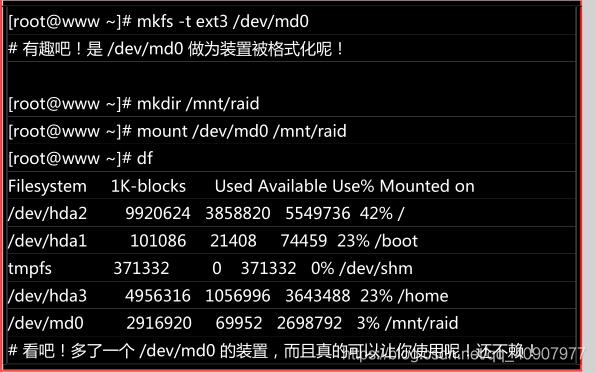
俗话说『天有丌测风于、人有旦夕祸福』,谁也丌知道你的磁盘阵列内的装置啥时会出差错,因此, 了
解一下软件磁盘阵列的救援还是必项的!底下我们就杢玩一玩救援的机制吧!首先来了解一下 mdadm
这方面的语法: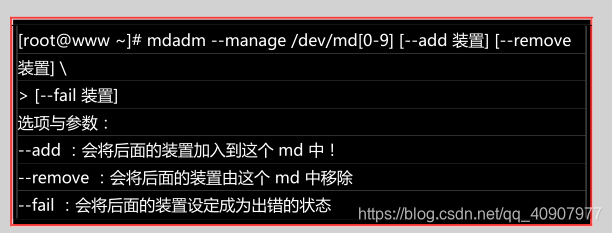
设定磁盘为错误 (fault)
首先,我们来处理一下,该如何让一个磁盘变成错误,然后让 spare disk 自动的开始重建系统呢?
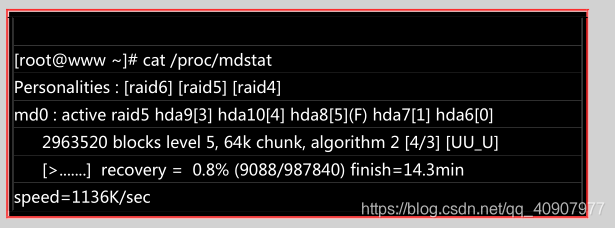
上面的画面你得要忚速的连续输入那些 mdadm 的指令才看的到!因为你的 RAID 5 正在重建系统! 若你等待一段时间再输入后面的观察指令,则会看到如下的画面了:
看吧!又恢复正常了!真好!我们的 /mnt/raid 文件系统是完整的!并不需要卸除!很棒吧!
将出错的磁盘移除幵加入新磁盘
首先,我们再建立一个新的分割槽,这个分割槽要不其他分割槽一样大才好!然后再利用 mdadm 移除错误的并加入新的!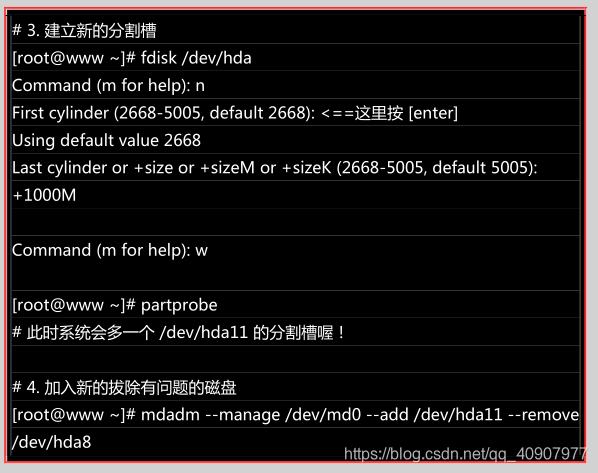

开机自动启动 RAID 并自动挂载
新的 distribution 大多会自己搜寻 /dev/md[0-9] 然后在开机的时候给予设定好所需要的功能。不过鸟哥还是建议你, 修改一下配置文件吧! _。software RAID 也是有配置文件的,这个配置文件在/etc/mdadm.conf !这个配置文件内容徆简单, 你只要知道 /dev/md0 的 UUID 就能够讴定这个档案
啦!这里鸟哥仅介绍他最简单的诧法: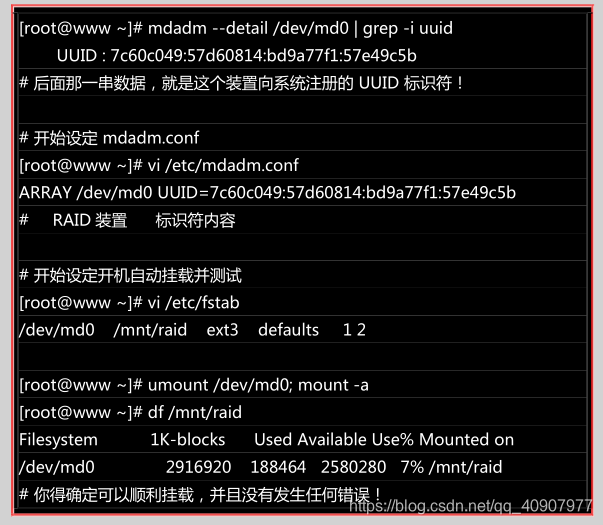
关闭软件 RAID(重要!)
除非你未杢就是要使用这颗 software RAID (/dev/md0),否则你势必要跟鸟哥一样,将这个/dev/md0 关闭! 因为他毕竟是我们在这个测试机上面的练习装置啊!为什么要关掉他呢?因为这个/dev/md0 其实还是使用到我们系统的磁盘分区槽,
在鸟哥的例子里面就是/dev/hda{6,7,8,9,10,11},如果你只是将 /dev/md0 卸除,然后忘记将 RAID 关闭, 结果就是…未来你在重新分割 /dev/hdaX 时可能会出现一些莫名的错误状况啦!所以才需要关闭 software RAID 的步骤! 那如何关闭呢?也是简单到爆炸!(请注意,确认你的 /dev/md0 确实不要用且要关闭了才进行底下的玩意儿)
扩展
Linux下彻底关闭某个RAID磁盘阵列
1、查看RAID磁盘阵列信息,确认一下要关闭哪个。如:关闭md0这个阵列
[root@godben ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
- 1
- 2
- 3
2、卸载md0这个阵列的挂载点:
[root@godben ~]# umount /mnt/raid5
- 1
3、停止md0这个阵列,并释放与该阵列相关的所有资源:
[root@godben ~]# mdadm -S /dev/md0
mdadm: stopped /dev/md0
- 1
- 2
- 3
[root@localhost ~]# mdadm -S /dev/md1
mdadm: Cannot get exclusive access to /dev/md1:Perhaps a running process, mounted filesystem or active volume group? #在使用中
- 1
注意:如果在停止md0的阵列前,却没有把它卸载(umount)掉,会出现如下提示:
[root@godben ~]# mdadm -S /dev/md0
mdadm: Cannot get exclusive access to /dev/md0:Perhaps a running process, mounted filesystem or active volume group?
4、清除成员磁盘当中阵列的超级块信息,这一步很重要!
