1.描述:

购物者依靠Home Depot的产品权威来寻找和购买最新产品,并及时获得满足其家居装修需求的解决方案。从安装新的吊扇到改造整个厨房,只需点击鼠标或点击屏幕,客户就可以快速获得正确的查询结果。速度,准确性和无摩擦的客户体验至关重要。
Home Depot要求Kagglers通过开发能够准确预测搜索结果相关性的模型来帮助他们改善客户的购物体验。
搜索相关性是Home Depot用于衡量客户获得正确产品的速度的隐含指标。目前,人类评估者评估潜在变化对其搜索算法的影响,这是一个缓慢而主观的过程。通过删除或最小化搜索相关性评估中的人工输入,Home Depot希望增加其团队可以对当前搜索算法执行的迭代次数。
2.评估
根据均方根误差(RMSE)评估提交。
提交文件
对于测试集中的每个ID,您必须预测相关性。这是[1,3]中的实数。该文件应包含标头,并具有以下格式:
id,相关性
1,1
4,2
5,3
等
3.代码实现
#!/usr/bin/env python
# coding: utf-8
# In[1]:
#目的:给出输入关键字与搜索结果,评价搜索准确度
#处理思路
#1,导入包、数据 -> 合并数据格式concat,merge,
#2,文本预处理 -> 【简单方法】:看输入词是在搜索结果中出现几次,需要先统一数据集格式 -> str_stemmer and str_commond_words 处理数据
#3,自制文本特征 -> 关键词长度/搜索词语与title和describtion中重复词语数 -> 去掉之前的英文,保留自制特征
#4,重塑训练/测试集 -> 拆分出X_train, X_test, y_train, 去除label
#5,建立模型:Ridge回归模型RandomForestRegressor 找出最佳参数max_depth=7 通过多种参数导入 -> 画图
#6,上传结果:生成csv文件
# In[2]:
# 1) 导入需要用的库
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier, BaggingRegressor
from nltk.stem.snowball import SnowballStemmer
import os
os.chdir('/Users/Administrator')
# In[3]:
#读取数据
df_train = pd.read_csv('train.csv', encoding = "ISO-8859-1")
df_test = pd.read_csv('test.csv', encoding = "ISO-8859-1")
df_desc = pd.read_csv('product_descriptions.csv')
# In[4]:
df_train.head()

# In[5]:
df_desc.head()

# In[6]:
#合并测试集与训练集,便于统一文本预处理
#PANDAS 数据合并与重塑(concat篇):https://blog.csdn.net/stevenkwong/article/details/52528616
#PANDAS 数据合并与重塑(join/merge篇):https://blog.csdn.net/stevenkwong/article/details/52540605
df_all = pd.concat((df_train, df_test), axis=0, ignore_index=True)
df_all.head()
#print(df_all.shape)
# In[7]:
#把描述信息加入表,how='left'表示左边全部保留,on表示以什么为基准对齐
df_all = pd.merge(df_all, df_desc, how='left', on='product_uid')
df_all.head()

# In[8]:
#2) 文本预处理,把表格的语句处理为计算机能懂的格式,这里使用NLTK
stemmer = SnowballStemmer('english')
#这里简单处理,只提取了词干
def str_stemmer(s):
return " ".join([stemmer.stem(word) for word in s.lower().split()])
#计算"关键词次数"
def str_common_word(str1, str2):
return sum(int(str2.find(word)>=0) for word in str1.split())
# In[9]:
#把每一个column都跑一遍,用str_stemmer清洁所有的文本内容
df_all['search_term'] = df_all['search_term'].map(lambda x: str_stemmer(x))
# In[10]:
df_all['product_title'] = df_all['product_title'].map(lambda x: str_stemmer(x))
# In[11]:
df_all['product_description'] = df_all['product_description'].map(lambda x: str_stemmer(x))
# In[12]:
#3) 自制文本特征
#关键字的长度
df_all['len_of_query'] = df_all['search_term'].map(lambda x: len(x.split())).astype(np.int64)
#搜索词与标题中有多少关键字重合
df_all['commons_in_title'] = df_all.apply(lambda x:str_common_word(x['search_term'], x['product_title']), axis=1)
#搜索词与描述中有多少关键字重合
df_all['commons_in_desc'] = df_all.apply(lambda x: str_common_word(x['search_term'], x['product_description']), axis=1)
#搞完之后,我们把不能被『机器学习模型』处理的column给drop掉,这一步太偷懒了
df_all = df_all.drop(['search_term', 'product_title', 'product_description'], axis=1)
# In[13]:
df_all.head(10)

# In[14]:
#4) 重塑训练/测试集合, 刚才把train与test合并了,现在分开
df_train = df_all.loc[df_train.index]
df_test = df_all.loc[df_test.index]
#记录id,后续上传能用
test_ids = df_test['id']
#分离出y_train
y_train = df_train['relevance'].values
#删除原集合中的label
X_train = df_train.drop(['id', 'relevance'], axis=1).values
X_test = df_test.drop(['id', 'relevance'], axis=1).values
# In[15]:
#5)建立模型:Ridge模型
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
get_ipython().run_line_magic('matplotlib', 'inline')
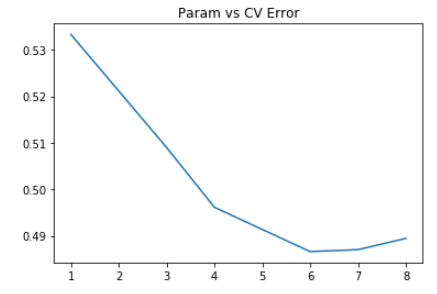
params = [1, 3, 4, 6, 7, 8,]
test_scores = []
for param in params:
clf = RandomForestRegressor(n_estimators=30, max_depth=param)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=5, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
import matplotlib.pyplot as plt
plt.plot(params, test_scores)
plt.title("Param vs CV Error");
# In[16]:
#6) 上传结果
rf = RandomForestRegressor(n_estimators=30, max_depth=7)
rf.fit(X_train, y_train)
# In[17]:
y_pred = rf.predict(X_test)