import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
*
*/
object LocalNetworkWordCount {
def main(args: Array[String]) {
// StreamingContext 编程入口
//local[2] 启用两个core, 一个线程用于接收数据,一个线程用于处理数据
//Seconds(1) 每隔一秒钟处理一次
val ssc = new StreamingContext("local[2]", "LocalNetworkWordCount", Seconds(1),
System.getenv("SPARK_HOME"), StreamingContext.jarOfClass(this.getClass).toSeq)
//数据接收器(Receiver)
//创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines = ssc.socketTextStream("localhost", 9998, StorageLevel.MEMORY_AND_DISK_SER)
//数据处理(Process)
//处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordPairs = words.map(x => (x, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
//结果输出(Output)
//将结果输出到控制台
wordCounts.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
// 7 X 24 小时运行,一直等待不会停止
//注释该行代码后,运行一次便终止(必须打开)
ssc.awaitTermination()
}
}
NetworkWordCount
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
spark-submit --class com.twq.streaming.NetworkWordCount
--master spark://master:7077
--deploy-mode client
--driver-memory 512m
--executor-memory 512m
--total-executor-cores 4
--executor-cores 2
/home/hadoop-twq/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
*/
object NetworkWordCount {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// StreamingContext 编程入口
val ssc = new StreamingContext(sc, Seconds(1))
//数据接收器(Receiver)
//创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
// StorageLevel.MEMORY_AND_DISK_SER_2 通过该方式存储在内存中 先放入内存中,内存不够放在磁盘中,以字节的方式储存,储存两份
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER_2)
//数据处理(Process)
//处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordPairs = words.map(x => (x, 1))
val wordCounts = wordPairs.reduceByKey(_ + _)
//结果输出(Output)
//将结果输出到控制台
