Ehcache:

ehcache的配置文件ehcache.xml
1 <?xml version="1.0" encoding="UTF-8"?> 2 <ehcache> 3 4 <diskStore path="java.io.tmpdir"/> 5 6 <defaultCache 7 maxElementsInMemory="10000" 8 eternal="false" 9 timeToIdleSeconds="120" 10 timeToLiveSeconds="120" 11 overflowToDisk="true" 12 /> 13 14 <cache 15 name="mycache" 16 maxElementsInMemory="10000" 17 eternal="false" 18 timeToIdleSeconds="30" 19 timeToLiveSeconds="30" 20 overflowToDisk="true" 21 /> 22 23 </ehcache>
ehcache的使用:
cache文件:
1 public interface Cache { 2 3 public void set(String key,Object value); 4 public Object get(String key); 5 public void remove(String key); 6 }
cacheWithEhcache.java
1 import net.sf.ehcache.CacheManager; 2 import net.sf.ehcache.Ehcache; 3 import net.sf.ehcache.Element; 4 5 public class CacheWithEhCache implements Cache{ 6 7 private static CacheManager cacheManager = new CacheManager(); 8 private static final String CACHE_NAME = "mycache";//mycache是xml配置文件里配的缓存的名字 9 10 private Ehcache getCache() { 11 return cacheManager.getEhcache(CACHE_NAME); 12 } 13 14 @Override 15 public void set(String key, Object value) { 16 Element element = new Element(key, value); 17 getCache().put(element); 18 } 19 20 @Override 21 public Object get(String key) { 22 Element element = getCache().get(key); 23 if(element == null) { 24 return null; 25 } else { 26 return element.getObjectValue(); 27 } 28 } 29 30 @Override 31 public void remove(String key) { 32 getCache().remove(key); 33 } 34 35 }
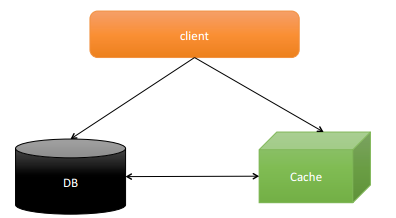
分布式缓存Memcached:
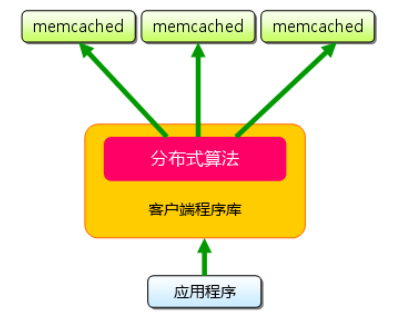
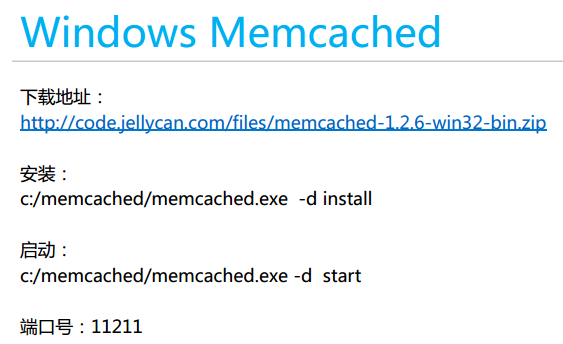
mecacheed的客户端:

cacheWithMemcached.java
1 import java.io.IOException; 2 3 import net.spy.memcached.AddrUtil; 4 import net.spy.memcached.MemcachedClient; 5 6 public class CacheWithMemCached implements Cache { 7 8 private static MemcachedClient client = buildClient(); 9 10 private static MemcachedClient buildClient() { 11 try { 12 return new MemcachedClient(AddrUtil.getAddresses("127.0.0.1:11211")); 13 } catch (IOException e) { 14 e.printStackTrace(); 15 return null; 16 } 17 } 18 19 @Override 20 public void set(String key, Object value) { 21 client.set(key, 30, value); 22 } 23 24 25 @Override 26 public Object get(String key) { 27 return client.get(key); 28 } 29 30 @Override 31 public void remove(String key) { 32 client.delete(key); 33 } 34 35 }
分布式的体现:

redis缓存服务:
redis是一个高性能的key-value存储系统,能够作为缓存框架和队列但是由于它是一个内存缓存系统。这些数据还是要存储到数据库中的。
和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
作为缓存框架:
create/updae/delete---同时存到redis和数据库
query--先从redis查,没有记录才从数据库查,并把从数据库查的结果也放一份到redis
作为缓存队列:
1、把对象Object存储到redis中,怎么存?和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作。
memcache存取对象是序列化和反序列化,使用通用的序列化、反序列化(频繁的会很消耗cpu,使用Google Protocol Buffer,将对象打成二进制流)或者使用json存储(阿里巴巴的fast-json)
2、java使用redis的客户端一般是:jedis jedis的原生接口只支持基本数据类型和String、byte[]
3、我对redis队列的理解:
重要的数据:先存到数据库,然后存到redis
要求响应速度很高的的数据:先写缓存,然后通过消息队列再写入数据库
4、redis是否支持集群?
支持
redis主从复制配置和使用都非常简单。通过主从复制可以允许多个slave server拥有和master server相同的数据库副本。下面是关于redis主从复制的一些特点
1.master可以有多个slave
2.除了多个slave连到相同的master外,slave也可以连接其他slave形成图状结构
3.主从复制不会阻塞master。也就是说当一个或多个slave与master进行初次同步数据时,master可以继续处理client发来的请求。相反slave在初次同步数据时则会阻塞不能处理client的请求。
4.主从复制可以用来提高系统的可伸缩性,我们可以用多个slave 专门用于client的读请求,比如sort操作可以使用slave来处理。也可以用来做简单的数据冗余
5.可以在master禁用数据持久化,只需要注释掉master 配置文件中的所有save配置,然后只在slave上配置数据持久化。
下面介绍下主从复制的过程
当设置好slave服务器后,slave会建立和master的连接,然后发送sync命令。无论是第一次同步建立的连接还是连接断开后的重新连 接,master都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存起来。后台进程完成写文件 后,master就发送文件给slave,slave将文件保存到磁盘上,然后加载到内存恢复数据库快照到slave上。接着master就会把缓存的命 令转发给slave。而且后续master收到的写命令都会通过开始建立的连接发送给slave。从master到slave的同步数据的命令和从 client发送的命令使用相同的协议格式。当master和slave的连接断开时slave可以自动重新建立连接。如果master同时收到多个 slave发来的同步连接命令,只会使用启动一个进程来写数据库镜像,然后发送给所有slave。
Redis的主从复制功能非常强大,一个master可以拥有多个slave,而一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构