一、Linux 模型
孟宁老师的ppt上说,操作系统的三大核心功能是进程管理,内存管理和文件系统,我也准备以这三个核心功能作为梳理Linux模型的思路
1.中断机制
对进程调度、IO,都离不开内核的中断机制,所以我想先写一下中断
中断最初用于避免CPU轮询I/O设备,就绪状态发生时让I/O设备主动通过中断信号通知CPU,大大提高了CPU在输入输出上的工作效率,这就是硬件中断(Interruot)。后来随着中断适用范围扩大,比如解决机器运行过程出现的异常情况以及系统调用的实现等,这就产生了软件中断(Exception),又分为故障(fault)、陷阱(trap)和退出(Abort)。简而言之,中断使得CPU能从当前进程的指令流中切换出来,转去执行预定义的中断处理程序(内核代码入口)
在硬件级别上,中断的一个一般流程如下:
- 每个中断由0~255之间的一个数来标识,Intel称其为中断向量,中断描述符表(IDT)记录了中断向量和对应的中断处理程序入口地址。内核在中断发生前,会初始化IDT,idtr寄存器指向该表的基地址
- 在执行下一条指令前,CPU会检查之前有无发生中断
- 获取中断向量号,配合idtr寄存器中IDT表的基地址,即可获得中断处理程序的入口地址
- 检查是否是由用户态陷入内核态
- 如果是,将用户栈替换为内核栈(通过装载ss和esp寄存器),并将之前的ss,esp,eflags,eip等CPU关键上下文压栈保存;否则不需要替换ss和esp寄存器
- 将中断处理程序的入口地址装载进eip寄存器,即开始中断处理程序
- 弹出内核栈中保存的CPU关键上下文并恢复,如果之前由用户态陷入内核态,那么还会替换为用户栈
在软件级别上,中断过程被分为了上半部和下半部
- 上半部:实现快速响应,处理更多中断请求,该部分仅简单地读取寄存器中的中断状态并清除中断标志,就像登记了一个中断事件到下半部的处理队列中。该部分不可被打断
- 下半部:真正完成中断处理工作,允许被打断。下半部可以使用软中断、tasklet或工作队列实现
中断的一个典型应用就是系统调用,对诸如分配内存、创建进程等操作,交由用户程序来执行是很危险的。通过trap(一般是int $0x80),用户态可主动发出中断陷入内核态,中断处理程序读eax寄存器可以获得系统调用号,然后执行对应的系统调用例程,由可信任的内核来做这些操作就是安全的
2.进程控制
进程是如何被描述的?
要管理进程,就需要系统能够描述进程的状态、活动和持有的资源等。在Linux中,使用task_struct描述进程,它是进程存在的唯一标志

我们可以更深入的来看一下task_struct所描述的内容:
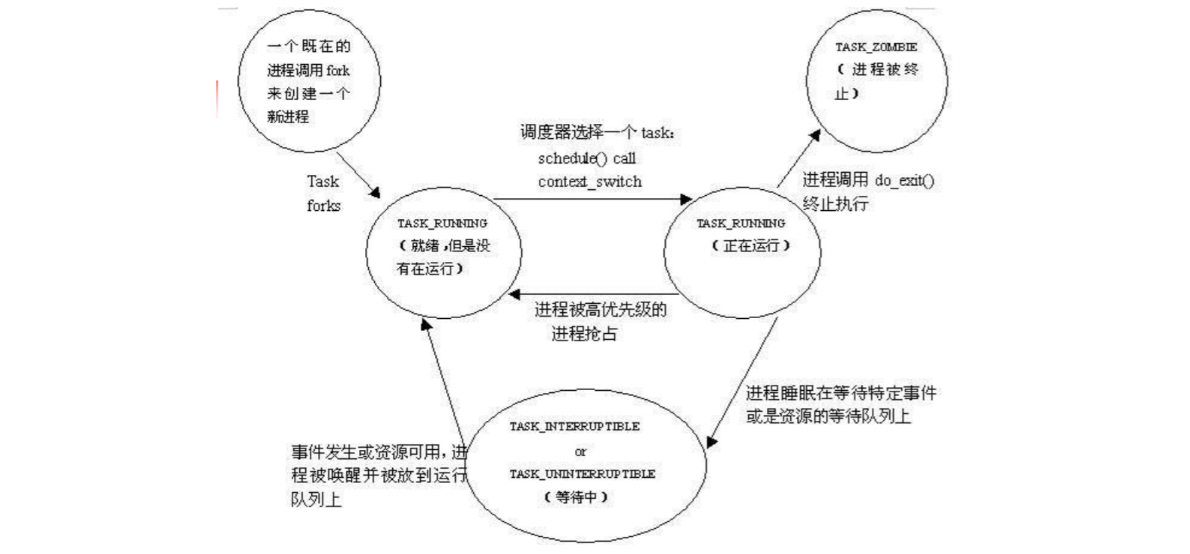
- state,进程状态,注意到TASK_RUNNING可作为就绪态和运行态,以进程是否取得CPU来作为区别。调用do_exit后,进程成为僵尸进程,Linux会适时处理它,并收回进程描述符,此时进程才真正消失
- thread,保存进程上下文中CPU相关的⼀些状态,如 sp,ip
- mm,指向与进程地址空间相关的信息
进程是如何被创建的?
必然有一个进程在最开始被创建出来,这就是
对于一般进程(通过fork系统调用创建的进程),_do_fork()调用copy_process(),复制父进程的描述符task_struct、信息检查、初始化、把进程状态设置为TASK_RUNNING(此时子进程置为就绪态),然后采用写时复制技术逐⼀复制所有其他进程资源。子进程的内核栈和pid是不能简单采取复制的,内核会为子进程初始化内核栈,以便为子进程的运行准备好上下文环境。子进程被初始化后加入就绪队列,获取到CPU后会从ret_from_fork返回用户态运行
进程的调度
从prev进程切换到next进程,为了能使前者下次切换时能继续从原来的位置运行,需要对CPU做一个快照,这就是保存进程上下文,可以说进程切换就是进程的上下文切换。在实际代码中,每个进程切换基本由两个步骤组成。
- 切换页全局目录(CR3)以安装⼀个新的地址空间,这样不同进程的虚拟地址如0x8048400(32位x86)就会经过不同的页表转换为不同的物理地址。
- 切换内核态堆栈和进程的CPU上下文,因为进程的CPU上下文提供了内核执行新进程所需要的所有信息,包含所有CPU寄存器状态。
我认为,进程的调度是基于上述的中断机制实现的,要谈进程切换就不能离开中断。这里引用孟宁老师在ppt里给出的中断和进程切换的典型场景

