深入Mysql
在学习sql,使用sql后,有时候不理解sql代码为什么这样写?如果能了解sql代码的运行,就能够深入理解了。
8.2.1.7 Nested-Loop Join Algorithms 嵌套循环连接算法
https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html
简单的NLJ算法
读取行,在一个循环内,从第一个表每次读一行x,并传递x到内部嵌套的循环(被join的下一个表格的处理)。
这个过程被重复多次,每次处理一个被join的表格。
⚠️本质就是嵌套循环,一个表一个循环。层层嵌套。
例子:3个表关联。所以嵌套3层。
Table Join Type t1 range t2 ref t3 ALL for each row in t1 matching range { for each row in t2 matching reference key { for each row in t3 { if row satisfies join conditions, send to client } } }
Block Nested-Loop Join Algorithm
优化的算法。
8.8.2 EXPLAIN Output Format
explain声明提供了MYsql如何执行一个声明的详细信息。
比如select声明,explain会返回:每个表一行信息。
Mysql使用nested-loop join方法来处理所有的join连接。因此,mysql会从第一个表读一行数据,然后在第二个表找到一个匹配的行数据,在然后去往第三个表。。。当所有的表都被处理,Mysql会输出被选择的列,然后返回到上一个表,寻找更多的匹配行。
⚠️上面的过程,就是嵌套循环处理的过程。
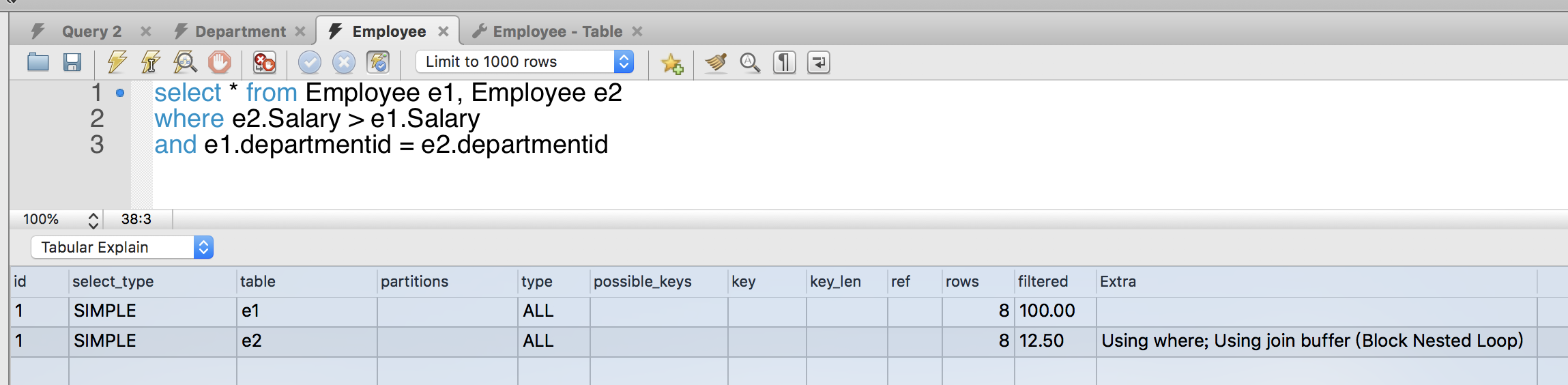
explain 输出列的解释:
下面的图,显示了explain声明中常用的输出列的信息:
- id, 查询中select声明的序列号。
- select_type: select类型
- estimate: 被检测的row的数量估值。
- filtered: Percentage of rows filtered by table condition, 通过筛选条件,被检索的行的百分比。
- extra: 额外的信息。
explain用JSON格式来描述:
- id列,在json中是select_id属性
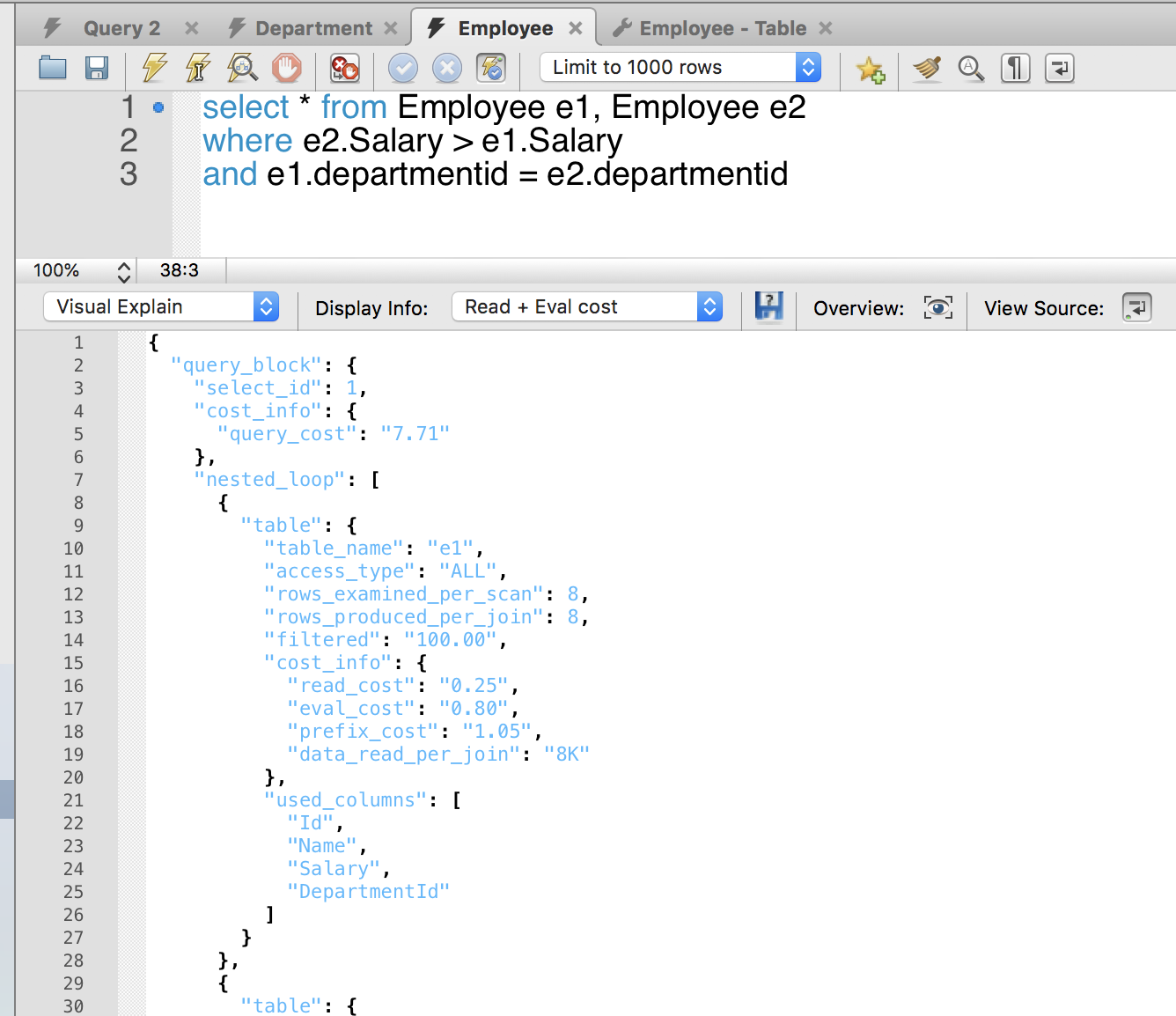
每一个输出列都提供了一个表格的信息。简单的说明见:Table 8.1, “EXPLAIN Output Columns”
详细解释
select_type:
- simple: 没有使用UNION或子查询
- primary: Outermost
SELECT 最外层的主表。 - UNION: 在一个UNION内的第2个及之后的select声明
- Union result: 一个UNION的结果
- subquery: 子查询中的第一个select
- derived: 衍生表
- dependent derived: 衍生表,依赖于另一个表
- 其他:具体见https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-output-column-table
key:
key/index,Mysql实际决定使用的。
ref:
尚未理解。
rows:
Mysql估计执行查询时会被检测的行的数量。使用InnoDB引擎,这是一个估计值。
filtered:
由表的筛选条件而被检索的row的数量占表格所有行的比例。
最大值是100,表示没有进行筛选。
possible_keys:
搜索时,可能使用的索引。
keys:
搜索时,决定使用的索引。
EXPLAIN Join Types
system: 表格只有一行(系统相关?)