wordCounts.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
}
}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
spark-submit --class com.twq.streaming.NetworkWordCountDetail
--master spark://master:7077
--deploy-mode client
--driver-memory 512m
--executor-memory 512m
--total-executor-cores 4
--executor-cores 2
/home/hadoop-twq/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
*/
object NetworkWordCountDetail {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
//1、StreamingContext 是 Spark Streaming程序的入口,那么StreamingContext和SparkContext的关系是什么呢?
//1.1、StreamingContext需要持有一个SparkContext的引用
val ssc = new StreamingContext(sc, Seconds(1))
//1.2、如果SparkContext没有启动的话,我们可以用下面的代码启动一个StreamingContext
val ssc2 = new StreamingContext(sparkConf, Seconds(1)) //这行代码会在内部启动一个SparkContext
ssc.sparkContext //可以从StreamingContext中获取到SparkContext
//1.3、对StreamingContext调用stop的话,可能会将SparkContext stop掉,
// 如果不想stop掉SparkContext,我们可以调用
ssc.stop(false)
sc.stop()
//2:StreamingContext的注意事项:
// 2.1、在同一个时间内,同一个JVM中StreamingContext只能有一个
// 2.2、如果一个StreamingContext启动起来了,
// 那么我们就不能为这个StreamingContext添加任何的新的Streaming计算
// 2.3、如果一个StreamingContext被stop了,那么它不能再次被start
// 2.4、一个SparkContext可以启动多个StreamingContext,
// 前提是前面的StreamingContext被stop掉了,而SparkContext没有被stop掉
//创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
//处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
//将结果输出到控制台
wordCounts.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
}
}
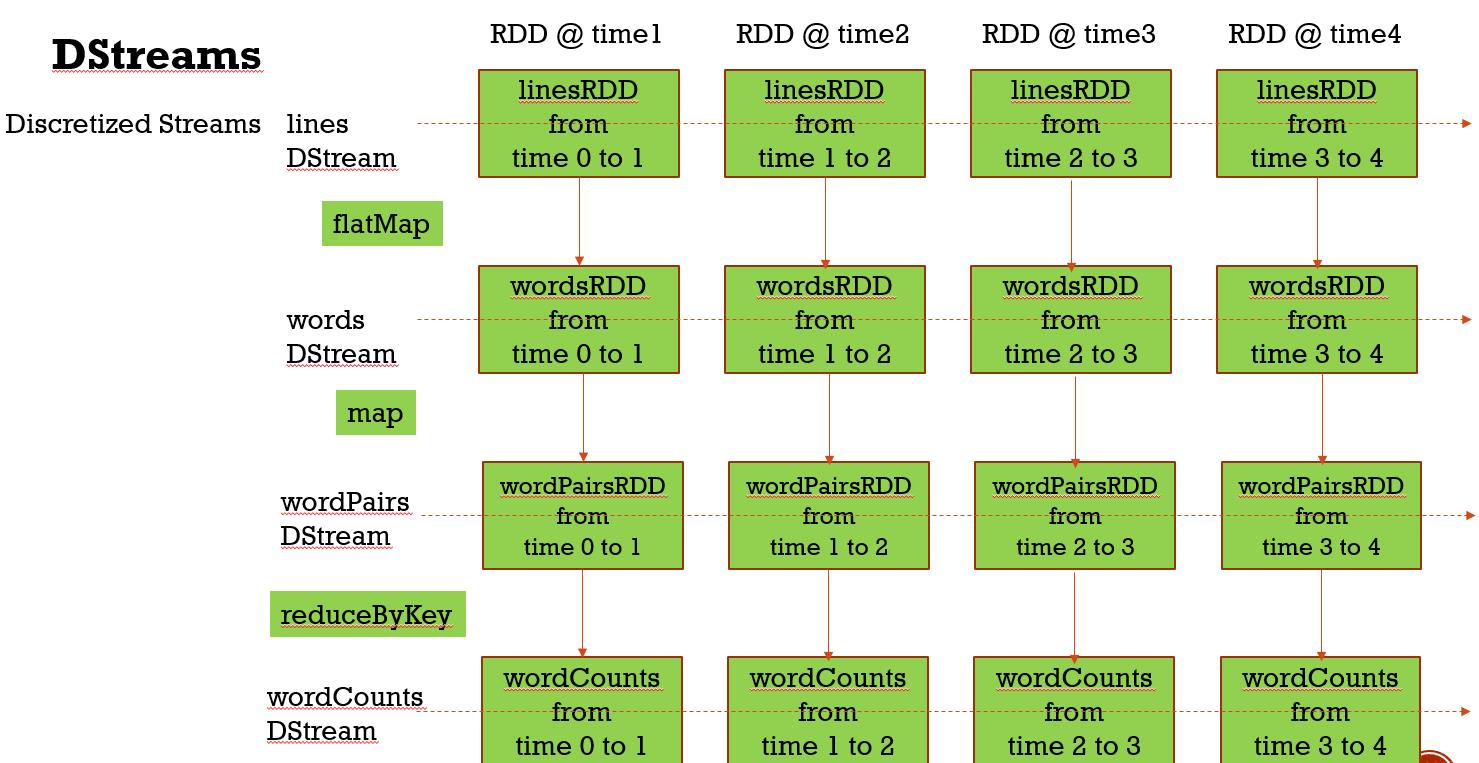
☛ DStream(Discretized Stream 离散化流)特点
一个依赖父DStream的列表(依赖利于容错)
一个生成RDD的时间间隔(Batch Interavl)
一个生成RDD的函数(DStream 到 RDD 的转换)
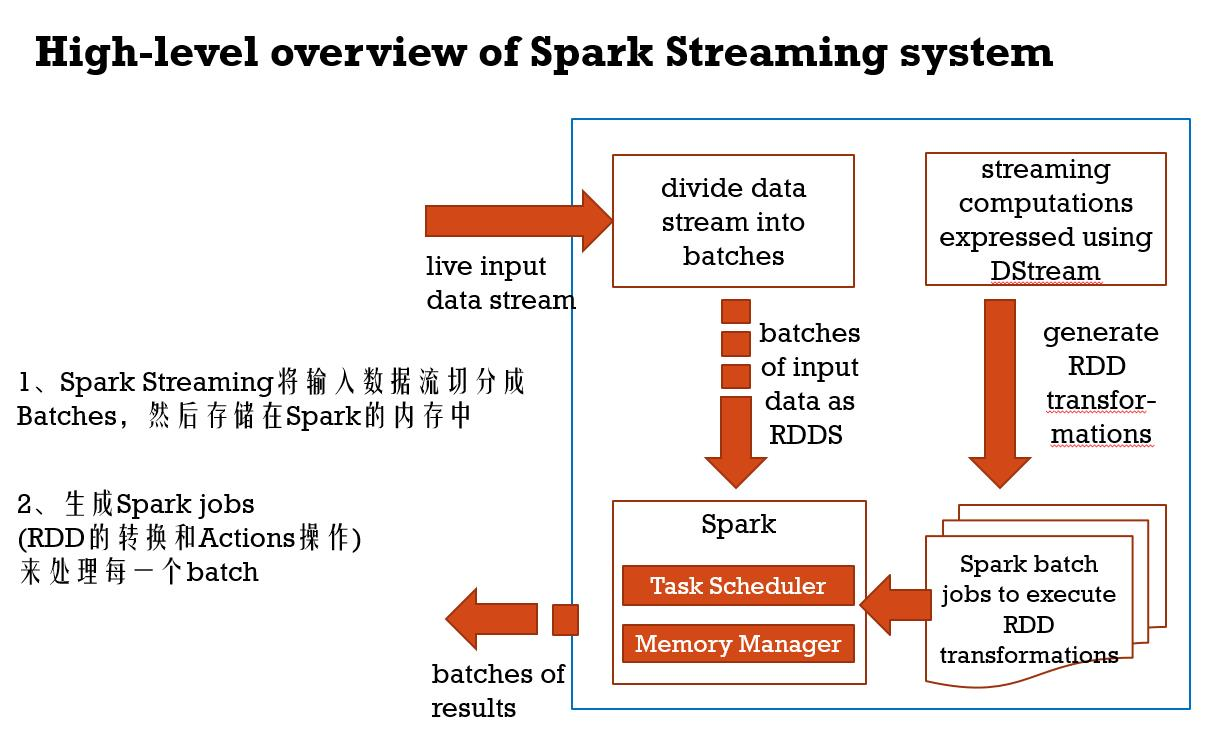
1、Spark Streaming将输入数据流切分成Batches,然后存储在Spark的内存中
2、生成Spark jobs(RDD的转换和Actions操作)来处理每一个batch