Java源码之String
说在前面:
为什么看源码: 最好的学习的方式就是模仿,接下来才是创造。而源码就是我们最好的模仿对象,因为写源码的人都不是一般的人,所以用心学习源码,也就可能变成牛逼的人。其次,看源码,是一项修练内功的重要方式,书看百遍其意自现,源码也是一样,前提是你不要惧怕源码,要用心的看,看不懂了,不要怀疑自己的智商,回过头来多看几遍,我就是这样做的,一遍有一遍的感受,等你那天看源码不由的惊叹一声,这个代码写得太好了,恭喜你,你已经离优秀不远了。最后,看源码,能培养我们的编程思维,当然这个层次有点高了,需要时间积累,毕竟我离这个境界也有点远。
今天就来谈谈java的string的源码实现,后续我也会写javaSe的源码系列,欢迎围观和交流。


1.继承关系
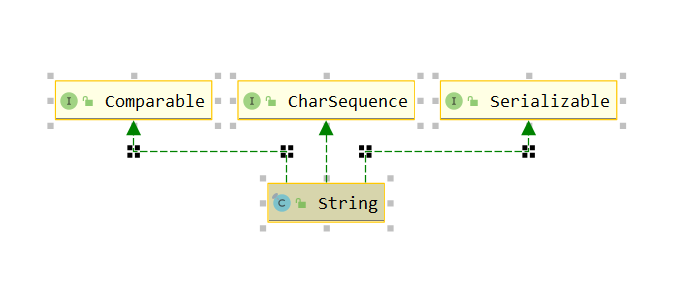
继承三个接口的说明:
Comparable接口:
实现对象之间比较的接口,它的核心方法只有一个:
public int compareTo(T o);
CharSequence接口:
CharSequence是char值的可读序列。 该接口提供对许多不同种类的char序列的统一只读访问。CharSequence是一个接口,它只包括length(), charAt(int index), subSequence(int start, int end)这几个API接口。除了String实现了CharSequence之外,StringBuffer和StringBuilder也实现了 CharSequence接口。
那么String为什么实现Charsequence这个接口呢。这里就要涉及一个java的重要特性,也就是多态。看下面的代码
public void charSetTest(CharSequence charSequence){
System.out.println(charSequence+"实现了多态");
}
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
StringTest strTest = new StringTest();
strTest.charSetTest(new String("我是String"));
strTest.charSetTest(new StringBuffer("我是StringBuffer"));
strTest.charSetTest(new StringBuilder("我是StringBuilder"));
}
执行结果:
我是String实现了多态
我是StringBuffer实现了多态
我是StringBuilder实现了多态
继承这个接口的原因就很明显:
因为String对象是不可变的,StringBuffer和StringBuilder这两个是可变的,所以我们在构造字符串的过程中往往要用到StringBuffer和StringBuilder。如果那些方法定义String作为参数类型,那么就没法对它们用那些方法,先得转化成String才能用。但StringBuffer和StringBuilder转换为String再转换过来很化时间的,用它们而不是直接用String的“加法”来构造新String本来就是为了省时间。
Serializable接口:
继承该接口,就是表明这个类是是可以别序列化的,这里就标记了string这个类是可以被序列化的,序列化的定义以及使用时机可以移步这里。
2.常用方法的使用和源码解析:
2.1构造方法
string总共提供了15种构造方法:
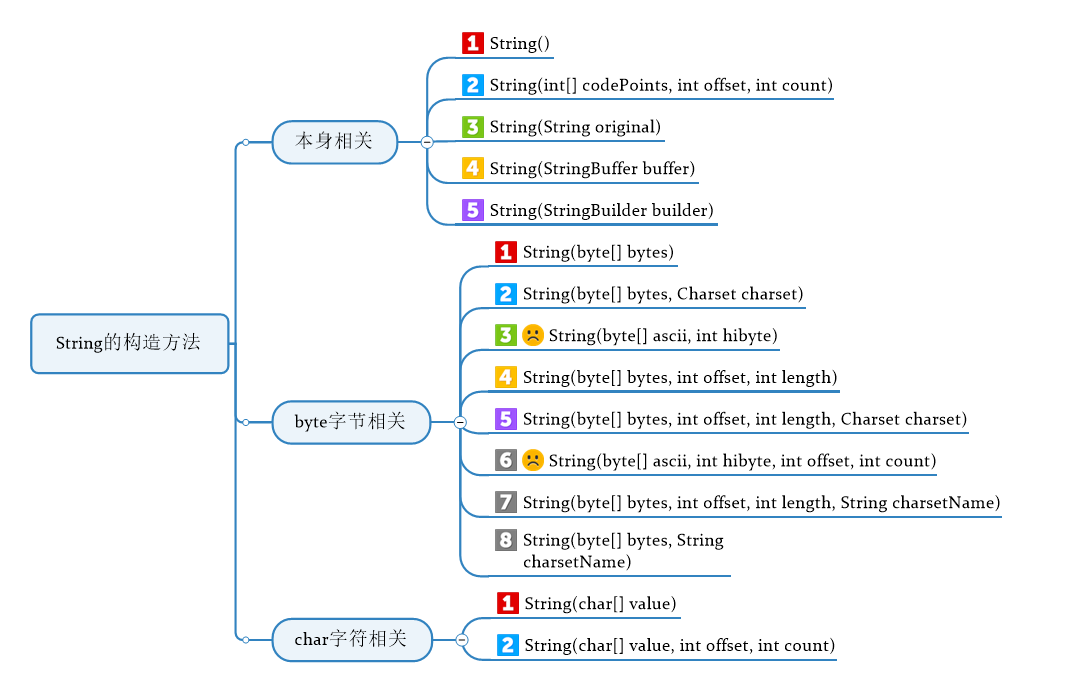
当然,这么多的构造方法,只需搞明白四个构造方法就可以了,因为其他的构造方法就是这四个构造方法的调用:
在看构造方法之前,先看看String的属性
private final char value[];
private int hash; // Default to 0
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
通过属性了解到,底层声明了一个final类型的char数组,这个char数组就是String的构造方法的核心,因为String的本质就是字符char(只针对javaSE8 以前的版本),下面来分析有代表的四个构造方法:
-
String()和String(String original)
这两个构造方法我们平时用的比较经常,源码如下:
public String() { this.value = "".value; } public String(String original) { this.value = original.value; this.hash = original.hash; }分析:
通过源码可以看到,核心还是和String类声明的char[]数组value属性建立联系,进而来处理这个属性的值。
在String()这个空构造的方法中,就是属性char数组的值声明为一个空的字符串赋值给属性value.
而在String(String original),也是将方法参数的value的属性赋值给声明char[]数组的value属性,方便String的其他方法对char[]数组处理。
记住,在java的String操作中,大多数情况下还是对char[]数组的操作,这点很重要。
一般情况下定义一个新的字符串,有下面的两种方式:
String chen = new String("chen"); // 这个我们一般不会使用 String chen = "chen";我们一般会选择第二种,这又是什么原因呢:
其实这两种声明的方式在JVM看来时等价的。
划重点:
但是String password="chen",利用了字符串缓冲池,也就是说如果缓冲池中已经存在了相同的字符串,就不会产生新的对象,而直接返回缓冲池中的字符串对象的引用。
