0 搭建项目
- pom参考


<dependencies> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <!-- Spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.10</artifactId> <version>1.6.0</version> </dependency> <!-- SparkSQL --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>1.6.0</version> </dependency> <!-- SparkSQL ON Hive--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.10</artifactId> <version>1.6.0</version> </dependency> <!--SparkStreaming--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.6.0</version> <!--<scope>provided</scope>--> </dependency> <!-- SparkStreaming + Kafka --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.10.5</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-compiler</artifactId> <version>2.10.5</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-reflect</artifactId> <version>2.10.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.5</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.5</version> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.10</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-it</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> <version>3.2.0</version> </dependency> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>1.1.1</version> </dependency> <!--连接 Redis 需要的包--> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.6.1</version> </dependency> <!--mysql依赖的jar包--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <dependency> <groupId>com.google.collections</groupId> <artifactId>google-collections</artifactId> <version>1.0</version> </dependency> </dependencies> <repositories> <repository> <id>central</id> <name>Maven Repository Switchboard</name> <layout>default</layout> <url>http://repo2.maven.org/maven2</url> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> <build> <sourceDirectory>src/main/java</sourceDirectory> <testSourceDirectory>src/test/java</testSourceDirectory> <plugins> <!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 --> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <!-- MAVEN 编译使用的JDK版本 --> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.10</version> <configuration> <skip>true</skip> </configuration> </plugin> </plugins> </build>
1 demo1--WorldCount
- 项目目录下新建data文件夹,再新建world.csv文件
hello,spark
hello,scala,hadoop
hello,hdfs
hello,spark,hadoop
hello- scala版本---SparkWC.scala
