目录
【加群获取学习资料QQ群:901381280】
我设计的语音智能管家是部署在树莓派上的,所以现在先列一下大概的硬件:
- 树莓派4b+ x1
- 麦克风
- usb声卡
- u任意一个支持树莓派的音频输出设备(3.5mm孔的 或者一些蓝牙设备)
usb声卡

树莓派4b+


备注:树莓派上面那个是摄像头(后面视频监控和人脸识别会用到,所以就安上了)
ok,进入正题,开始干货
一.语音唤醒引擎(snowboy)
这里我选择使用开源的snowboy开源引擎(好处:免费,还可以自定义唤醒词:比如我自定义的唤醒词是:小贝)
snowboy 是一个开源的、轻量级语音唤醒引擎,可以通过它很轻松地创建属于自己的类似“hey, Siri” 的唤醒词。它的主要特性如下:
- 高度可定制性。可自由创建和训练属于自己的唤醒词
- 始终倾听。可离线使用,无需联网,保护隐私。精确度高,低延迟
- 轻量可嵌入。耗费资源非常低(单核 700MHz 树莓派只占用 10% CPU)
- 开源跨平台。开放源代码,支持多种操作系统和硬件平台,可绑定多种编程语言
接下来开始如何使用snowboy以及怎么部署到树莓派。
1.获取源代码并编译
安装依赖
树莓派原生的音频设备是不支持语音输入的(无法录音),需要在网上购买一支免驱动的USB音频驱动(便携式的和 U 盘差不多),一般插上即可直接使用。
建议安装下 pulseaudio 软件,减少音频配置的步骤:
$ sudo apt-get install pulseaudio安装 sox 软件测试录音与播放功能:
$ sudo apt-get install sox安装完成后运行 sox -d -d 命令,对着麦克风说话,确认可以听到自己的声音。
安装其他软件依赖:
安装 PyAudio:$ sudo apt-get install python3-pyaudio
安装 SWIG(>3.0.10):$ sudo apt-get install swig
安装 ATLAS:$ sudo apt-get install libatlas-base-dev编译源代码
获取源代码:
$ git clone https://github.com/Kitt-AI/snowboy.gitPS:官方源代码使用 Python3 测试有报错,经测试需修改
snowboy/examples/Python3目录下的 snowboydecoder.py 文件。
将第 5 行代码 from * import snowboydetect 改为 import snowboydetect 即可直接运行。
备注:网上很多教程是make之后再修改,这种情况是不成功的,因为make后会生成配置文件,你这时候改了不起效果,因此先修改,在执行下一步的make。
编译 Python3 绑定:
$ cd snowboy/swig/Python3 && make测试:
进入官方示例目录 snowboy/examples/Python3 并运行以下命令:
$ python3 demo.py resources/models/snowboy.umdl
( 命令中的 snowboy.umdl 文件即语音识别模型)
然后对着麦克风清晰地讲出“snowboy”,如果可以听到“滴”的声音,则安装配置成功。命令行输出如下:

2.自定义自己的唤醒词(唤醒词:小贝)
可将包含自定义唤醒词的音频文件上传至 snowboy 官网:https://snowboy.kitt.ai/dashboard(需要登录),以训练生成自己喜欢的语音模型。
需要上传的音频文件数量为 3 个,wav 格式。我试过直接在线录制,貌似有 Bug ,这里建议大家录制好wav音频上传(录唤醒词)
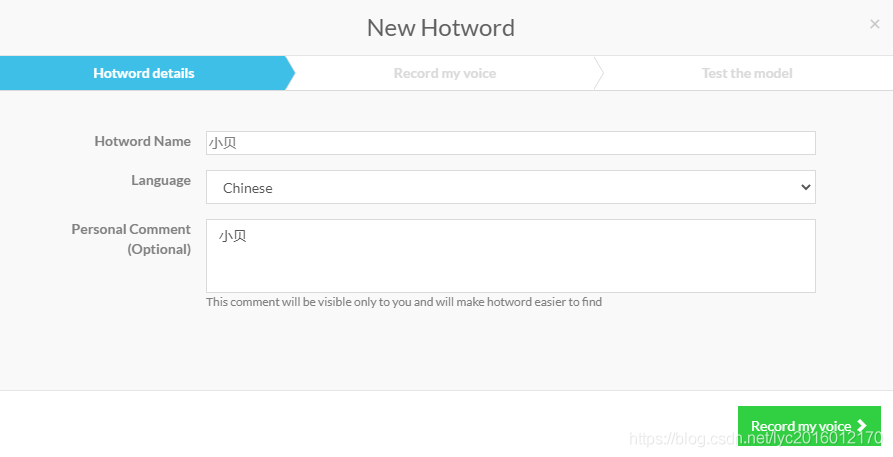

