总是觉得HTTP的学习不过就是几页的学习内容罢了,于是就总是没有好好的去学。
我发现我们更愿意通过实例来了解一个东西,不过这里还是添加一下概括的过程吧~
一个不想看就跳过的概括:输入一个 URL,发生了什么?
- 1.浏览器通过 DNS 解析 获得 服务 IP 发现目标!
- 2.客户端通过 TCP 协议 建立 服务器的 TCP 连接。 向城池扔吊绳!
- 3.客户端(浏览器)向 Web服务器(HTTP服务器) 发送 HTTP 协议包。 冲上城池。
- 4.服务器向客户端 发送 HTTP 协议应答包。 被敌军发现了(废话,这么大阵势( ̄□ ̄;)
- 5.客户端和服务器断开,客户端 开始解析 处理 HTML文档。 (被打回来了,不过抢来了一些战果 消化一下!)
纸上谈兵终觉浅,开战!
下面是我的一个HTTP真实的请求过程。
步骤一. 假设用chrome去请求博客园这个网站。
- 这个时候Chrome会搜索自身的DNS缓存 + 搜索操作系统自身的DNS缓存(前面那个 Chrome缓存挂了,就用 操作系统的)
注意: Chrome自身缓存时间仅为 1分钟(ヾ(๑╹◡╹)ノ"切,真短)。更多 相关缓存时间 参考:http://blog.csdn.net/charleslei/article/details/51083229
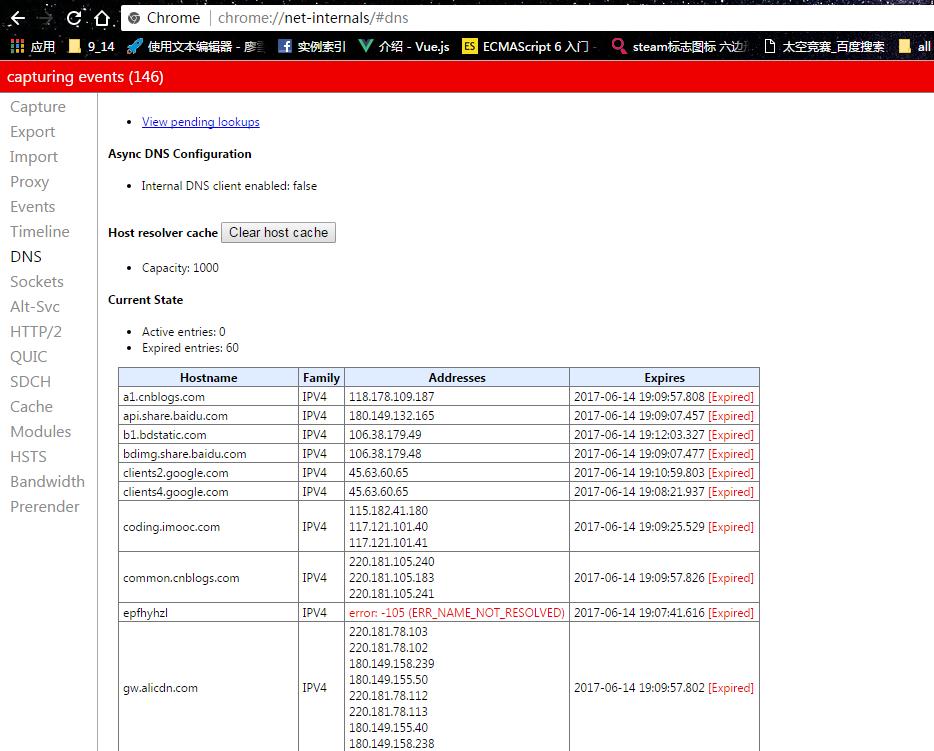
然后接下来这个我再次访问博客园10s之后

因为之前那个挂了, 所以这里其实是 又请求了 一次!
> 我们的网址其实都只是一个身份证的名字,而那些IPv4地址则是身份证号。
- 如果还是没有找到,它会读取系统本地的host文件。 (Chrome、OS,你们都是吃干饭的吗,找个人都找不到)
- 如果还是没有找到,浏览器发起一个DNS的一个系统调用。 (Chrome、OS、Host,你们!)
