- 一、背景和问题
- 二、Redis6 的解决方案及原理
- 2.1 服务端支持客户端缓存的两种模式
- 1. 默认模式
- 2. 广播模式
- 2.2 客户端实现的两种连接模式
- 1. 使用同一连接
- 2. 使用不同连接
- 3. 结论
- 4. 举个栗子
- 2.3 策略补充
- 1. Opt-in caching
- 2. The NOLOOP option
- 3. race conditions
- 4. 连接断开
- 5. 应该缓存什么数据?
- 6. 限制客户端redis缓存的内存大小
- 7. 客户端实现的其它提示
- 2.1 服务端支持客户端缓存的两种模式
- 三、客户端实现
- 三、参考文档
一、背景和问题
Redis 这种缓存从某种意义上还是一种远程的缓存,每次缓存读取会增加一次 TCP RTT,数据的序列化和反序列化也需要资源。如果对效率有更高的要求,就要考虑进程内缓存了。Redis 6.x以上开始支持客户端缓存,此客户端缓存是服务端辅助的客户端缓存,在应用服务内部再加一层缓存,也就是内存缓存,从而进一步提升访问速度。

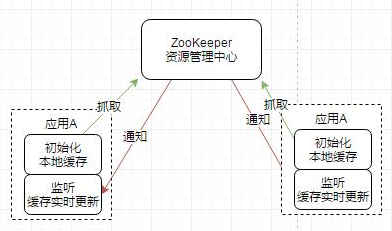
为了解决本地缓存数据的实时性问题,目前大量使用的是结合ZooKeeper的自动发现机制,实时变更本地静态变量缓存,例如美团的MtConfig,使用静态变量缓存,结合ZooKeeper的统一管理,做到自动动态更新缓存:
正如Redis 之父antirez 所说,redis 接下来的一个重点是配合客户端,因为客户端缓存显而易见的可以减轻 redis 的压力,速度也快很多。大公司或多或少都有实现这种应用端缓存的机制,antirez 想通过 server 端的一些设计来减少客户端缓存实现的复杂度和成本,甚至不惜在 redis 协议上做修改。
进程内缓存面临2个主要的问题是
-
保证数据的一致性,包括各个进程缓存的数据要是一致的,进程缓存和 Redis 缓存要是一致的;尽可能减小网络压力;
-
尽可能减小网络压力;
二、redis6 的解决方案及原理
Redis在服务端记录访问的连接和相关的key, 当key有变化时,通知相应的连接(应用)。应用收到请求后自行处理有变化的key, 进而实现client cache与redis的一致。
Redis对客户端缓存的支持方式被称为Tracking,分为两种模式:默认模式,广播模式。
2.1 服务端支持客户端缓存的两种模式
1. 默认模式
Server 端记录每个Client访问的Key(只读的key),当发生变更时,向client推送数据过期消息。
开启命令:client tracking on 优点:只对Client发送其访问过的被修改的数据 缺点:Server端需要额外存储较大的数据量
举个栗子:
原理:
默认模式通过在服务端存储访问的key值,来记录客户端缓存的key,并以此来实现key值变更时,向客户端发送通知消息,以此来更新客户端缓存。但是,此种方案在客户端连接且每个客户端的key值较多时,会占用较多的内存空间和处理这些数据的CPU花费,鉴于此,进行了如下关键设计:
定义一个全局表Invalidation Table,记录客户端请求的所有 key(但也只是使用了只读命令的 key,这是服务器和客户端之间的协议),存储的是客户端缓存的相应key的hash值和客户端ID的对应关系,实现的方式是保持一个很大的指针数组,每一个指针指向一个 Linked List,代表缓存了一个 Slot 的客户端列表。如下所示:
每一个 client 都有一个 unique ID(可以通过CLIENT ID命令查询),第四行就表示,client 9,1,2 读取了 slot4 中的数据。client假设 slot4 中的 key 更新了,那么 Server 将会把 Slot 更新的信息发送给这三个客户端。这样就解决了无意义的消息推送问题。
这个指针数据有多大呢?首先这里的 slots 数量比 Ben 的方法多很多,这里使用的是 CRC64 的 24bit 输出,那就是 2^24 个 slots。指针是 64bit 指针,即 64bit ** 2^^24 = ~130Megabyte。Antirez 认为服务端这些内容是是值的,这解决了很多 key 共享 slots 的问题,就算有千万级别的 key,也只有两三个 key 共享 slots,散列度很高。
需要注意的是客户端不必全部使用 24 位的哈希函数。他们也可能只使用 20 位的,然后只用移动 Redis 发送给他们的失效消息槽,对于内存紧张的系统可以这样做。
2. 广播模式
客户端订阅key前缀的广播(空串表示订阅所有失效广播),服务端记录key前缀与client的对应关系。当相匹配的key发生变化时,通知client。
