以抓取猫眼的Top100热门电影的信息为例:
# -*- coding: utf-8 -*- import urllib import urllib2 import re import json import lxml.html import time import datetime from bs4 import BeautifulSoup import multiprocessing from multiprocessing import Pool import sys reload(sys) sys.setdefaultencoding('utf8') fd = open('E:\result.txt', 'w') URL = 'http://maoyan.com/board/4' def download(url, user_agent='wswp', num_try=2): headers = {'User_agent': user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print 'Download error', e.reason html = None if num_try > 0: if hasattr(e, 'code') and 500 <= e.code < 600: return download(url, user_agent, num_try - 1) elif e.code == 403: return None return html def get_message(url): html = download(url) soup = BeautifulSoup(html,'lxml') results = soup.find_all(name = 'div',attrs = {'class':'movie-item-info'}) res_rank = r'<i class="board-index board-index-.*?">(.*?)</i>' rank = re.findall(res_rank,html) res_title = r'<p class="name"><.*?>(.*?)</a>' title = re.findall(res_title,html,re.S|re.M) res_major = r'<p class="star">(.*?)</p>' major = re.findall(res_major,html,re.S|re.M) res_data = r'<p class="releasetime">(.*?)</p>' data = re.findall(res_data,html,re.S|re.M) res_inte = r'<i class="integer">(.*?)</i>' inte = re.findall(res_inte,html,re.S|re.M) res_pe = r'<i class="fraction">(.*?)</i>' pe = re.findall(res_pe,html,re.S|re.M) for each in range(0,9): print title[each] mess = 'Rand:'+rank[each] fd.write(mess) mess = '电影:' + title[each] fd.write(mess) mess = '评分 ' + inte[each] + pe[each] fd.write(mess) mess = major[each].replace(' ','') fd.write(mess) mess = data[each] fd.write(mess) fd.write(' ') def main(offset): url = 'http://maoyan.com/board/4?offset={}'.format(offset) print url get_message(url) if __name__ == '__main__': t = time.time() for i in range(10): main(i*10) t1 = time.time() print 'Total time:' print t1 - t fd.close()
单进程的代码所花费的时间是:
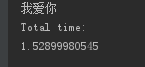
利用多进程的Pool的时间是:

pool更改的代码是:
pool = Pool() pool.map(main, [i * 10 for i in range(10)])