Linux内核将进程分为了两类,对不同的进程,有不同的调度策略:
- 实时进程:优先级1-99。一般使用SCHED_FIFO和SCHED_RR调度策略,前者会持续占用CPU,直到一个更高优先级的进程打断;后者对同一优先级的进程,采用时间片轮转的方式使其能轮流使用CPU
- 普通进程:优先级大于100。使用SCHED_NORMAL策略,Linux2.6以后SCHED_NORMAL用的是CFS算法,能基于系统负载、优先级和执行时间等动态分配CPU时间,对交互式程序支持较好
3.文件系统
和进程一样,文件首先需要能被系统进行描述。在Linux中,inode被实现作为文件描述符,能够记录文件权限、所有者、长度等信息。文件目录就是inode的有序集合。
文件被持久化存储在磁盘上,并在打开后读入内存,内核和进程该如何记录打开的文件?这需要内核和进程分别维护以下两个数据结构
- 系统打开文件表:包含每个已打开文件的FCB的副本,以及其他信息(例如打开该文件的进程数)。是由file对象组成的链表,全局唯一
- 进程打开文件表:包含一个指向系统打开文件表相应项的指针,以及其他信息,由进程描述符里的file_struct描述。
为了能支持多种不同的文件系统,Linux实现了虚拟文件系统VFS,能为各种文件系统提供通用的、统一的接口。

VFS为此实现了一个通用的文件模型,这个模型包括:
- 超级块,代表一个文件系统
- inode,存放一个文件的通用信息
- 目录项,实现按名存取的关键,存放目录与文件对应的连接关系
- file,代表被进程打开的文件,存放与进程的交互信息
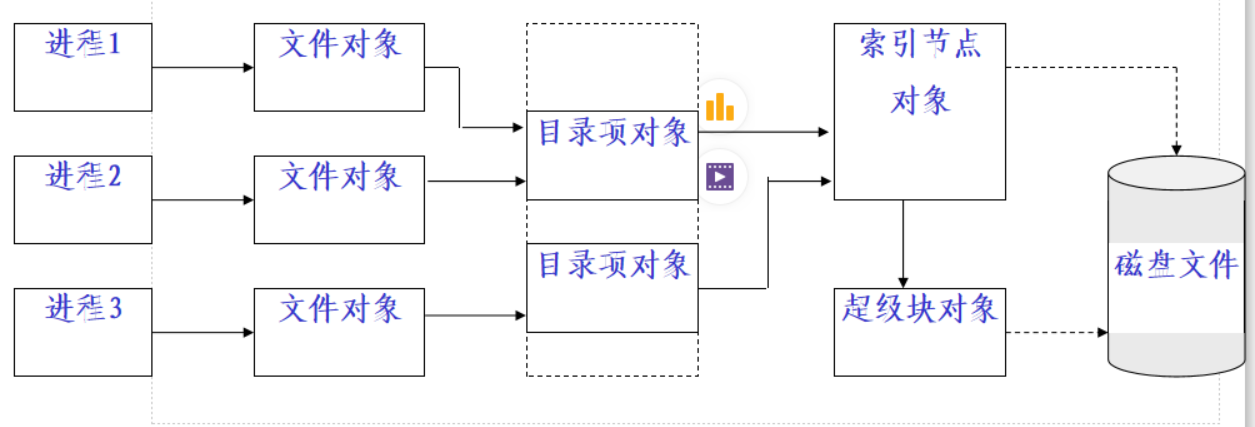
下图显示了一个进程与文件的交互的例子。三个不同进程打开同一个文件,其中两个进程使用同一个硬链接。每个进程都有自己的文件对象,每个硬链接对应一个目录项对象。三个文件对象只需要两个目录项对象,这两个目录项对象对应同一个索引节点对象,这个索引节点对象标识的是超级块对象以及普通磁盘文件。
各种不同的文件系统通过mount(挂载、安装)到根文件系统的目录树中,这样的目录称为挂载点。在Linux中,每个文件系统都有自己的根目录,如果一个文件系统的根目录是系统目录树的根目录,那个这个文件系统就是根文件系统,通常是ext2文件系统
二、课程总结和改进意见
感谢孟老师和李老师的教学,让人能从总体上提纲挈领,把握住学习Linux系统的重点,然后在深入展开,理解背后的工作机制和原理。Linux毫无疑问是软件工程和设计上一个极为成功的例子,内部及其精妙。对于课程的改进,我希望能加入更多的实验(最好是像现在这样能方便的统一实验环境),希望课程后续能再讲一下Linux一些常见命令的使用、shell脚本编写等知识