开启命令:client tracking on [REDIRECT CLIENT ID] BCAST [PREFIX] (例如:CLIENT TRACKING on REDIRECT 10 BCAST PREFIX object: PREFIX user:) 优点:服务端记录信息比较少 缺点:client会收到自己未访问过的key的失效通知
原理:
类似于默认模式的Invalidation Table,广播模式也维护了一个全局表: Prefixes Table,其中存储的是只读key的前缀和客户端的映射关系。一旦一个key能够匹配上 Prefixes Table的前缀,就会向所有订阅了此前缀的客户端发送过期消息。
但此种方式会代理一些问题:服务器将消耗与注册前缀数量成正比的CPU。 如果只有几个,几乎看不到任何区别。 使用大量前缀,CPU成本可能变得非常高。
2.2 客户端实现的两种连接模式
客户端通过接收服务端的失效消息,进行更新客户端缓存,从而保证数据的一致性。对于接收server端失效消息和正常的查询消息是否使用同一连接存在两种模式。
1. 使用同一连接
此种模式需要Redis RESP3协议,而此协议从redis6才开始支持。使用Redis 6支持的新版Redis协议RESP3,可以在同一个连接中运行数据的查询和接收失效消息。
RESP3协议:
redis6.0开始使用新的协议RESP3。该协议增加了很多数据类型。新协议目的之一是支持客户端缓存,与客户端缓存相关的部分如下:
-
hello命令: client告知服务端使用的协议版本,服务端返回一些简要的版本。发送hello 2, 表示使用RESP2, hello 3表明使用RESP3协议。默认开始的是RESP2。
-
client tracking on/off: 开启/关闭tracking
-
push数据:带外数据,它是redis主动推送的数据。向client推送的数据过期消息即是通过此协议实现的(使用RESP2客户端无法接收push数据)。
2. 使用不同连接
使用不同连接:一个用于数据,另一个用于失效消息。redis通过redirect支持这一功能。当一个客户端开启tracking(即开启接收失效消息)后,它可以通过设置另一连接的“client id ”将失效的消息重定向(redirect)到另一个连接。多个数据连接可以将失效消息重定向到同一连接。
何为redirect?
使用Redis 6支持的新版Redis协议RESP3,可以在同一个连接中运行数据的查询和接收失效消息。不过,许多客户端实现可能倾向于使用两个单独的连接来实现客户端缓存:一个用于数据,另一个用于失效消息。redis通过redirect支持这一功能。 当一个客户端开启tracking后,它可以通过设置另一连接的“client id ”将失效的消息重定向(redirect)到另一个连接。多个数据连接可以将失效消息重定向到同一连接,这对于实现了连接池的客户端会很有用。
所以,
RESP2的客户端只能通过不同连接来实现客户端缓存机制。只是在重定向开启的时候才起作用,监听消息的客户端进入 Pub/Sub 模式,才会发送 Pub/Sub 消息。这样旧客户端也可以使用该特性了。
2.3 策略补充
1. Opt-in caching
客户端可以指定是否缓存查询的key, 以此减少服务端的内存使用和两者之间的带宽,开启此方式的命令如下:
当想去缓存某一key的时候,需要在查询此key命令之前发送以下命令:
CACHING命令会影响紧随其后执行的命令,但是如果下一个命令是MULTI,则将跟踪事务中的所有命令。 同样,对于Lua脚本,将跟踪该脚本执行的所有命令。
2. The NOLOOP option
默认情况下,客户端Tracking会发送无效消息到修改此key的客户端,对于实现基本功能的客户端,不涉及在本地自动缓存写操作。 但是,更高级的客户端甚至可能希望将其正在执行的写入缓存在本地内存表中。 在这种情况下,在写操作之后立即接收到无效消息是一个问题,因为这将迫使客户端清空其刚刚缓存的值。鉴于此种场景,可以使用NOLOOP option:支持默认和广播模式,使用此命令,将告诉服务端它不想接收来自自己更新key产生的的无效消息通知。
3. race conditions
实现客户端缓存时存在一种竞态条件,例子如下所示:
[
其中:D和I都是客户端连接(D:接收数据连接,I:接收无效信息的连接)
以上按照时间顺序显示的调用结果,可知,GET请求的回复数据慢于接收到的无效信息,此时会造成一种结果:我们保存在客户端缓存中的foo bar是过期数据。为了避免此种情况的发生,可以执行如下解决方案:
Client cache: set the local copy of "foo" to "caching-in-progress"
[D] client-> server: GET foo.
