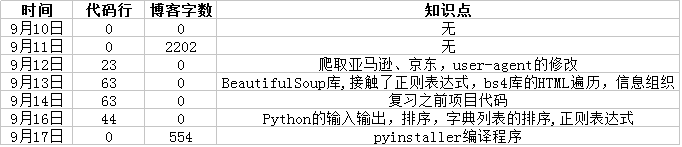
一、本次程序一共有4个主要功能及需求:
功能1 小文件输入;单词总数不能包括重复的单词;
功能2 支持命令行输入英文作品的文件名;
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计;只列出前10个高频词汇;
功能4 从控制台读入英文单篇作品。
二、部分功能的代码展示
本次编程采用的Python,采用的Python版本是3.5.1.其中我觉得比较难的地方有:
将字典转化为列表结构,进行键值的排序,以输出前十个高频词汇;
1 def dict2list(dic:dict):#将字典转化为列表 2 keys = dic.keys() 3 vals = dic.values() 4 lst = [(key, val) for key, val in zip(keys, vals)] 5 return lst
1 print ('total', len(words_dict) , 'words',end=' ' ) 2 for k,v in sorted(dict2list(words_dict), key=lambda d:d[1], reverse = True): 3 count = count +1 #按照value进行排序 4 if count > 10: 5 break #输出十个次数最多的单词记录 6 print ("{:<10} {:<15}".format(k,v) )
正则表达式删除除英文及数字以外的其他所有字符;
1 match = re.findall(r'[^a-zA-Z0-9]+', line)# 只要英文单词,删掉其他字符 2 for i in match: 3 line = line.replace(i, ' ') 4 lines_list = line.split()#对单词进行统计 5 for i in lines_list: 6 if i not in words_dict: 7 words_dict[i] = 1 8 else: 9 words_dict[i] = words_dict[i] + 1
代码地址:https://git.coding.net/liuchengzhi0944/word_dirt.git
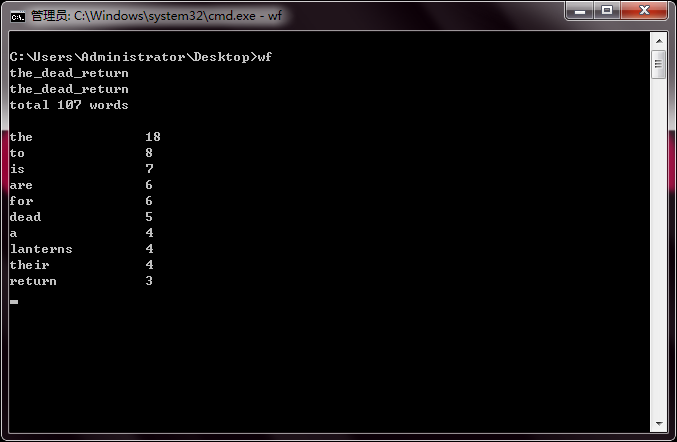
三、功能展示

四、PSP


在完成文本输入这块,因为之前做过类似的语句,所以编写起来较为轻松;完成文本进行分析这部分功能时,因为不能熟练的使用正则表达式的及对字典这一数据类型的不熟悉,造成了超时;输出结果这一功能,严重超时,原因是在对字典进行排序的是遇到了困难,在如何输出十个单词数据及在输出对齐这里遇到了困难,;在对项目进行测试实现这一不部分,文件读取,文本的编码格式让我的测试工作也出现了麻烦。