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * spark wordcount */ object SparkWC { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("wordcount").setMaster("local") val sc = new SparkContext(conf) sc.textFile("./data/world.csv").flatMap( _.split(",")).map((_,1)).reduceByKey(_+_).foreach(println) sc.stop() // 下面是每一步的分析 // //conf 可以设置SparkApplication 的名称,设置Spark 运行的模式 // val conf = new SparkConf() // conf.setAppName("wordcount") // conf.setMaster("local") // //SparkContext 是通往spark 集群的唯一通道 // val sc = new SparkContext(conf) // // val lines: RDD[String] = sc.textFile("./data/world.csv") // val words: RDD[String] = lines.flatMap(line => { // line.split(",") // }) // val pairWords: RDD[(String, Int)] = words.map(word=>{new Tuple2(word,1)}) // val result: RDD[(String, Int)] = pairWords.reduceByKey((v1:Int, v2:Int)=>{v1+v2}) // result.foreach(one=>{ // println(one) // }) } }
-
测试

- java版本---SparkWC.scala
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; import java.util.Arrays; import java.util.Iterator; public class SparkWordCount { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local"); conf.setAppName("wc"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> lines = sc.textFile("./data/world.csv"); JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(",")); } }); JavaPairRDD<String, Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<>(s, 1); } }); JavaPairRDD<String, Integer> result = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); result.foreach(new VoidFunction<Tuple2<String, Integer>>() { @Override public void call(Tuple2<String, Integer> tp) throws Exception { System.out.println(tp); } }); sc.stop(); } }
- 测试

2 demo2--join算子
- 代码及测试
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ListBuffer object Taiko extends App { val conf = new SparkConf().setMaster("local").setAppName("wc"); val sc = new SparkContext(conf) //demo1-5 data start val nameRDD: RDD[(String, Int)] = sc.parallelize(List[(String, Int)]( ("zhangsan", 18), ("lisi", 19), ("wangwu", 20), ("zhaoliu", 21) )) val sourceRDD: RDD[(String, Int)] = sc.parallelize(List[(String, Int)]( ("zhangsan", 100), ("lisi", 200), ("wangwu", 300), ("tianqi", 400) )) //demo1-5 data end //demo1 join //val result: RDD[(String, (Int, Int))] = nameRDD.join(sourceRDD) //result.foreach(println) /** demo1结果 * (zhangsan,(18,100)) * (wangwu,(20,300)) * (lisi,(19,200)) */ //demo2 leftOuterJoin //val result: RDD[(String, (Int, Option[Int]))] = nameRDD.leftOuterJoin(sourceRDD) //result.foreach(println) /** demo2结果 * (zhangsan,(18,Some(100))) * (wangwu,(20,Some(300))) * (zhaoliu,(21,None)) * (lisi,(19,Some(200))) */ /* result.foreach(res => { val name = res._1 val v1 = res._2._1 val v2 = res._2._2.getOrElse("没有分数") println(s"name=$name,age=$v1,scoure=$v2") })*/ /** demo2结果 * name=zhangsan,age=18,scoure=100 * name=wangwu,age=20,scoure=300 * name=zhaoliu,age=21,scoure=没有分数 * name=lisi,age=19,scoure=200 */ //demo3 rightOuterJoin //val result: RDD[(String, (Option[Int], Int))] = nameRDD.rightOuterJoin(sourceRDD) //result.foreach(println) /** demo3结果 * (zhangsan,(Some(18),100)) * (wangwu,(Some(20),300)) * (tianqi,(None,400)) * (lisi,(Some(19),200)) */ //demo4 fullOuterJoin //val result: RDD[(String, (Option[Int], Option[Int]))] = nameRDD.fullOuterJoin(sourceRDD) //result.foreach(println) /** demo4结果 * (zhangsan,(Some(18),Some(100))) * (wangwu,(Some(20),Some(300))) * (zhaoliu,(Some(21),None)) * (tianqi,(None,Some(400))) * (lisi,(Some(19),Some(200))) */ //demo5 union //val result: RDD[(String, Int)] = nameRDD.union(sourceRDD) //result.foreach(println) /** demo5结果 * (zhangsan,18) * (lisi,19) * (wangwu,20) * (zhaoliu,21) * (zhangsan,100) * (lisi,200) * (wangwu,300) * (tianqi,400) */ //demo6 分区 val nameRDD1: RDD[(String, Int)] = sc.parallelize(List[(String, Int)]( ("zhangsan", 18), ("lisi", 19), ("wangwu", 20), ("zhaoliu", 21) ), 3) val sourceRDD1: RDD[(String, Int)] = sc.parallelize(List[(String, Int)]( ("zhangsan", 100), ("lisi", 200), ("wangwu", 300), ("tianqi", 400) ), 4) val p1: Int = nameRDD1.getNumPartitions val p2: Int = sourceRDD1.getNumPartitions //val result: RDD[(String, (Int, Int))] = nameRDD1.join(sourceRDD1) //val p3: Int = result.getNumPartitions //println(s"p1:$p1,p2:$p2,p3:$p3") /** p1:3,p2:4,p3:4 和多的分区保持一致 */ //val result: RDD[(String, Int)] = nameRDD1.union(sourceRDD1) //val p3: Int = result.getNumPartitions //println(s"p1:$p1,p2:$p2,p3:$p3") /** p1:3,p2:4,p3:7 数据其实没有移动,只是把分区加在了一起 */ //demo7 intersection交集 subtract差集 val rdd1: RDD[Int] = sc.parallelize(List[Int](1, 2, 3)) val rdd2: RDD[Int] = sc.parallelize(List[Int](2, 3, 5)) //rdd1.intersection(rdd2).foreach(println) /** * 3 * 2 */ //rdd1.subtract(rdd2).foreach(println) /** 1 */ //rdd2.subtract(rdd1).foreach(println) /** 5 */ //demo8 优化频繁操作 mapPartitions分区数据处理 val rdd: RDD[String] = sc.parallelize(List[String]("hello1", "hello2", "hello3", "hello4"), 2) /* rdd.map(one => { println("建立数据库连接...") println(s"插入数据库数据:$one") println("关闭数据库连接...") one + "!" }).count()*/ /** 频繁建立数据库连接!!!!!!! * 建立数据库连接... * 插入数据库数据:hello1 * 关闭数据库连接... * 建立数据库连接... * 插入数据库数据:hello2 * 关闭数据库连接... * 建立数据库连接... * 插入数据库数据:hello3 * 关闭数据库连接... * 建立数据库连接... * 插入数据库数据:hello4 * 关闭数据库连接... */ rdd.mapPartitions(iter => { val list = new ListBuffer[String] println("建立数据库连接...") while (iter.hasNext) { val str = iter.next() println(s"插入数据库数据:$str") list.+=(str) } println("关闭数据库连接...") list.iterator }).count() /** * 建立数据库连接... * 插入数据库数据:hello1 * 插入数据库数据:hello2 * 关闭数据库连接... * 建立数据库连接... * 插入数据库数据:hello3 * 插入数据库数据:hello4 * 关闭数据库连接... */ }
3 demo3-- spark集群验证 yarn集群验证
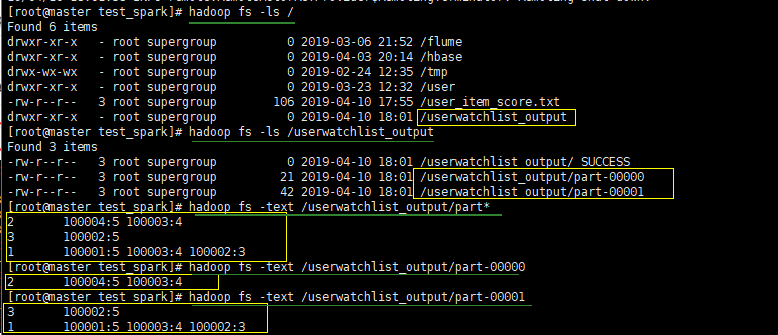
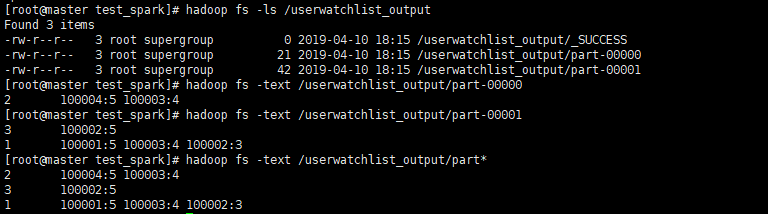
- user_item_score.txt
1 100001 5
1 100002 3
1 100003 4
3 100001 2
3 100002 5
2 100001 1
2 100002 2
2 100003 4
2 100004 5- userwatchlist