[I] server -> client: Invalidate foo (somebody else touched it)
Client cache: delete "foo" from the local cache.
[D] server -> client: "bar" (the reply of "GET foo")
Client cache: don't set "bar" since the entry for "foo" is missing.
不难看出,此种竞态条件在请求数据和无效信息使用同一连接的时候将不可能发生(因为有序了)。
4. 连接断开
当客户端获取失效信息的socket连接断开,我们通常会以过期数据处理缓存。为了避免此种场景,可以从以下几个方面优化:
-
确保如果连接丢失,则刷新本地缓存。
-
对于使用 Pub/Sub的RESP2或者 RESP3,定期ping失效通道,如果连接看起来断开了,我们无法收到ping回复,则在经过最长时间后,请关闭连接并刷新缓存。
5. 应该缓存什么数据?
客户端可能希望进行内部统计缓存key实际在请求中的调用次数,以期望更好的使用缓存。 一般来说: 我们不想缓存许多不断变化的key。 我们不想缓存很少被请求的key。 我们希望缓存经常需要的key,并以合理的周期进行更改。 有关key没有以合理的周期更改的示例:一个连续递增的全局计数器。 但是,更简单的客户端可能只是使用一些随机采样来驱逐数据,只是记住给定key的最后一次更改时间,从而试图驱逐最近未使用的key。
6. 限制客户端redis缓存的内存大小
只需确保为Redis记住的最大键数配置一个合适的值,或者使用BCAST模式,该模式在Redis端根本不占用任何内存。 请注意,当不使用BCAST时,Redis消耗的内存与跟踪的key数以及请求此key的客户端数成正比。
7. 客户端实现的其它提示
处理TTL:如果要支持带TTL的缓存key,请确保还请求key TTL并在本地缓存中设置TTL。 即使没有TTL,在每个键中都放置一个最大TTL是个好的idea。 这是很好的保护措施,可避免可能导致客户端在本地副本中包含旧数据的错误或连接问题。 绝对需要限制客户端使用的内存量。 添加新key时,必须有一种方法可以将旧key删除。
三、客户端实现
以java为例,目前支持此功能的客户端实现如Lettuce6.0, 其作者给出的用例如下所示:


1 // the client-side cache 2 Map<String, String> clientCache = new ConcurrentHashMap<>(); 3 4 // prepare our connection and another party 5 StatefulRedisConnection<String, String> otherParty = redisClient.connect(); 6 RedisCommands<String, String> commands = otherParty.sync(); 7 8 StatefulRedisConnection<String, String> connection = redisClient.connect(); 9 10 // Create cache-frontend through which we're going to access the cache 11 CacheFrontend<String, String> frontend = ClientSideCaching.enable(CacheAccessor.forMap(clientCache), connection, TrackingArgs.Builder.enabled()); 12 13 // make sure value exists in Redis 14 // client-side cache is empty 15 commands.set(key, value); 16 17 // Read-through into Redis 18 String cachedValue = frontend.get(key); 19 assertThat(cachedValue).isNotNull(); 20 21 // client-side cache holds the same value 22 assertThat(clientCache).hasSize(1); 23 24 // now, the key expires 25 commands.pexpire(key, 1); 26 27 // a while later 28 Thread.sleep(200); 29 30 // the expiration reflects in the client-side cache 31 assertThat(clientCache).isEmpty();