如: String a = "chen"; String b = "chen"; String c = new String("chen"); String d = new String("chen"); System.out.println(a==b);//将输出"true";因为两个变量指向同一个对象。利用了字符串的缓冲池 System.out.println(c==d);//将输出"flase";因为两个变量不指向同一个对象。虽然值相同,只有用c.equals(d)才能返回true.所以实际中,建议用第一种,可以减少系统资源消耗。
-
String(char[]vlaue,int offest,int count) 与字符相关的构造方法
源码如下:
public String(char value[], int offset, int count) { if (offset < 0) { throw new StringIndexOutOfBoundsException(offset); } if (count <= 0) { if (count < 0) { throw new StringIndexOutOfBoundsException(count); } if (offset <= value.length) { this.value = "".value; return; } } // Note: offset or count might be near -1>>>1. if (offset > value.length - count) { throw new StringIndexOutOfBoundsException(offset + count); } this.value = Arrays.copyOfRange(value, offset, offset+count); }分析:
这个构造方法的作用就是传入指定大小的char[] 数组,指定一个起始位置,然后构造出从起始位置开始计算的指定长度个数的字符串,具体用法:
public static void main(String[] args) { char[] chars = new char[]{'a','b','c','d'}; // 从chars数组的第二位开始,总数为3个字符的字符串 String rangeChar=new String(chars,1,3); System.out.println(rangeChar); } 输出: abc这个构造方法的核心在于:
this.value = Arrays.copyOfRange(value, offset, offset+count); //而这个方法在追一层,就到了Arrays这个工具类copyOfRange这个方法 public static char[] copyOfRange(char[] original, int from, int to) { int newLength = to - from; if (newLength < 0) throw new IllegalArgumentException(from + " > " + to); char[] copy = new char[newLength]; System.arraycopy(original, from, copy, 0, Math.min(original.length - from, newLength)); return copy; }其实看到这里,他的实现原理就基本清楚了,分析copyOfRange()这个方法的执行步骤:
首先是获取原字符数组的orginal[]要构造字符串的长度,也就是 这一行代码:
int newLength = to - from;然后异常判断,并声明新的数组,来存储原数组指定长度的值
if (newLength < 0) throw new IllegalArgumentException(from + " > " + to); char[] copy = new char[newLength];将原字符数组指定长度的值拷贝到新数组,返回这个数组:
System.arraycopy(original, from, copy, 0, Math.min(original.length - from, newLength)); return copy;最后再将数组的值赋值给String的属性value,完成初始化:
this.value = Arrays.copyOfRange(value, offset, offset+count);归根结底还是和String声明的属性value建立联系,完成相关的操作。
-
String(byte[] bytes,int offest,int length,Charset charset) 字节相关的 构造方法
这个构造方法的作用就是将指定长度的字节数组,构造成字符串,且还可以指定编码值:
涉及的源码如下:
public String(byte bytes[], int offset, int length, Charset charset) { if (charset == null) throw new NullPointerException("charset"); checkBounds(bytes, offset, length); this.value = StringCoding.decode(charset, bytes, offset, length); } // StringCoding中的方法: static char[] decode(Charset cs, byte[] ba, int off, int len) { // 1, 构造解码器 CharsetDecoder cd = cs.newDecoder(); int en = scale(len, cd.maxCharsPerByte()); char[] ca = new char[en]; if (len == 0) return ca; boolean isTrusted = false; if (System.getSecurityManager() != null) { if (!