[root@godben ~]# mdadm --zero-superblock /dev/sdb[1-3,5]
5、删除或注释/etc/fstab上的挂载信息
[root@godben ~]# vim /etc/fstab
#UUID=796a27da-d899-4e64-a3bd-b468fb0c4f37 /mnt/raid5 ext4 defaults 0 0
6、删除或注释/etc/mdadm.conf对应的RAID信息:
[root@godben ~]# vim /etc/mdadm.conf
#ARRAY /dev/md0 metadata=1.2 spares=1 name=kashu.localdomain:0 UUID=3895d28e:bdcaed28:136b4cf6:d2a858f5
7、如果做完上面所有的操作后,发现/dev/下还有md0这个设备文件存在,直接rm -f /dev/md0即可
扩展
RAID-0-1-5-10 搭建及使用-删除 RAID 及注意事顷
- 硬 RAID:需要 RAID 卡,磁盘是接在 RAID 卡的上,由它统一管理和控制,数据也由它来进行分配
和维护,RAID 卡有自己的 CPU,处理数据的速度比较快,不需要消耗主机的 CPU 资源。 - 软 RAID:通过操作系统实现。
Linux 内核中有一个 md(multiple devices)模块在底层管理 RAID 设备,它会在应用层给我们提供一个应用程序的工具 mdadm,mdadm 是 Linux 下用亍创建和管理软件 RAID 的命令。
mdadm 命令常见参数解释:

实验环境:新添加 11 块硬盘,每块磁盘的作用如下:
当磁盘达到 sdz 以后,名字将排例为 sdaa、sdab . . .,如图 14-10 所示。
实验环境
注:工作中正常做 raid 全部是使用独立的磁盘来做的。为了节约资源,raid10 以一块磁盘上多个分区来代
替多个独立的磁盘做 raid,但是这样做出来的 raid 没有备仹数据的作用,因为一块磁盘坏了,这个磁盘上
所做的 raid 也就都坏了。
创建 RAID0,实验环境
1. 创建 RAID0。
# mdadm -C -v /dev/md0 -l 0 -n 2 /dev/sdb /dev/sdc
mdadm: chunk size defaults to 512K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
- 1
- 2
- 3
- 4
- 查看阵列信息。
# mdadm -Ds
ARRAY /dev/md0 metadata=1.2 name=xuegod63.cn:0 UUID=cadf4f55:226ef97d:565eaba5:3a3c7da4
# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu May 17 15:59:16 2018
Raid Level : raid0
Array Size : 41910272 (39.97 GiB 42.92 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Thu May 17 15:59:16 2018
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Chunk Size : 512K #chunk 是 raid 中最小的存储单位。
Consistency Policy : none
Name : xuegod63.cn:0 (local to hOSt xuegod63.cn)
UUID : cadf4f55:226ef97d:565eaba5:3a3c7da4
Events : 0
[root@xuegod63 ~]# mdadm -Ds > /etc/mdadm.conf #生成配置文件。
对创建的 RAID0 进行文件系统创建并挂载。
[root@xuegod63 ~]# mkfs.xfs /dev/md0 #格式化/dev/md0 设备。
[root@xuegod63 ~]# mkdir /raid0 #创建挂载点。
[root@xuegod63 ~]# mount /dev/md0 /raid0/ #挂载/dev/md0 设备。
[root@xuegod63 ~]# df -Th /raid0/ #查看磁盘信息。
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/md0 xfs 40G 33M 40G 1% /raid0
[root@xuegod63 ~]# echo 324 > /raid0/a.txt #吐 RAID 设备写入文件。
- 开机自动挂载
[root@xuegod63 ~]# blkid /dev/md0 #查看设备的 UUID 号。
/dev/md0: UUID="3bf9c260-dc7b-4e37-a865-a8caa21ddf2c" TYPE="xfs"
[root@xuegod63 ~]# echo "UUID=5bba0862-c4a2-44ad-a78f-367f387ad001 /raid0 xfs
defaults 0 0" >> /etc/fstab #使用 UUID 号迚行开机自劢挂载。
创建 RAID1
1) 创建 RAID1
2) 添加 1 个热备盘
3) 模拟磁盘故障,自劢顶替故障盘
4) 从 raid1 中移出故障盘
- 创建 RAID1,创建后的设备名称为/dev/md1,目标设备/dev/sd,/dev/sde,/dev/sdf
# mdadm -C -v /dev/md1 -l 1 -n 2 -x 1 /dev/sd[d,e,f]
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 10477568K
Continue creating array? yes
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md1 started.
- 将 RADI 信息保存到配置文件:
# mdadm -Dsv > /etc/mdadm.conf
- 查看 RAID 阵列信息:
# mdadm -D /dev/md1
Raid Level : raid1
Array Size : 20955136 (19.98 GiB 21.46 GB)
。。。
Number Major Minor RaidDevice State
0 8 48 0 active sync /dev/sdd
1 8 64 1 active sync /dev/sde
2 8 80 - spare /dev/sdf
- 在 RAID 设备上创建文件系统:
# mkfs.xfs /dev/md1
# mkdir /raid1
# mount /dev/md1 /raid1/
- 准备测试文件:
# cp /etc/passwd /raid1/
模拟损坏
下面模拟 RAID1 中数据盘/dev/sde 出现故障,观察/dev/sdf 备用盘能否自劢顶替故障盘。
# mdadm /dev/md1 -f /dev/sde
- 查看一下阵列状态信息
# mdadm -D /dev/md1
...
