一、项目介绍
本项目立足医药领域,以垂直型医药网站为数据来源,以疾病为核心,使用爬虫脚本data_spider.py,构建起一个包含7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。原始数据包含8000多种病,包括与肝病相关的有200多种病。
本项目schema的设计根据所采集的结构化数据生成,对网页的结构化数据进行xpath解析,项目的数据存储采用Neo4j图数据库,并基于传统规则的方式完成了知识问答,并最终以cypher查询语句作为问答搜索sql,支持了问答服务。同时尝试把数据存储在mongodb上。项目源码已上传GitHub。
基于规则的问答系统没有复杂的算法,一般采用模板匹配的方式寻找匹配度最高的答案,回答结果依赖于问句类型、模板语料库的覆盖全面性,面对已知的问题,可以给出合适的答案,对于模板匹配不到的问题或问句类型,经常遇到不合适的回答。整个问答系统的优劣依赖于知识图谱中知识的数量与质量,大多数知识图谱规模不足,主要原因还是数据来源以及技术上知识的抽取与推理困难。本项目中关于疾病的起因、预防等,实际返回的是一大段文字,这里其实可以引入事件抽取的概念,进一步将原因结构化表示出来。这个可以后面进行尝试。
本项目将包括以下两部分的内容:
- 基于垂直网站数据的医药知识图谱构建
- 基于医药知识图谱的自动问答
二、项目效果
话不多少,直接上图。以下是实际问答运行过程中的截图:
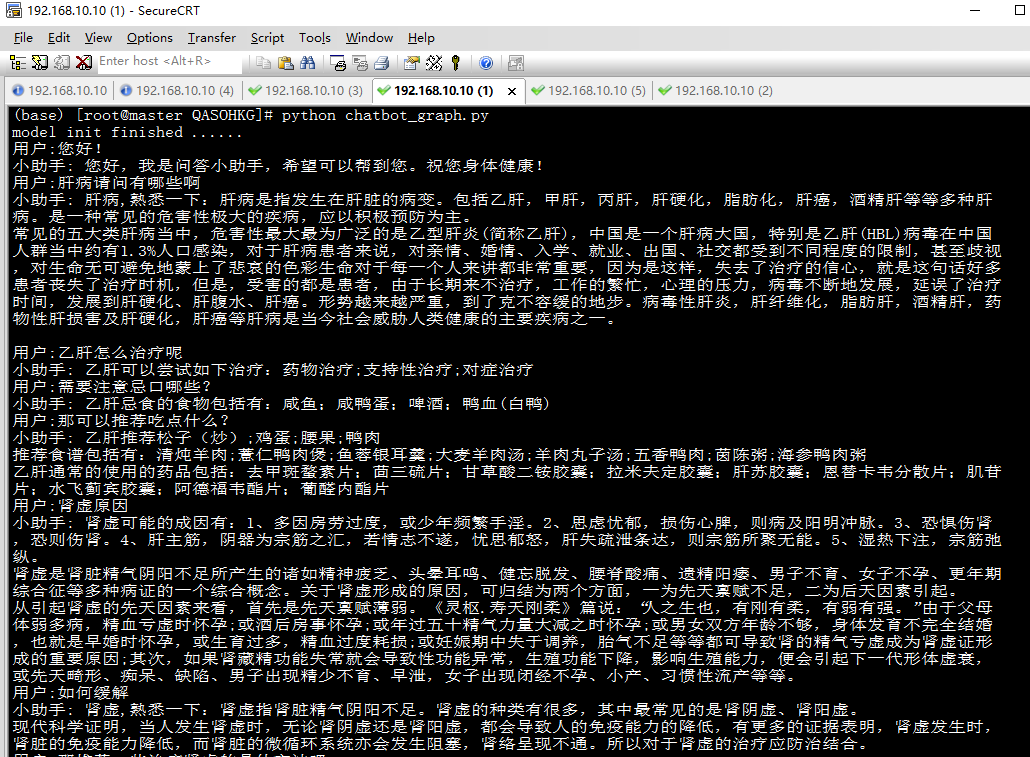
三、项目运行方式
1、配置要求:要求配置neo4j数据库及相应的python依赖包。neo4j数据库用户名密码记住,并修改相应文件。
2、知识图谱数据导入:python build_medicalgraph.py,导入的数据较多,估计需要几个小时。
3、启动问答:python chat_graph.py
四、实现方案
一、医疗知识图谱构建
1.1 业务驱动的知识图谱构建框架
项目主要文件目录如下:
'''
├── QASystemOnMedicalKG
├── answer_search.py # 问题查询及返回
├── build_medicalgraph.py # 将结构化json数据导入neo4j
├── chatbot_graph.py # 问答程序脚本
├── QASystemOnMedicalKG/data
├── hepatopathy.json # 肝病知识数据