(isTrusted = (cs.getClass().getClassLoader0() == null))) { ba = Arrays.copyOfRange(ba, off, off + len); off = 0; } } cd.onMalformedInput(CodingErrorAction.REPLACE) .onUnmappableCharacter(CodingErrorAction.REPLACE) .reset(); if (cd instanceof ArrayDecoder) { int clen = ((ArrayDecoder)cd).decode(ba, off, len, ca); return safeTrim(ca, clen, cs, isTrusted); } else { ByteBuffer bb = ByteBuffer.wrap(ba, off, len); CharBuffer cb = CharBuffer.wrap(ca); try { CoderResult cr = cd.decode(bb, cb, true); if (!cr.isUnderflow()) cr.throwException(); cr = cd.flush(cb); if (!cr.isUnderflow()) cr.throwException(); } catch (CharacterCodingException x) { // Substitution is always enabled, // so this shouldn't happen throw new Error(x); } return safeTrim(ca, cb.position(), cs, isTrusted); } } private static char[] safeTrim(char[] ca, int len, Charset cs, boolean isTrusted) { if (len == ca.length && (isTrusted || System.getSecurityManager() == null)) return ca; else return Arrays.copyOf(ca, len); }这个方法构造的方法的复杂之处就是在于对于指定编码的处理,但是我们如果看完这个方法调用的整个流程最终还是落到
return Arrays.copyOf(ca, len); 返回一个指定编码的字符数组,然后和String类的value属性建立联系字节数组构造方法的基本逻辑:就是将字节数组转化为字符数组,再和String的value属性建立联系,完成初始化。
-
String(StringBuilder builder) 和String(StringBuffer buffer)与String扩展类相关的构造方法:
这个构造方法就是将StringBuilder或者StringBuffer类初始化String类,源码如下:
public String(StringBuffer buffer) { synchronized(buffer) { this.value = Arrays.copyOf(buffer.getValue(), buffer.length()); } } public String(StringBuilder builder) { this.value = Arrays.copyOf(builder.getValue(), builder.length()); }分析:
核心的代码还是这一句:
this.value = Arrays.copyOf(builder.getValue(), builder.length());
在往下看builder.getValue(),的源码
final char[] getValue() {
return value;
}
返回一个字符数组
这样就能很好理解这个构造方法了: 先利用builder.getValue()将指定的类型转化为字符数组,通过Arrays.copyOf()方法进行拷贝,将返回的数组赋值给String的属性value,完成初始化。
2.2常用的方法分析
String的方法大概有60多个,这里只分析几个常用的方法,了解其他的方法,可以移步javaSE官方文档:

-
字符串转化为字符的方法:charAt(int index)
public char charAt(int index) { //1. 判断异常 if ((index < 0) || (index >= value.length)) { throw new StringIndexOutOfBoundsException(index); } // 2.返回指定位置的字符 return value[index]; }用法示例:
String StrChar = "chen"; char getChar = StrChar.charAt(1); System.out.println(getChar); 输出: h2.字符串转化为字节数组的方法:getBytes()
// 源码 public byte[] getBytes() { return StringCoding.encode(value, 0, value.length); } // encode的源码 static byte[] encode(char[] ca, int off, int len) { String csn = Charset.defaultCharset().name(); try { // use charset name encode() variant which provides caching. return encode(csn, ca, off, len); } catch (UnsupportedEncodingException x) { warnUnsupportedCharset(csn); } try { return encode("ISO-8859-1", ca, off, len); } catch (UnsupportedEncodingException x) { // If this code is hit during VM initialization, MessageUtils is // the only way we will be able to get any kind of error message. MessageUtils.err("ISO-8859-1 charset not available: " + x.toString()); // If we can not find ISO-8859-1 (a required encoding) then things // are seriously wrong with the installation. System.exit(1); return null; } }
用法示例:
String strByte = "chen";
// 将string转化为字节数组
byte[] getBytes = strByte.getBytes();
// 遍历输出
for (byte getByte : getBytes) {
System.out.println(getByte);
}
输出结果:
99
104
101
110
3.返回字符串中指定字符的下标的方法: indexOf(String str):
这里的参数为字符串:
这个方法一共涉及了四个方法,源码如下:
public int indexOf(String str) {
return indexOf(str, 0);
}
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}
static int indexOf(char[] source, int sourceOffset, int sourceCount,
String target, int fromIndex) {
return indexOf(source, sourceOffset, sourceCount,
target.value, 0, target.value.length,
fromIndex);
}
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
// 1. 判断范围
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
// 2,判断目标字符串是否时原子符串的子序列,并返回目标序列的第一个字符在原字符序列的索引。
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
具体执行过程已在方法的注释中进行了说明:
用法示例:
String strIndex = "chen";
int getIndex = strIndex.indexOf("he");
System.out.println(getIndex);
输出:
1
注意:也就是输出字符串中的第一个字符在原子符串中的索引,前提是传入的参数必须是原子符串的子序列,以上面的列子为例,传入的字符串序列必须是chen这个字符串的子序列,才能输出正确的索引,比如传入的序列不是chen的子序列,输出为-1
String strIndex = "chen";
int getIndex = strIndex.indexOf("hew");
System.out.println(getIndex);
输出:
-1
使用这个方法时,这点非常注意。
4.将字符串中的某个字符进行替换:replace(char oldChar, char newChar)
参数就是被替换的字符和新的字符,源码如下:
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
// 1.遍历字符数组,找到原子符的位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
//2. 声明一个临时的字符数组,用来存储替换后的字符串,
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
// 3. 将原字符数组拷贝到新的字符数组中去
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
// 4.
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
// 3. 初始化一个新的字符串
return new String(buf, true);
}
}
return this;
}
具体的执行逻辑就是注释的语句。
用法示例:
String strIndex = "chee";
String afterReplace = strIndex.replace('e','n');
System.out.println(afterReplace);
输出:
chnn
注意:这里的替换是字符串中的所有与旧字符的相同的字符,比如上面的这个例子,就是将原子符中的e全部替换为n。
5.字符串的分隔:split(String regex) :
源码如下:
public String[] split(String regex) {
return split(regex, 0);
}
public String[] split(String regex, int limit) {
/* fastpath if the regex is a
(1)one-char String and this character is not one of the
RegEx's meta characters ".$|()[{^?*+\", or
(2)two-char String and the first char is the backslash and
the second is not the ascii digit or ascii letter.