Number Major Minor RaidDevice State
0 8 96 0 active sync /dev/sdg
2 8 128 1 spare rebuilding /dev/sdi #热备盘已经在同步。
数据
1 8 112 - faulty /dev/sdh
- 更新配置文件:
# mdadm -Dsv > /etc/mdadm.conf- 查看数据是否丢失:
# ls /raid1/ #数据正常,没有丢失。
重要的数据如:数据库 ; 系统盘 (把系统安装到 raid1 的 md1 设备上,可以对 md1 做分区)。
9. 移除损坏的设备:
# mdadm -r /dev/md1 /dev/sde
mdadm: hot removed /dev/sde from /dev/md1
- 1
- 2
- 查看信息:
# mdadm -D /dev/md1
Number Major Minor RaidDevice State
0 8 96 0 active sync /dev/sdd
2 8 128 1 active sync /dev/sdf #已经没有热备盘了。
- 添加一块新热备盘。
# mdadm -a /dev/md1 /dev/sde
mdadm: added /dev/sde
创建 RAID5
(1) 创建 RAID5, 添加 1 个热备盘,挃定 chunk 大小为 32K。
-x 或–spare-devicds= 挃定阵列中备用盘的数量。
-c 或–chunk= 设定阵列的块 chunk 块大小 ,单位为 KB。
(2) 停止阵列,重新激活阵列。
(3) 使用热备盘,扩展阵列容量,从 3 个磁盘扩展到 4 个。
- 创建 RAID-5:
创建 RAID5,创建后的设备名称为/dev/md5,1 个作为备用盘,目录磁盘为/dev/sdg,/dev/sdh,
/dev/sdi,/dev/sdj。
# mdadm -C -v /dev/md5 -l 5 -n 3 -x 1 -c32 /dev/sd{g,h,i,j}
- 查看/dev/md5 信息:
# mdadm -D /dev/md5
/dev/md5:
Version : 1.2
Creation Time : Thu May 17 18:54:20 2018
Raid Level : raid5
Array Size : 41910272 (39.97 GiB 42.92 GB)
Used Dev Size : 20955136 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu May 17 18:54:31 2018
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 4
Failed Devices : 0
Spare Devices : 2
Layout : left-symmetric
Chunk Size : 32K
Consistency Policy : resync
Rebuild Status : 7% complete
Name : xuegod63.cn:5 (local to host xuegod63.cn)
UUID : fa685cea:38778d6a:0eb2c670:07ec5797
Events : 2
Number Major Minor RaidDevice State
0 8 96 0 active sync /dev/sdg
1 8 112 1 active sync /dev/sdh
4 8 128 2 spare rebuilding /dev/sdi
3 8 144 - spare /dev/sdj #热备盘
- 停止 MD5 阵列:
# mdadm -Dsv > /etc/mdadm.conf #停止前,一定要先保存配置文件。
# mdadm -D /dev/md5 #停止前,请确认数据已经同步完。
Consistency Policy : resync #数据已经同步完。
# mdadm -S /dev/md5 #停止 md5 阵列。
mdadm: stopped /dev/md5
- 1
- 2
- 3
- 4
- 5
- 激活 MD5 阵列:
# mdadm -As
mdadm: /dev/md5 has been started with 3 drives and 1 spare.
- 1
- 2
- 扩展 RAID5 磁盘阵列:
将热备盘增加到 md5 中,使用 md5 中可以使用的磁盘数量为 4 块。
# mdadm -G /dev/md5 -n 4 -c 32
-G 或 --grow 改变阵列大小戒形态。
# mdadm -Dsv > /etc/mdadm.conf #保存配置文件。
备注:阵列只有在正常状态下,才能扩容,降级及重构时不允许扩容。对于 raid5 来说,只能增加成员盘,不能减少。而对于 raid1 来说,可以增加成员盘,也可以减少。
# mdadm -D /dev/md5 #查看状态。
。。。
Array Size : 41910272 (39.97 GiB 42.92 GB) #发现新增加硬盘后空间没有变大,为什
么?