package com.test.scala.spark import org.apache.spark.{SparkConf, SparkContext} object userwatchlist { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("userwatchlist test") val sc = new SparkContext(conf) val input_path = sc.textFile("./data/user_item_score.txt") val output_path = "./data/userwatchlist_output" //过滤掉分数小于2的数据 val data = input_path.filter(x => { val fields = x.split(" ") fields(2).toDouble > 2 }).map(x => { /* 原始数据 user item score -> (user, (item1 score1)) (user, (item2 score2)) -> (user,((item1 score1) (item2 score2))) ->目标 user -> item item item */ val fields = x.split(" ") (fields(0).toString, (fields(1).toString, fields(2).toString)) }).groupByKey().map(x => { val userid = x._1 val item_score_tuple_list = x._2 //根据score进行排序 val tmp_arr = item_score_tuple_list.toArray.sortWith(_._2 > _._2) var watchlen = tmp_arr.length //取前5个 if (watchlen > 5) { watchlen = 5 } val strbuf = new StringBuilder for (i <- 0 until watchlen) { strbuf ++= tmp_arr(i)._1 strbuf.append(":") strbuf ++= tmp_arr(i)._2 strbuf.append(" ") } userid + " " + strbuf }) data.saveAsTextFile(output_path) } }
-
3.1本地验证结果

- 3.2通过spark集群验证
- 修改scala类
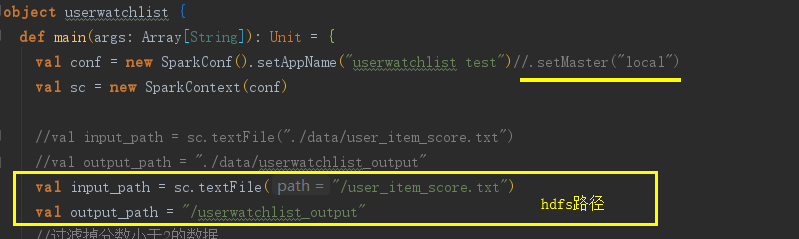
- maven打包
- 将文件和jar包上传到linux上
- 在将文件上传到hdfs上
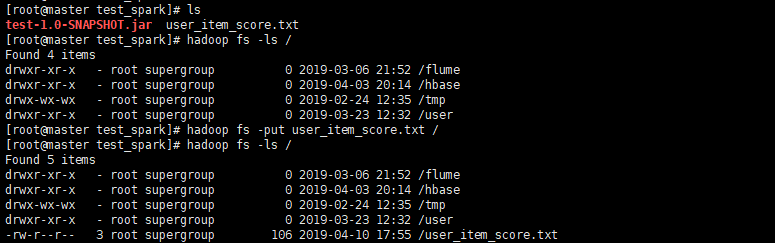
- 新建run.sh

/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master spark://master:7077 --num-executors 2 --executor-memory 1g --executor-cores 1 --driver-memory 1g --class com.test.scala.spark.userwatchlist /root/test_spark/test-1.0-SNAPSHOT.jar- 运行
bash run.sh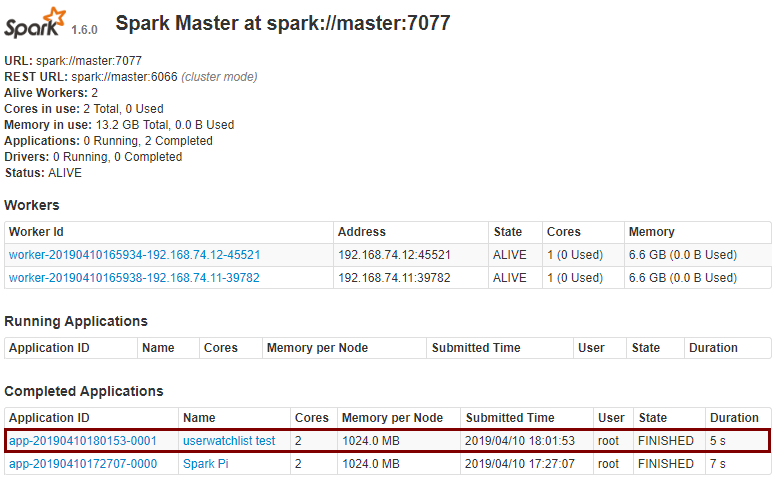
- 修改scala类
- 3.3通过hadoop集群验证
- 修改run.sh
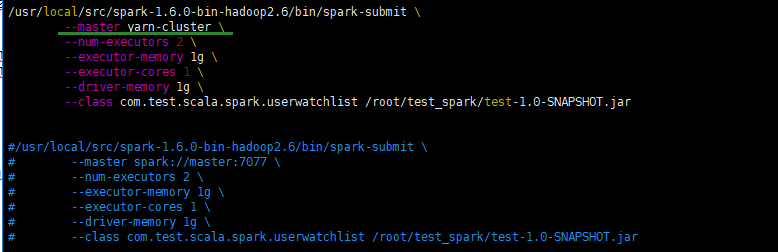
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master yarn-cluster --num-executors 2 --executor-memory 1g --executor-cores 1 --driver-memory 1g --class com.test.scala.spark.userwatchlist /root/test_spark/test-1.0-SNAPSHOT.jar- 删除刚刚的输出路径(如果没操作spark集群验证的则不用)
hadoop fs -rmr- /userwatchlist_output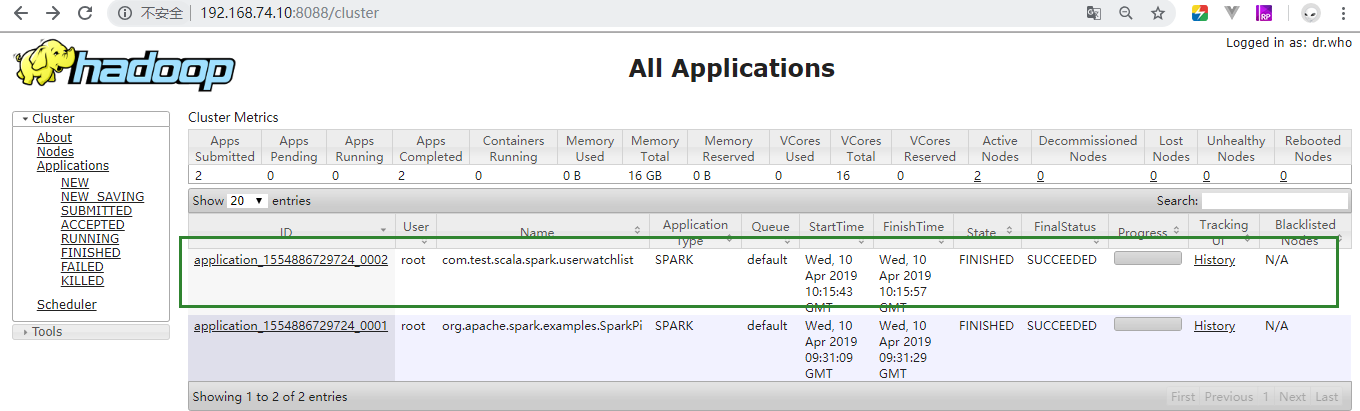
- 修改run.sh
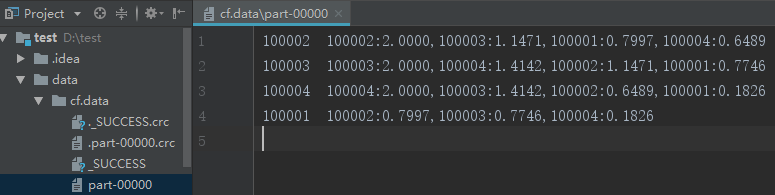
4 demo4-- cf算法
package com.test.scala.spark import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ArrayBuffer import scala.math._ object cf { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setMaster("local") conf.setAppName("CF") val sc = new SparkContext(conf) val input_path = args(0).toString val output_path = args(1).toString val lines = sc.textFile(input_path) val max_prefs_per_user = 20 val topn = 5 //step1 val ui_rdd = lines.map { x => val fileds = x.split(" ") (fileds(0).toString, (fileds(1).toString, fileds(2).toDouble)) }.groupByKey().flatMap { x => val user = x._1 val item_score_list = x._2 var is_arr = item_score_list.toArray var is_list_len = is_arr.length if (is_list_len > max_prefs_per_user) { is_list_len = max_prefs_per_user } //转置 var i_us_arr = new ArrayBuffer[(String, (String, Double))]() for (i <- 0 until is_list_len) { i_us_arr += ((is_arr(i)._1,(user,is_arr(i)._2))) } i_us_arr }.groupByKey().flatMap{x=> //归一化 val item = x._1 val u_list = x._2 val us_arr = u_list.toArray var sum:Double = 0.0 for(i <- 0 until us_arr.length){ sum += pow(us_arr(i)._2,2) } sum = sqrt(sum) var u_is_arr = new ArrayBuffer[(String, (String, Double))]() for(i <- 0 until us_arr.length){ u_is_arr += ((us_arr(i)._1,(item,us_arr(i)._2 / sum))) } u_is_arr /* 设置参数测试 (2,CompactBuffer((100002,0.3244428422615251), (100003,0.7071067811865475), (100004,1.0), (100001,0.18257418583505536))) (3,CompactBuffer((100002,0.8111071056538127), (100001,0.3651483716701107))) (1,CompactBuffer((100002,0.48666426339228763), (100003,0.7071067811865475), (100001,0.9128709291752769))) */ }.groupByKey() //step2 val unpack_rdd = ui_rdd.flatMap{x=> val is_arr = x._2.toArray var ii_s_arr = new ArrayBuffer[((String,String),Double)]() for(i <- 0 until is_arr.length-1){ for(j <- 0 until is_arr.length){ ii_s_arr += (((is_arr(i)._1,is_arr(j)._1),is_arr(i)._2 * is_arr(j)._2)) ii_s_arr += (((is_arr(j)._1,is_arr(i)._1),is_arr(i)._2 * is_arr(j)._2)) } } ii_s_arr /*测试 ((100002,100002),0.10526315789473685) ((100002,100002),0.10526315789473685) ((100002,100003),0.22941573387056174) ((100003,100002),0.22941573387056174) ((100002,100004),0.3244428422615251) ((100004,100002),0.3244428422615251) ((100002,100001),0.05923488777590923) ((100001,100002),0.05923488777590923) ((100003,100002),0.22941573387056174) ((100002,100003),0.22941573387056174) ((100003,100003),0.4999999999999999) ((100003,100003),0.4999999999999999)*/ } //step3 unpack_rdd.groupByKey().map{x=> val ii_pair = x._1 val s_list = x._2 val s_arr = s_list.toArray var score:Double = 0.0 for(i <- 0 until s_arr.length){ score += s_arr(i) } (ii_pair._1,(ii_pair._2,score)) /*测试 (100002,(100002,2.0)) (100002,(100001,0.7996709849747747)) (100001,(100003,0.7745966692414834)) (100003,(100002,1.1470786693528088)) (100001,(100004,0.18257418583505536)) (100004,(100001,0.18257418583505536)) (100004,(100002,0.6488856845230502)) (100004,(100004,2.0)) (100003,(100001,0.7745966692414834)) (100003,(100003,1.9999999999999996)) (100002,(100004,0.6488856845230502)) (100001,(100002,0.7996709849747747)) (100003,(100004,1.414213562373095)) (100004,(100003,1.414213562373095)) (100002,(100003,1.1470786693528088))*/ }.groupByKey().map{x=> val item_a = x._1 val item_list = x._2 val bs_arr = item_list.toArray.sortWith(_._2 > _._2) var len = bs_arr.length if(len > topn){ len=topn } val s = new StringBuilder for(i <- 0 until len){ val item = bs_arr(i)._1 val score = "%1.4f" format bs_arr(i)._2 s.append(item+":"+score) if(i<len-1){ s.append(",") } } item_a + " " + s }.saveAsTextFile(output_path) } }
- 设置参数测试
- 结果