*/
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0;
ArrayList<String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
list.add(substring(off, value.length));
off = value.length;
break;
}
}
// If no match was found, return this
if (off == 0)
return new String[]{this};
// Add remaining segment
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// Construct result
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
}
用法示例:
// 将一句话使用空格进行分隔
String sentence = "People who hear thumb up can get rich";
// 使用空格进行分隔
String[] subSequence = sentence.split("\s");
for (String s : subSequence) {
System.out.println(s);
}
输出:
People
who
hear
thumb
up
can
get
rich
注意: 使用这个方法,对正则表达式有所了解,才能实现更强大的功能,正则表达式的学习,可以移步菜鸟教程
6.实现字符串的指定范围的切割substring(int beginIndex, int endIndex):
源码如下:
public String substring(int beginIndex, int endIndex) {
// 1.判断异常
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
// 2,确定切割的长度
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
// 3.使用构造方法,返回切割后字符串
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
具体的执行逻辑如注释所示,这个方法的逻辑总体比较简单:
具体用法:
String sentence = "hhchennn";
String subSequence = sentence.substring(2,6);
System.out.println(subSequence);
输出:
chen
注意: 从源码了解到,这个方法的在切割的时候,一般将第一个参数包含,包含第二个参数,也就是说上面的例子中在切割后的字符串中包含2这个字符,但是不包含6这个字符。
7.当然处理这些还有一些常用的方法,比如:
// 1.去除字符串前后空格的方法
trim()
//2.大小写转换的方法
toLowerCase()
toUpperCase()
//3. 将字符串转化为数组
toCharArray()
// 4.将基本类型转化字符串
valueOf(boolean b)
// 5.返回对象本身的字符串形式
toString()
这些方法使用起来都比较简单,强烈建议看看java官方文档。
3.面试常问
3.1. 为什么是不可变的
1、什么是不可变?
从 java角度来讲就是说成final的。参考Effective Java 中第 15 条 使可变性最小化 中对 不可变类 的解释:
不可变类只是其实例不能被修改的类。每个实例中包含的所有信息都必须在创建该实例的时候就提供,并且在对象的整个生命周期内固定不变。为了使类不可变,要遵循下面五条规则:
1. 不要提供任何会修改对象状态的方法。
2. 保证类不会被扩展。 一般的做法是让这个类称为 `final` 的,防止子类化,破坏该类的不可变行为。
3. 使所有的域都是 final 的。
4. 使所有的域都成为私有的。 防止客户端获得访问被域引用的可变对象的权限,并防止客户端直接修改这些对象。
5. 确保对于任何可变性组件的互斥访问。 如果类具有指向可变对象的域,则必须确保该类的客户端无法获得指向这些对象的引用。
当然在 Java 平台类库中,包含许多不可变类,例如 String , 基本类型的包装类,BigInteger, BigDecimal 等等。综上所述,不可变类具有一些显著的通用特征:类本身是 final 修饰的;所有的域几乎都是私有 final 的;不会对外暴露可以修改对象属性的方法。通过查阅 String 的源码,可以清晰的看到这些特征。
2.为什么不可变
String real = "chen"
real = "Wei";
下图就很好解释了代码的执行过程:
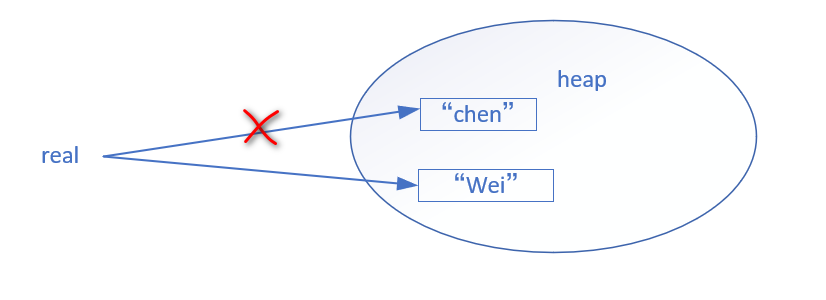
执行第一行代码时,在堆上新建一个对象实例 chen , real是一个指向该实例的引用,引用包含的仅仅只是实例在堆上的内存地址而已。执行第二行代码时,仅仅只是改变了 real 这个引用的地址,指向了另一个实例 wei。所以,正如前面所说过的,不可变类只是其实例不能被修改的类。 给 real 重新赋值仅仅只是改变了它的引用而已,并不会真正去改变它本来的内存地址上的值。这样的好处也是显而易见的,最简单的当存在多个 String 的引用指向同一个内存地址时,改变其中一个引用的值并不会对其他引用的值造成影响。
那么,String 是如何保持不可变性的呢?结合 Effective Java 中总结的五条原则,阅读它的 源码 之后就一清二楚了。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
String 类是 final 修饰的,满足第二条原则:保证类不会被扩展。 分析一下它的几个域:
private final char value[] :可以看到 Java 还是使用字节数组来实现字符串的,并且用final修饰,保证其不可变性。这就是为什么 String 实例不可变的原因。private int hash :String的哈希值缓存private static final long serialVersionUID = -6849794470754667710L :String对象的serialVersionUIDprivate static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0] :序列化时使用
其中最主要的域就是 value,代表了 String对象的值。由于使用了 private final 修饰,正常情况下外界没有办法去修改它的值的。正如第三条 使所有的域都是 final 的。 和第四条 使所有的域都成为私有的 所描述的。难道这样一个 private 加上 final 就可以保证万无一失了吗?看下面代码示例:
final char[] value = {'a', 'b', 'c'};
value[2] = 'd';
这时候的 value 对象在内存中已经是 a b d 了。其实 final 修饰的仅仅只是 value 这个引用,你无法再将 value 指向其他内存地址,例如下面这段代码就是无法通过编译的:
final char[] value = {'a', 'b', 'c'};
value = {'a', 'b', 'c', 'd'};
所以仅仅通过一个 final 是无法保证其值不变的,如果类本身提供方法修改实例值,那就没有办法保证不变性了。Effective Java 中的第一条原则 不要提供任何会修改对象状态的方法 。String 类也很好的做到了这一点。在 String 中有许多对字符串进行操作的函数,例如 substring concat replace replaceAll 等等,这些函数是否会修改类中的 value 域呢?我们看一下 concat() 函数的内部实现:
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
注意其中的每一步实现都不会对 value产生任何影响。首先使用 Arrays.copyOf() 方法来获得 value 的拷贝,最后重新 new 一个String对象作为返回值。其他的方法和 contact 一样,都采取类似的方法来保证不会对 value 造成变化。的的确确,String 类中并没有提供任何可以改变其值的方法。相比 final 而言,这更能保障 String 不可变。
3.不可变类的好处:
Effective Java 中总结了不可变类的特点。
- 不可变类比较简单。
- 不可变对象本质上是线程安全的,它们不要求同步。不可变对象可以被自由地共享。
- 不仅可以共享不可变对象,甚至可以共享它们的内部信息。
- 不可变对象为其他对象提供了大量的构建。
- 不可变类真正唯一的缺点是,对于每个不同的值都需要一个单独的对象。
3.2. 使用什么方式可以改变String类的不可变性
当然使用反射,java的反射机制可以做到我们平常做不到的很多事情:
String str = "chen";
System.out.println(str);
Field field = String.class.getDeclaredField("value");
field.setAccessible(true);
char[] value = (char[]) field.get(str);
value[1] = 'a';
System.out.println(str);
执行结果:
chen
caen
3.3. String和stringBuffer和StringBuilder的区别
从以下三个方面来考虑他们之间的异同点:
1.可变和不可变性:
String: 字符串常量,在修改时,不会改变自身的值,若修改,就会重新生成新的字符串对象。
StringBuffer: 在修改时会改变对象本身,不会生成新的对象,使用场景:对字符经常改变的情况下,主要方法: append(),insert() 等。
2.线程是否安全
String: 定义之后不可改变,线程安全
String Buffer: 是线程安全的,但是执行效率比较低,适用于多线程下操作字符串缓冲区的大量数据。
StringBuilder: 线程不安全的,适用于单线程下操作字符串缓冲区的大量数据
3.共同点
StringBuilder和StringBuffer有共有的父类 AbstractStringBuilder(抽象类)。
StringBuilder,StringBuffer的方法都会调用AbstractStringBuilder中的公共方法,如: super().append()...
只是StringBuffer会在方法上加上synchronized关键字,进行同步。
4.优秀的工具包推荐
4.1guava
Guava工程包含了若干被Google的 Java项目广泛依赖 的核心库,例如:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string processing] 、I/O 等等。 所有这些工具每天都在被Google的工程师应用在产品服务中。具体的中文参考文档,Guava中文参考文档。
4.2 Hutool
Hutool是一个Java工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让Java语言也可以“甜甜的”。Hutool最初是我项目中“util”包的一个整理,后来慢慢积累并加入更多非业务相关功能,并广泛学习其它开源项目精髓,经过自己整理修改,最终形成丰富的开源工具集。Hutool参考文档
追本溯源,方能阔步前行
参考资料:
参考博客:
https://juejin.im/post/59cef72b518825276f49fe40
https://www.cnblogs.com/ChrisMurphy/p/4760197.html
参考书籍: java官方文档 《深入理解JVM虚拟机》