- 宽带运营商服务器查看本身缓存。
- 运营商服务器发起一个迭代DNS解析的请求。 -- 具体过程其实就像政府由上到下的工作。
比如我们要查厦门市在哪里,我们从世界的角度上看,我们先找到 中国->福建->厦门。 这就是所谓的迭代DNS解析。
完成上述步骤之后,运营商服务器把结果返回给操作系统内核同时缓存起来。
--> 操作系统内核把结果返回给浏览器
-->最终浏览器拿到了博客园的网址 www.cnblogs.com
是不是很有秩序呢??
总结: 浏览器缓存 -> 系统缓存 -> 路由器缓存 -> ISP DNS缓存(这里一般都会有)
步骤二. 浏览器获得域名对应的IP地址后,发起HTTP的三次握手(兔崽子,让我好找)
业内俗称:HTTP是基于TCP。TCP三次握手建立连接。四次挥手关闭连接。
- 三次握手
- 客户端发送 SYN(建立联机) 标志的报文 给 服务端。
- 服务端收到信息,回传 ACK(acknowledgement确认) 标志的报文, 表示确认。
- 最后客户端 回传 ACK 标志报文,表示握手结束。
- 四次挥手
- 客户端 -> FIN/ACK报文(结束确认) -> 服务器 (我要关闭连接了)。
- 服务器 -> ACK报文 : 我知道了,但我还没准备好 (你说分手就分手)
- 服务器确认没有数据传输了 -> FIN/ACK(结束确认) -> 客户端。 (好了,那分手吧)
- 客户端 -> ACK -> 服务器。 (挥手再见)
步骤三之前1. 网站服务的永久重定向响应
为什么不直接 发给用户 想看的内容? 其中一个原因是跟搜索引擎排名有关。如果一个页面两个地址如 baidu.com 和 www.baidu.com,搜索引擎会认为它们 是两个网站。结果造成搜索链 都减少 从而降低排名。搜索引擎 会把 带 www的 和 不带 www 的地址归到 同一个网站排名下面。
步骤三之前2. 浏览器跟踪重定向地址
浏览器知道了 要访问的正确地址。它会发送一个 获取请求。
请求头一般包括:
- Accept
- Accept-language
- Accept-Encoding
- Connection
- User-Agent
- Cookit
- Host
步骤三 .TCP/IP连接建立起来以后,浏览器就可以向服务器发送HTTP请求了,比如使用 GET ,POST方法,这些前端应该都写过吧。
步骤四. 服务器经过一系列处理将结果数据返回给浏览器,如我访问博客园这个例子,服务器就会把博客园的HTML页面代码发给我。
步骤五. 浏览器拿到博客园的代码,进行,相应的资源加载和渲染,里面的js,css,图片等静态资源都是一个个HTTP请求,都得经过上述的过程。
关于HTTP的状态吗和它的几种请求方法
| 方法 | 一些普世的作用 |
|---|---|
| GET | 获取 |
| POST | 提交,常用于登录注册 |
| PUT | 比如说更新头像 |
| DELETE | 删除 |
| HEAD | 跟GET很像,不过服务器不传回全部内容 |
| TRACE | 回显服务器收到的请求,主要用于测试或者诊断 |
| 状态码 | 代表的意义 |
|---|---|
| 1XX | 请求接受,正在处理 |
| 2XX | 成功接受、处理掉了 |
| 3XX | 重定向,需要附加操作才能完成请求 |
| 4XX | 客户端错误,请求有语法错误或者请求无法实现 |
| 5XX | 服务端错误,服务器未能实现合法的请求 |
常见的几个具体的状态码
| 状态码 | 代表的意义 |
|---|---|
| 200 | OK,best |
| 400 | 客户端请求语法有误 |
| 403 | 服务器收到了请求但拒绝了,可能是没有权限 |
| 404 | 请求资源不存在,可能是你的地址写错了 |
| 500 | 服务端出错 |
| 502 | 连接超时,服务器链接太多,服务器炸了!!! |
| 503 | 当前服务器没法完成任务,也许过段时间就可以了 |