训练完成并测试通过后,即可下载 PMDL 后缀的模型文件了。
3.测试
将以下文件复制到自己的项目目录下(snowboy/examples/Python3 目录下的 demo.py、snowboydecoder.py、snowboydetect.py 文件以及 resources 目录):
- 在项目目录下执行
-
$ python3 demo.py 小贝.pmdl - 并使用自己的唤醒词进行测试
二、自定义响应
官方提供的示例 demo.py 文件的源代码如下:
import snowboydecoder
import sys
import signal
interrupted = False
def signal_handler(signal, frame):
global interrupted
interrupted = True
def interrupt_callback():
global interrupted
return interrupted
if len(sys.argv) == 1:
print("Error: need to specify model name")
print("Usage: python demo.py your.model")
sys.exit(-1)
model = sys.argv[1]
# capture SIGINT signal, e.g., Ctrl+C
signal.signal(signal.SIGINT, signal_handler)
detector = snowboydecoder.HotwordDetector(model, sensitivity=0.5)
print('Listening... Press Ctrl+C to exit')
# main loop
detector.start(detected_callback=snowboydecoder.play_audio_file,
interrupt_check=interrupt_callback,
sleep_time=0.03)
detector.terminate()通过唤醒词可以听到ding的一声,但是我想通过唤醒词唤醒后,能够进行回应。因此我自定义了回应操作,比如回应:哎,我在或者我来啦
在回调函数这里,我自定义了回调函数callbacks:
# 修改回调函数可实现我们想要的功能
detector.start(detected_callback=callbacks, # 自定义回调函数
interrupt_check=interrupt_callback,
sleep_time=0.03)callbacks:
# 回调函数,语音识别在这里实现,修改也是在这里
def callbacks():
global detector
time.sleep(0.2)
your_text=['哎,我在','我来啦']
a=random.randint(0,1)
############################
#文字转语音,并保存result.wav
towav(your_text[a])
print(your_text[a])
#欢迎词
play("result.wav")为了是通过语音来回复,所以这里我接入了百度AI的语音合成,通过文字转语音的功能,将欢迎词:哎,我在或者我来啦转为音频再播放出来。
下面是语音合成的代码:
# coding=utf-8
import sys
import json
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
API_KEY = '自己的API_KEY'
SECRET_KEY = '自己的SECRET_KEY '
TEXT = "你好,我在"
# 发音人选择, 基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫,
# 精品音库:5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
PER = 4
# 语速,取值0-15,默认为5中语速
SPD = 5
# 音调,取值0-15,默认为5中语调
PIT = 5
# 音量,取值0-9,默认为5中音量
VOL = 5
# 下载的文件格式, 3:mp3(default) 4: pcm-16k 5: pcm-8k 6. wav
AUE = 3
FORMATS = {3: "mp3", 4: "pcm", 5: "pcm", 6: "wav"}
FORMAT = FORMATS[AUE]
CUID = "123456PYTHON"
TTS_URL = 'http://tsn.baidu.com/text2audio'
class DemoError(Exception):
pass
""" TOKEN start """
TOKEN_URL = 'http://openapi.baidu.com/oauth/2.0/token'
SCOPE = 'audio_tts_post' # 有此scope表示有tts能力,没有请在网页里勾选
def fetch_token():
print("fetch token begin")
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not SCOPE in result['scope'].split(' '):
