正则表达式为高级的文本模式匹配、抽取、与/或文本形式的搜索和替换功能提供了基础。 简单地说,正则表达式(简称为 regex)是一些由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一系列有相似特征的字符串。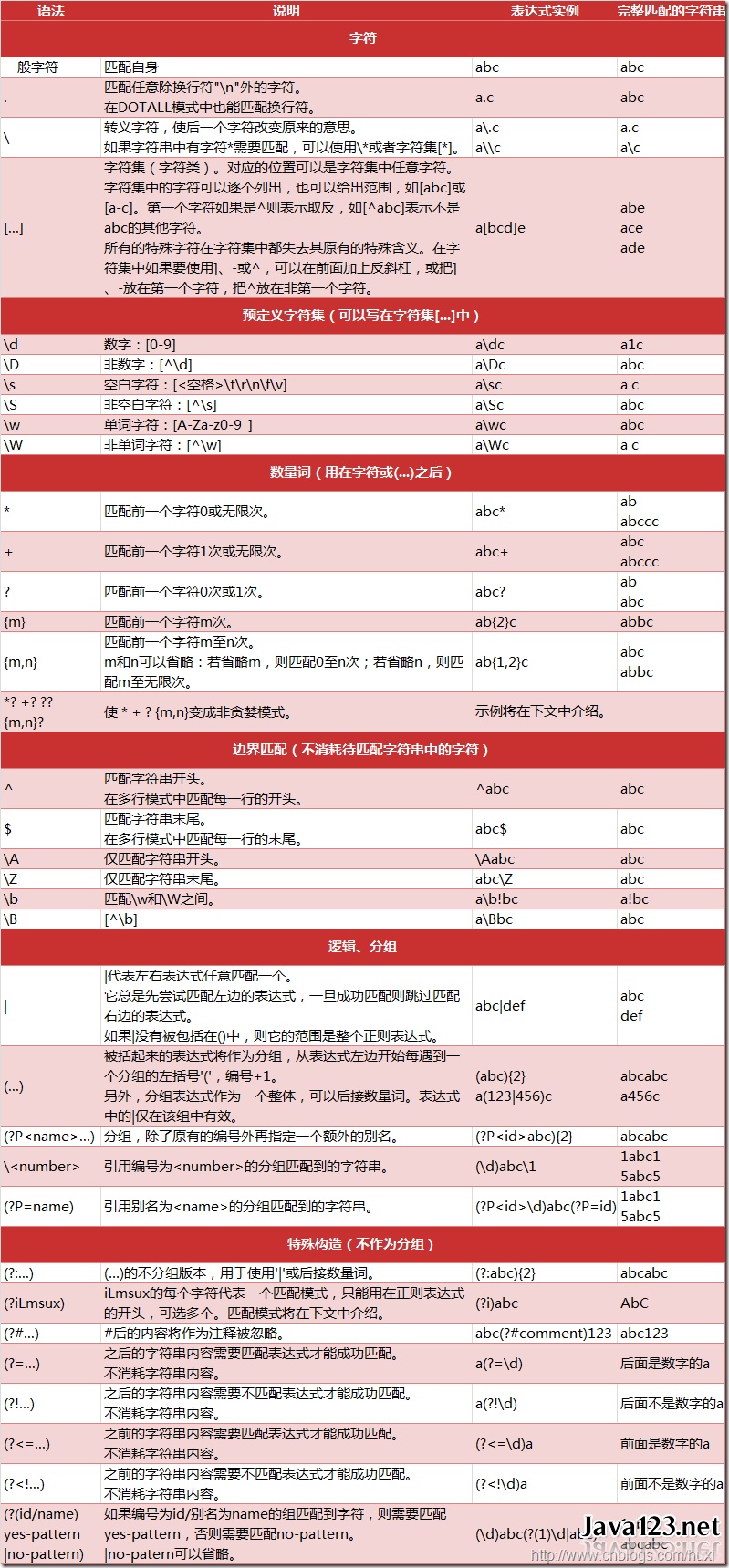
-
?匹配零次或一次前面的分组。
-
*匹配零次或多次前面的分组。
-
+匹配一次或多次前面的分组。
-
{n}匹配 n 次前面的分组。
-
{n,}匹配 n 次或更多前面的分组。
-
{,m}匹配零次到 m 次前面的分组。
-
{n,m}匹配至少 n 次、至多 m 次前面的分组。
-
{n,m}?或*?或+?对前面的分组进行非贪心匹配。
-
^spam 意味着字符串必须以 spam 开始。
-
spam$意味着字符串必须以 spam 结束。
-
.匹配所有字符,换行符除外。
-
d、w 和s 分别匹配数字、单词和空格。
-
D、W 和S 分别匹配出数字、单词和空格外的所有字符。
-
[abc]匹配方括号内的任意字符(诸如 a、b 或 c)。
-
[^abc]匹配不在方括号内的任意字符。