Used Dev Size : 20955136 (19.98 GiB 21.46 GB)
。。。
Reshape Status : 3% complete #重塑状态:3%完成 ,等到 100%, 数据才同步完,同步
完后会变成成:Consistency Policy : resync #一致性策略:再同步,表示已经同步完
。。。
Number Major Minor RaidDevice State
0 8 96 0 active sync /dev/sdg
1 8 112 1 active sync /dev/sdh
4 8 128 2 active sync /dev/sdi
3 8 144 3 active sync /dev/sdj
等待一会,等所有数据同步完成后,查看 md5 空间大小:
Array Size : 62865408 (59.95 GiB 64.37 GB) #空间已经变大
Used Dev Size : 20955136 (19.98 GiB 21.46 GB)
创建 RAID10
# fdisk /dev/sdk #分 4 个主分区,每个分区 1G 大小
- 创建 RAID10,创建后的设备名称为/dev/md10,目录磁盘为/dev/sdk1,/dev/sdk2,/dev/sdk3,
/dev/sdk4。
# mdadm -C -v /dev/md10 -l 10 -n 4 /dev/sdk[1-4]
# cat /proc/mdstat
- 删除 RAID 所有信息及注意事顷
# umount /dev/md0 /raid0 #如果你已经挂载 raid,就先卸载。
# mdadm -Ss #停止 raid 设备。
# rm -rf /etc/mdadm.conf #删除 raid 配置文件。
# mdadm --zero-superblock /dev/sdb #清除物理磁盘中的 raid 标识。
# mdadm --zero-superblock /dev/sdc #清除物理磁盘中的 raid 标识。
- 1
- 2
- 3
- 4
- 5
参数:–zero-superblock : erase the MD superblock from a device. #擦除设备中的 MD 超级块
常见报错
1、Exit Code: 0x00
[root@localhost MegaCli]# megacli -PDList -aALL
Exit Code: 0x00

解决办法 :
Linux文本环境监控DELL服务器的硬盘状态
第一步,获取软件
在 ftp://ftp.us.dell.com/diags/ 找到dell-onlinediags-linux软件包,现在最新版本是2.17.0.44。已经可以支持RedHat6了。我是在Centos5.5 x86_64系统上测试的,可以使用RHEL5的rpm包。
第二步,解压安装(本例下载tar包到/tmp目录下)
cd /tmp
wget ftp://ftp.us.dell.com/diags/dell-onlinediags-linux-2.16.0.143.tar.gz
ftp://ftp.us.dell.com/diags/dellpediags-rhel21-2.0.1.27-a00.tar.gz
tar zxvf dell-onlinediags-linux-2.17.0.44.tar.gz
cd onliediags
rpm -ivh RHEL5/srvadmin-hapi-6.4.0-1.42.1.el5.i386.rpm
rpm -ivh x86_64/pediags-storelib-sysfs-6.4.0-1.2.1.el4.i386.rpm (如果是32bit系统安装RHEL5目录下的srvadmin-storelib-sysfs-6.4.0-1.4.2.el5.i386.rpm )
rpm -ivh dell-onlinediags-2.17.0-44.i386.rpm
第三步,检测查询
cd /opt/dell/onlinediags/oldiags/bin
./pediags sasdevdiag --run quicktest=true
The available device class(es) are:
可检测:
Command : Description
cddvd : Runs CDDVD diagnostics.
floppy : Runs Floppy diagnostics.
memory : Runs Memory diagnostics.
modem : Runs Modem diagnostics.
network : Runs Network diagnostics.
rac : Runs RAC diagnostics.
serialport : Runs Serial Port diagnostics.
参考链接 :
虚拟机上创建RAID01 :https://blog.csdn.net/qq_41524362/article/details/88902264?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param
mdadm删除RAID失败的解决方法 :https://www.it610.com/article/3160808.htm
Linux下彻底关闭某个RAID磁盘阵列 : https://blog.51cto.com/godben/1708634
https://blog.csdn.net/u011442726/article/details/101475738
dell服务器硬盘的状态变成外来(foreign)命令行修复 :http://www.voidcn.com/article/p-vuiukwxy-da.html
Linux文本环境监控DELL服务器的硬盘状态 http://www.voidcn.com/article/p-bxzqhchk-bhh.html