冒泡排序
所谓冒泡,就是将元素两两之间进行比较,谁大就往后移动,直到将最大的元素排到最后面,接着再循环一趟,从头开始进行两两比较,而上一趟已经排好的那个元素就不用进行比较了。(图中排好序的元素标记为黄色柱子)
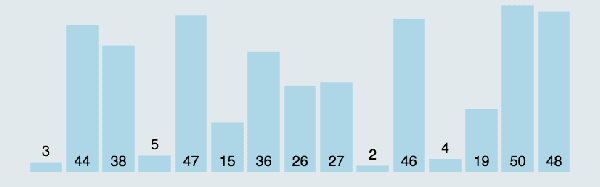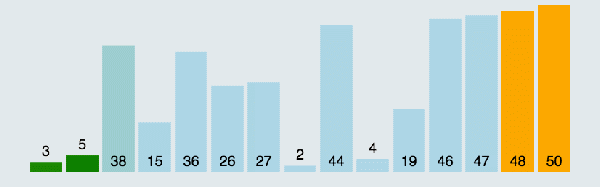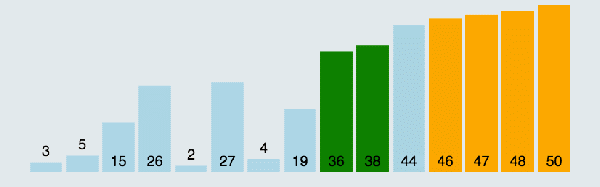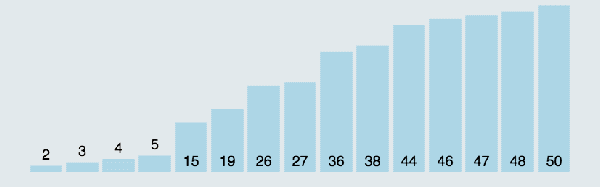
冒泡排序动图演示
上python代码:
1 def bubble_sort(items): 2 for i in range(len(items) - 1): 3 for j in range(len(items) - 1 - i): 4 if items[j] > items[j + 1]: 5 items[j], items[j + 1] = items[j + 1], items[j] 6 return items 7 8 9 list1 = [2,1,9,11,10,8,7] 10 print(bubble_sort(list1))
输出结果:
1 [1, 2, 7, 8, 9, 10, 11]
这是冒泡排序最普通的写法,但你会发现它有一些不足之处,比如列表:[1,2,3,4,7,5,6],第一次循环将最大的数排到最后,此时列表已经都排好序了,就是不用再进行第二次、第三次...
冒泡排序优化一:
设定一个变量为False,如果元素之间交换了位置,将变量重新赋值为True,最后再判断,在一次循环结束后,变量如果还是为False,则brak退出循环,结束排序。
1 def bubble_sort(items): 2 for i in range(len(items) - 1): 3 flag = False 4 for j in range(len(items) - 1 - i): 5 if items[j] > items[j + 1]: 6 items[j], items[j + 1] = items[j + 1], items[j] 7 flag = True 8 if not flag: 9 break 10 return items
冒泡排序优化二:搅拌排序 / 鸡尾酒排序
上面这种写法还有一个问题,就是每次都是从左边到右边进行比较,这样效率不高,你要考虑当最大值和最小值分别在两端的情况。写成双向排序提高效率,即当一次从左向右的排序比较结束后,立马从右向左来一次排序比较。
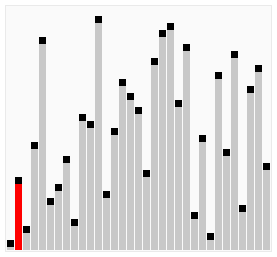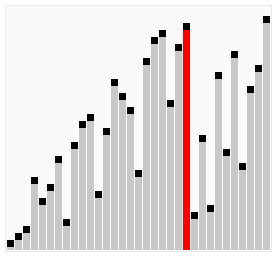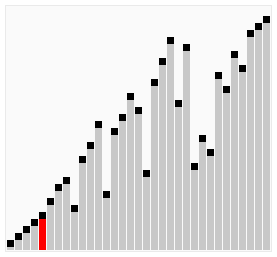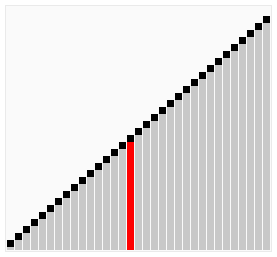
双向排序动图演示
python代码:
1 def bubble_sort(items): 2 for i in range(len(items) - 1): 3 flag = False 4 for j in range(len(items) - 1 - i): 5 if items[j] > items[j + 1]: 6 items[j], items[j + 1] = items[j + 1], items[j] 7 flag = True 8 if flag: 9 flag = False 10 for j in range(len(items) - 2 - i, 0, -1): 11 if items[j - 1] > items[j]: 12 items[j], items[j - 1] = items[j - 1], items[j] 13 flag = True 14 if not flag: 15 break 16 return items
冒泡排序优化三:
最后要考虑的情况就是,如果给你的不是列表,而是对象,或者列表里面都是字符串,那么上述的代码也就没有用了,这时候你就要自定义函数了,并将其当成参数传入bubble_sort函数
python代码:
def bubble_sort(items, comp=lambda x, y: x > y): for i in range(len(items) - 1): flag = False for j in range(len(items) - 1 - i): if comp(items[j],items[j + 1]): items[j], items[j + 1] = items[j + 1], items[j] flag = True if flag: flag = False for j in range(len(items) - 2 - i, 0, -1): if comp(items[j - 1],items[j]): items[j], items[j - 1] = items[j - 1], items[j] flag = True if not flag: break return items list2 = ['apple', 'watermelon', 'pitaya', 'waxberry', 'pear'] print(bubble_sort(list2,lambda s1,s2: len(s1) > len(s2))) #按照字符串长度从小到大来排序
输出结果:
1 ['pear', 'apple', 'pitaya', 'waxberry', 'watermelon']
类似的,当有人叫你给一个类对象排序时,也可以传入lambda 自定义函数。
1 class Student(): 2 """学生""" 3 4 def __init__(self, name, age): 5 self.name = name 6 self.age = age 7 8 def __repr__(self): 9 return f'{self.name}: {self.age}' 10 11 items1 = [ 12 Student('Wang Dachui', 25), 13 Student('Di ren jie', 38), 14 Student('Zhang Sanfeng', 120), 15 Student('Bai yuanfang', 18) 16 ] 17 18 print(bubble_sort(items1, lambda s1, s2: s1.age > s2.age))
输出结果:按照年龄从小到大排序
1 [Bai yuanfang: 18, Wang Dachui: 25, Di ren jie: 38, Zhang Sanfeng: 120]
以上就是关于冒泡排序的原理,以及一些优化写法,希望会对你有所帮助。