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s ; EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
if __name__ == '__main__':
token = fetch_token()
tex = quote_plus(TEXT) # 此处TEXT需要两次urlencode
print(tex)
params = {'tok': token, 'tex': tex, 'per': PER, 'spd': SPD, 'pit': PIT, 'vol': VOL, 'aue': AUE, 'cuid': CUID,
'lan': 'zh', 'ctp': 1} # lan ctp 固定参数
data = urlencode(params)
print('test on Web Browser' + TTS_URL + '?' + data)
req = Request(TTS_URL, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
headers = dict((name.lower(), value) for name, value in f.headers.items())
has_error = ('content-type' not in headers.keys() or headers['content-type'].find('audio/') < 0)
except URLError as err:
print('asr http response http code : ' + str(err.code))
result_str = err.read()
has_error = True
save_file = "error.txt" if has_error else 'result.' + FORMAT
with open(save_file, 'wb') as of:
of.write(result_str)
if has_error:
if (IS_PY3):
result_str = str(result_str, 'utf-8')
print("tts api error:" + result_str)
print("result saved as :" + save_file)
API_KEY = '自己的API_KEY'
SECRET_KEY = '自己的SECRET_KEY '
大家可以去百度AI平台免费申请,这里是百度AI的官方案例,可以直接使用。
(如果大家不懂怎么申请的可以在下面评论)因为比较简单,所以就不详细介绍了。
合成之后生成一个result.wav文件,通过play函数进行播放。
play("result.wav")play
###播放欢迎词
def play(fname):
ding_wav = wave.open(fname, 'rb')
ding_data = ding_wav.readframes(ding_wav.getnframes())
#with no_alsa_error():
audio = PyAudio()
stream_out = audio.open(
format=audio.get_format_from_width(ding_wav.getsampwidth()),
channels=ding_wav.getnchannels(),
rate=ding_wav.getframerate(), input=False, output=True)
stream_out.start_stream()
stream_out.write(ding_data)
time.sleep(0.2)
stream_out.stop_stream()
stream_out.close()
audio.terminate()这里的play函数大家可以留意一下,网上很多都无法使用,尤其是在树莓派上了,这个代码是本人亲测可用,可以在树莓派上直接播放声音。
这样我通过唤醒词唤醒后,系统回复声音(哎,我在或者我来啦)
三、实现了智能语音音响--听音乐
这里我已经实现了第一个功能【休闲】-听音乐,智能音响
先给出演示视频
语音智能系统-语音音响播放音乐
下次更新实现了智能语音音响--听音乐的具体实现代码和操作。本期就更新语音唤醒。
后续延伸
修改回调函数可以完成更多工作

这里是语音智能管家的规划功能,后面会继续进行开发,更新记录这个过程。
欢迎在下方评论。
在平时的科研和任务不多的时候,利用空闲的时间去编写这个系统(因为空闲时间的乐趣就是做自己喜欢的事情,嘻嘻嘻,正好可以用来编写这个系统)。
每次完成一个小进度的时候都会在公众号和博客进行更新,记录一下这个过程(毕竟自己动手完成一件事,还是很有成就感的)
希望大家也能在这个过程中可以学习到一些知识(大牛就忽略了吧,哈哈哈)
同时在这个过程中,大家有更好的建议也可以进行评论交流,让这个系统更加完善。
【加群获取学习资料QQ群:901381280】
【各种爬虫源码获取方式】
识别文末二维码,回复:爬虫源码
欢迎关注公众号:Python爬虫数据分析挖掘,方便及时阅读最新文章
回复【开源源码】免费获取更多开源项目源码;