├── medical.json # 全科知识数据
├── QASystemOnMedicalKG/dict
├── check.txt # 诊断检查项目实体库
├── deny.txt # 否定词库
├── department.txt # 医疗科目实体库
├── disease.txt # 疾病实体库
├── drug.txt # 药品实体库
├── food.txt # 食物实体库
├── producer.txt # 在售药品库
├── symptom.txt # 疾病症状实体库
├── QASystemOnMedicalKG/prepare_data
├── build_data.py # 数据库操作脚本
├── data_spider.py # 数据采集脚本
├── max_cut.py # 基于词典的最大前向/后向匹配
├── question_classifier.py # 问句类型分类脚本
├── question_parser.py # 问句解析脚本
'''
1.2 脚本目录
prepare_data/data_spider.py:数据采集脚本
prepare_data/build_data.py:数据预处理脚本
prepare_data/max_cut.py:基于词典的最大向前/向后切分脚本
build_medicalgraph.py:知识图谱入库脚本
1.3 爬虫部分
爬虫部分我没有实际操作,简单看了一下源码。
数据来源为寻医问药网的疾病百科 http://jib.xywy.com/ 。
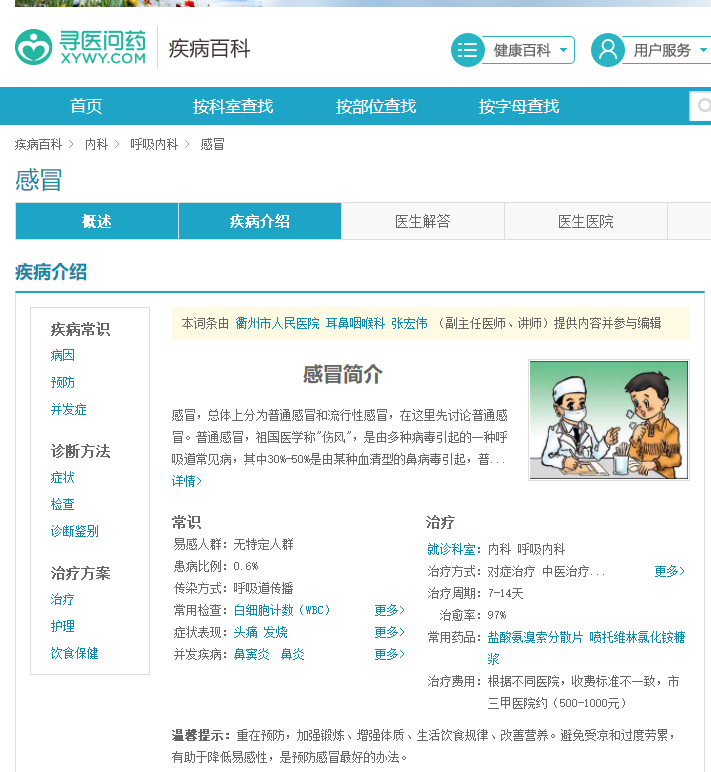
爬取疾病介绍页的简介、病因、预防、症状、检查、治疗、并发症、饮食保健等详情页的内容。
爬虫模块使用的是urllib库,数据存在MongoDB数据库中。
其中并发症使用了自己写的max_cut匹配脚本中的双向最大向前匹配max_biward_cut。
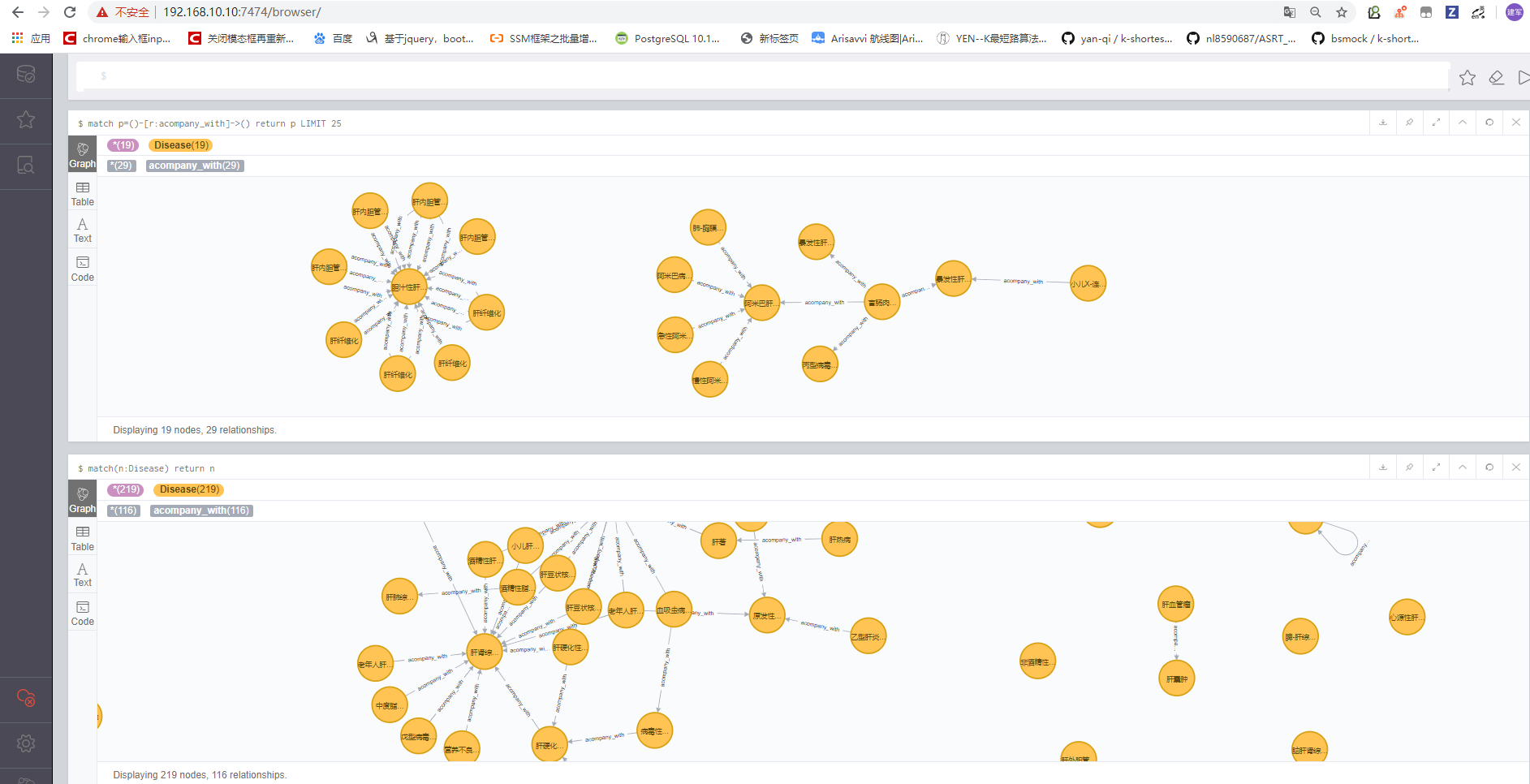
1.4 医药领域知识图谱规模
1.4.1 neo4j图数据库存储规模
1.4.2 知识图谱实体类型
| 实体类型 | 中文含义 | 实体数量 | 举例 |
|---|---|---|---|
| Check | 诊断检查项目 | 3,353 | 支气管造影;关节镜检查 |
| Department | 医疗科目 | 54 | 整形美容科;烧伤科 |
| Disease | 疾病 | 8,807 | 血栓闭塞性脉管炎;胸降主动脉动脉瘤 |
| Drug | 药品 | 3,828 | 京万红痔疮膏;布林佐胺滴眼液 |
| Food | 食物 | 4,870 | 番茄冲菜牛肉丸汤;竹笋炖羊肉 |
| Producer | 在售药品 | 17,201 | 通药制药青霉素V钾片;青阳醋酸地塞米松片 |
| Symptom | 疾病症状 | 5,998 | 乳腺组织肥厚;脑实质深部出血 |
| Total | 总计 | 44,111 | 约4.4万实体量级 |
1.4.3 知识图谱实体关系类型
| 实体关系类型 | 中文含义 | 关系数量 | 举例 |
|---|---|---|---|
| belongs_to | 属于 | 8,844 | <妇科,属于,妇产科> |
| common_drug | 疾病常用药品 | 14,649 | <阳强,常用,甲磺酸酚妥拉明分散片> |
| do_eat | 疾病宜吃食物 | 22,238 | <胸椎骨折,宜吃,黑鱼> |
| drugs_of | 药品在售药品 | 17,315 | <青霉素V钾片,在售,通药制药青霉素V钾片> |
| need_check | 疾病所需检查 | 39,422 | <单侧肺气肿,所需检查,支气管造影> |
| no_eat | 疾病忌吃食物 | 22,247 | <唇病,忌吃,杏仁> |
| recommand_drug | 疾病推荐药品 | 59,467 | <混合痔,推荐用药,京万红痔疮膏> |
| recommand_eat | 疾病推荐食谱 | 40,221 | <鞘膜积液,推荐食谱,番茄冲菜牛肉丸汤> |
| has_symptom | 疾病症状 | 5,998 | <早期乳腺癌,疾病症状,乳腺组织肥厚> |
| acompany_with | 疾病并发疾病 | 12,029 | <下肢交通静脉瓣膜关闭不全,并发疾病,血栓闭塞性脉管炎> |
| Total | 总计 | 294,149 | 约30万关系量级 |
(注意:belongs_to包括 科室属于科室 和 疾病属于科室 两种关系)
1.4.4 知识图谱属性类型
| 属性类型 | 中文含义 | 举例 |
|---|---|---|
| name | 疾病名称 | 喘息样支气管炎 |
| desc | 疾病简介 | 又称哮喘性支气管炎... |
| cause | 疾病病因 | 常见的有合胞病毒等... |
| prevent | 预防措施 | 注意家族与患儿自身过敏史... |
| cure_lasttime | 治疗周期 | 6-12个月 |
| cure_way | 治疗方式 | "药物治疗","支持性治疗" |
| cured_prob | 治愈概率 | 95% |
| easy_get | 疾病易感人群 | 无特定的人群 |
(注意:疾病的属性还包括cure_department)
知识库的构建是通过build_medicalgraph.py脚本实现。
二、基于医疗知识图谱的自动问答
2.1 技术架构
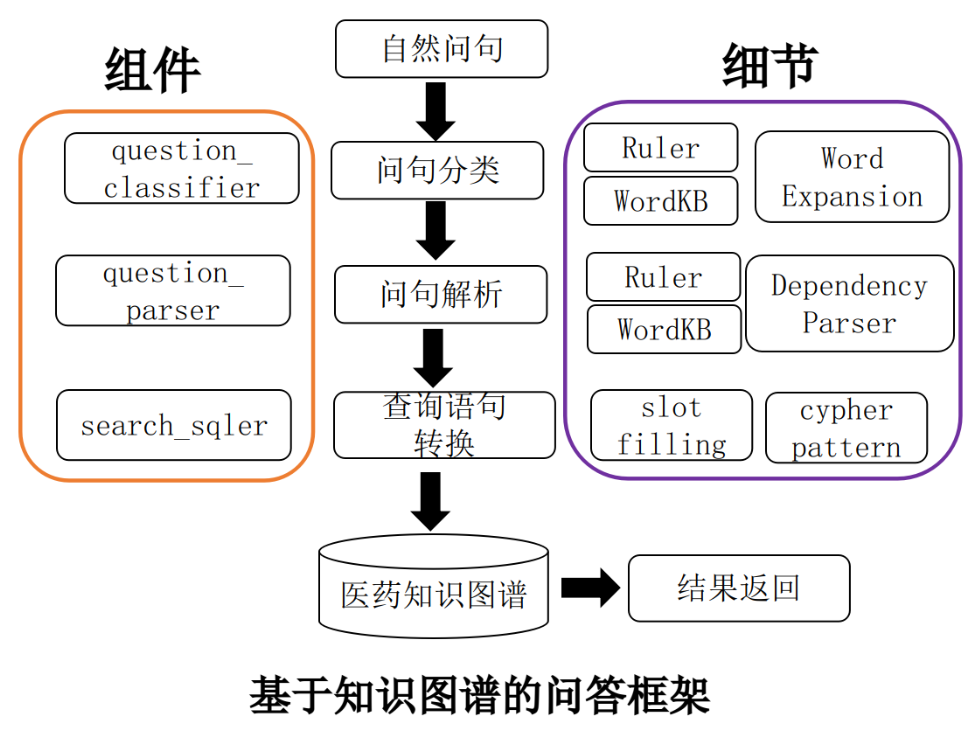
问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
2.2 脚本结构
question_classifier.py:问句类型分类脚本
question_parser.py:问句解析脚本
chatbot_graph.py:问答程序脚本
chatbot_graph.py
首先从需要运行的chatbot_graph.py文件开始分析。
该脚本构造了一个问答类ChatBotGraph,定义了QuestionClassifier类型的成员变量classifier、QuestionPase类型的成员变量parser和AnswerSearcher类型的成员变量searcher。
class ChatBotGraph: def __init__(self): self.classifier = QuestionClassifier() self.parser = QuestionPaser() self.searcher = AnswerSearcher()
该问答类的成员函数仅有一个chat_main函数
chat_main函数
首先传入用户输入问题,调用self.classifier.classify进行问句分类,如果没有对应的分类结果,则输出模板句式。如果有分类结果,则调用self.parser.parser_main对问句进行解析,再调用self.searcher.search_main查找对应的答案,如果有则返回答案,如果没有则输出模板句式。
def chat_main(self, sent): answer = '您好,我是问答小助手,希望可以帮到您。祝您身体棒棒!' res_classify = self.classifier.classify(sent) if not res_classify: return answer res_sql = self.parser.parser_main(res_classify) final_answers = self.searcher.search_main(res_sql) if not final_answers: return answer else: return ' '.join(final_answers)
question_classifier.py
该脚本构造了一个问题分类的类QuestionClassifier,定义了特征词路径、特征词、领域actree、词典、问句疑问词等成员变量。
特征词除了7类实体还包括由全部7类实体词构成的领域词region_words、否定词库deny_words。
构建领域actree通过调用self.build_actree实现。
构建词典通过调用self.build_wdtype_dict()实现。
问句疑问词包含了疾病的属性和边相关的问题词,参考上文中问答系统支持的问答类型。
build_actree函数
该函数构建领域actree,加速过滤。通过python的ahocorasick库实现。
ahocorasick是一种字符串匹配算法,由两种数据结构实现:trie和Aho-Corasick自动机。
Trie是一个字符串索引的词典,检索相关项时时间和字符串长度成正比。
AC自动机能够在一次运行中找到给定集合所有字符串。AC自动机其实就是在Trie树上实现KMP,可以完成多模式串的匹配。
def build_actree(self, wordlist): actree = ahocorasick.Automaton() # 初始化trie树 for index, word in enumerate(wordlist): actree.add_word(word, (index, word)) # 向trie树中添加单词 actree.make_automaton() # 将trie树转化为Aho-Corasick自动机 return actree
build_wdtype_dict函数
该函数根据7类实体构造 {特征词:特征词对应类型} 词典。
wd_dict = dict() for wd in self.region_words: wd_dict[wd] = [] if wd in self.disease_wds: wd_dict[wd].append('disease') ...
check_medical函数
通过ahocorasick库的iter()函数匹配领域词,将有重复字符串的领域词去除短的,取最长的领域词返回。功能为过滤问句中含有的领域词,返回{问句中的领域词:词所对应的实体类型}。
def check_medical(self, question): region_wds = [] for i in self.region_tree.iter(question): # ahocorasick库 匹配问题 iter返回一个元组,i的形式如(3, (23192, '乙肝')) wd = i[1][1] # 匹配到的词 region_wds.append(wd) stop_wds = [] for wd1 in region_wds: for wd2 in region_wds: if wd1 in wd2 and wd1 != wd2: stop_wds.append(wd1) # stop_wds取重复的短的词,如region_wds=['乙肝', '肝硬化', '硬化'],则stop_wds=['硬化'] final_wds = [i for i in region_wds if i not in stop_wds] # final_wds取长词 final_dict = {i:self.wdtype_dict.get(i) for i in final_wds} return final_dict
check_word函数
该函数检查问句中是否含有某实体类型内的特征词。
def check_words(self, wds, sent): for wd in wds: if wd in sent: return True return False
classify函数
该函数为分类主函数。
首先调用check_medical函数,获取问句中包含的领域词及其所在领域,并收集问句当中所涉及到的实体类型;
接着基于特征词进行分类,即调用check_word函数,看问句中是否包含某领域特征词,以及该领域是否在问句中包含的region_words的实体类型(types)里,以此来判断问句属于哪种类型。
# 症状 if self.check_words(self.symptom_qwds, question) and ('disease' in types): question_type = 'disease_symptom' question_types.append(question_type) if self.check_words(self.symptom_qwds, question) and ('symptom' in types): question_type = 'symptom_disease' question_types.append(question_type)
#已知食物找疾病 if self.check_words(self.food_qwds+self.cure_qwds, question) and 'food' in types: deny_status = self.check_words(self.deny_words, question) if deny_status: question_type = 'food_not_disease' else: question_type = 'food_do_disease' question_types.append(question_type)
如果没有查到若没有查到相关的外部查询信息,且类型为疾病,那么则将该疾病的描述信息返回(question_types = ['disease_desc']);若类型为症状,那么则将该症状的对应的疾病信息返回(question_types = ['symptom_disease'])。
然后将分类结果进行合并处理,组装成一个字典返回。
注意:
食物相关的问题需要检查否定词self.deny_words来判断是do_eat还是not_eat。
已知食物找疾病和已知检查项目查相应疾病的时候,check_words需要加上self.cure_qwds。
question_parser.py
问句分类后需要对问句进行解析。
该脚本创建一个QuestionPaser类,该类包含三个成员函数。
build_entitydict函数
例如:从分类结果的{'args': {'头痛': ['disease', 'symptom']}, 'question_types': ['disease_cureprob']}中获取args,返回{'disease': ['头痛'], 'symptom': ['头痛']}的形式。
sql_transfer函数
该函数真的不同的问题类型,转换为Cypher查询语言并返回。
# 查询疾病的原因 if question_type == 'disease_cause': sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cause".format(i) for i in entities]
# 查询疾病的忌口 elif question_type == 'disease_not_food': sql = ["MATCH (m:Disease)-[r:no_eat]->(n:Food) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
注意:
- 查询可能为查询中心疾病节点的属性,也可能为查询关联边。
- 疾病的并发症需要双向查询。
- 建议吃的东西包括do_eat和recommand_eat两种关联边。
- 查询药品相关记得扩充药品别名,包括common_drug和recommand_durg两种关联边。
parser_main函数
该函数为问句解析主函数。
首先传入问句分类结果,获取问句中领域词及其实体类型。
接着调用build_entitydict函数,返回形如{'实体类型':['领域词'],...}的entity_dict字典。
然后对问句分类返回值中[‘question_types’]的每一个question_type,调用sql_transfer函数转换为neo4j的Cypher语言。
最后组合每种question_type转换后的sql查询语句。
answer_search.py
问句解析之后需要对解析后的结果进行查询。
该脚本创建了一个AnswerSearcher类。与build_medicalgraph.py类似,该类定义了Graph类的成员变量g和返回答案列举的最大个数num_list。
该类的成员函数有两个,一个查询主函数一个回复模块。
search_main函数
传入问题解析的结果sqls,将保存在queries里的[‘question_type’]和[‘sql’]分别取出。
首先调用self.g.run(query).data()函数执行[‘sql’]中的查询语句得到查询结果,
再根据[‘question_type’]的不同调用answer_prettify函数将查询结果和答案话术结合起来。
最后返回最终的答案。
answer_prettify函数
该函数根据对应的qustion_type,调用相应的回复模板。
elif question_type == 'disease_cause': desc = [i['m.cause'] for i in answers] subject = answers[0]['m.name'] final_answer = '{0}可能的成因有:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
缺失实体填充
这里用户的第二个问题没有疾病实体,默认采用上一轮的疾病实体。
方法是在question_classifier.py的check_medical函数里增加全局变量:
global diseases_dict if final_dict: diseases_dict = final_dict
并在classify函数里判断:
if not medical_dict: if 'diseases_dict' in globals(): # 判断是否是首次提问,若首次提问,则diseases_dict无值 medical_dict = diseases_dict else: return {}
增加疾病属性can_eat
增加了一个疾病属性:can_eat,对应增加了一个问题分类:
# 推荐食品 if self.check_words(self.food_qwds, question) and 'disease' in types: deny_status = self.check_words(self.deny_words, question) if deny_status: question_type = 'disease_not_food' else: question_type = 'disease_do_food' if self.check_words(['能吃','能喝','可以吃','可以喝'], question): question_types.append('disease_can_eat') print(question_type) question_types.append(question_type)
2.3 支持问答类型
| 问句类型 | 中文含义 | 问句举例 |
|---|---|---|
| disease_symptom | 疾病症状 | 乳腺癌的症状有哪些? |
| symptom_disease | 已知症状找可能疾病 | 最近老流鼻涕怎么办? |
| disease_cause | 疾病病因 | 为什么有的人会失眠? |
| disease_acompany | 疾病的并发症 | 失眠有哪些并发症? |
| disease_not_food | 疾病需要忌口的食物 | 失眠的人不要吃啥? |
| disease_do_food | 疾病建议吃什么食物 | 耳鸣了吃点啥? |
| food_not_disease | 什么病最好不要吃某事物 | 哪些人最好不好吃蜂蜜? |
| food_do_disease | 食物对什么病有好处 | 鹅肉有什么好处? |
| disease_drug | 啥病要吃啥药 | 肝病要吃啥药? |
| drug_disease | 药品能治啥病 | 板蓝根颗粒能治啥病? |
| disease_check | 疾病需要做什么检查 | 脑膜炎怎么才能查出来? |
| check_disease | 检查能查什么病 | 全血细胞计数能查出啥来? |
| disease_prevent | 预防措施 | 怎样才能预防肾虚? |
| disease_lasttime | 治疗周期 | 感冒要多久才能好? |
| disease_cureway | 治疗方式 | 高血压要怎么治? |
| disease_cureprob | 治愈概率 | 白血病能治好吗? |
| disease_easyget | 疾病易感人群 | 什么人容易得高血压? |
| disease_desc | 疾病描述 | 糖尿病 |