const: (没理解)
all: 全表扫描
index: 全索引扫描。
index_merge: 合并索引。例子:
# popluation和area两个字段都创建了索引 # 所以,下面的查询语句,就没有全表扫描,而是对每个字段执行索引扫描 select name, population, area from world where population > 25000000 or area > 3000000
range: 只有在给定范围内的row会被检索,使用一个index来搜索这些rows。(没遇到实际例子)
语句分析案例:
部分解答;
select name, Salary from Employee e1 where 3 > ( select count(distinct Salary) from Employee e2 where e2.Salary > e1.Salary and e1.departmentid = e2.departmentid ) order by e1.departmentid , Salary desc
使用explain分析

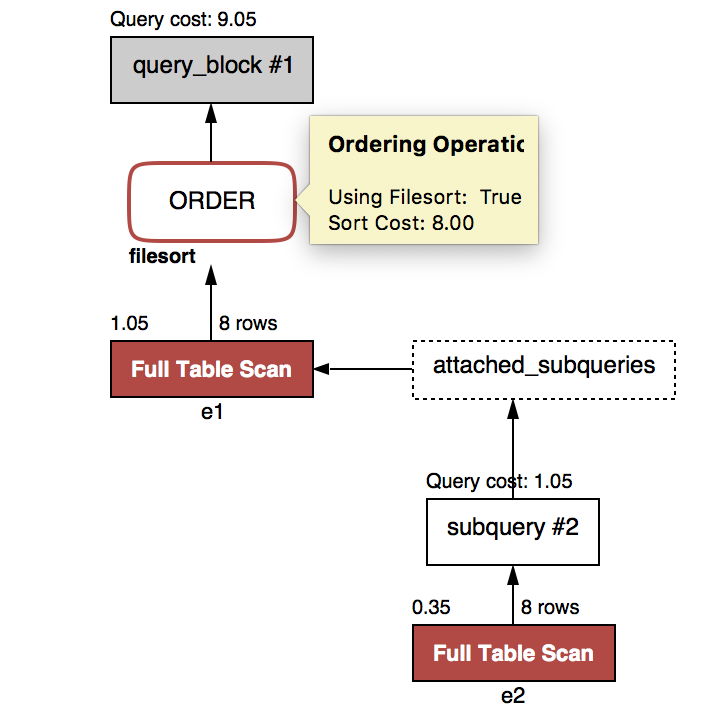
- 本select声明带一个dependent subquery。⚠️没有使用join。没有使用index.
- 子查询创建了一个临时表。
- 2个全表扫描。
首先,Mysql通过依赖的子查询,建立一个attached_subqueries函数,
然后,主表的每行数据作为函数参数,函数返回一个结果。
最后,直到主表所有行被执行完成,返回的结果集合被排序order。
Visual Explain Plan
https://dev.mysql.com/doc/workbench/en/wb-performance-explain.html
标准框--红色:全表扫描(花费极高),全索引扫描(花费高)
圆脚框--group/sort,分组或排序
钻石框--joins
Framed boxes(有外框)--子查询。
Join type连接类型:
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#explain-join-types
| 名字 | 颜色 | 视图上的文本 | 解释(资源消耗) |
| system | blue | Single row: system constant | Very low cost |
| CONST | Blue | Single row: constant | Very low cost |
| ref | green | Non-Unique Key Lookup | 中低,行多消耗就多 |
力扣550例子
Create table If Not Exists Activity (player_id int, device_id int, event_date date, games_played int) Truncate table Activity insert into Activity (player_id, device_id, event_date, games_played) values ('1', '2', '2016-03-01', '5') insert into Activity (player_id, device_id, event_date, games_played) values ('1', '2', '2016-03-02', '6') insert into Activity (player_id, device_id, event_date, games_played) values ('2', '3', '2017-06-25', '1') insert into Activity (player_id, device_id, event_date, games_played) values ('3', '1', '2016-03-02', '0') insert into Activity (player_id, device_id, event_date, games_played) values ('3', '4', '2018-07-03', '5')
编写一个 SQL 查询,报告在首次登录的第二天再次登录的玩家的分数,四舍五入到小数点后两位。换句话说,您需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
解答答案:
select round(cast(count(1)/@total_user as decimal(3,2)), 2)as fraction from activity a1 inner join ( select player_id, min(event_date) as first_day from activity group by player_id) t1 on t1.player_id = a1.player_id and t1.first_day = date_sub(a1.event_date, interval 1 day), (select @total_user :=count(distinct player_id) from activity) t2
图:
