Gradient boosting decision tree(使用的基分类器是CART回归树,不适用CART分类树)
还有一遍博客讲的很好:https://www.cnblogs.com/pinard/p/6140514.html
介绍:
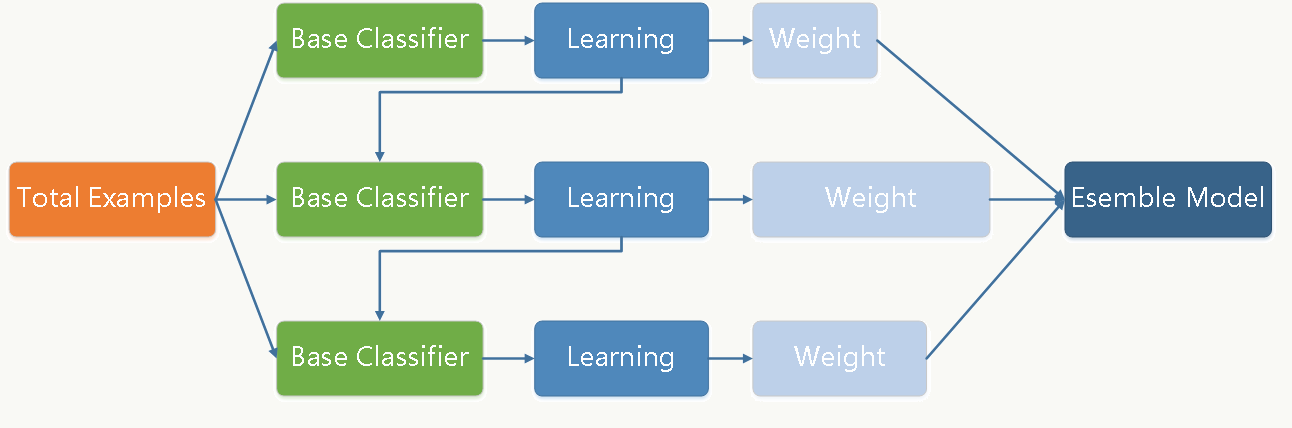
首先gbdt 是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
GBDT训练过程
gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
模型最终可以描述为:

模型一共训练M轮,每轮产生一个弱分类器 T(x;θm)T(x;θm)。弱分类器的损失函数:
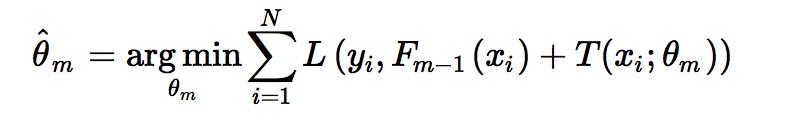
Fm-1(x)为当前模型,gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
- 但是其实我们真正关注的,1.是希望损失函数能够不断的减小,2.是希望损失函数能够尽可能快的减小。所以如何尽可能快的减小呢?
- 让损失函数沿着梯度方向的下降。这个就是gbdt 的 gb的核心了。 利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。
- 这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解
gbdt如何选择特征
gbdt选择特征的细节其实是想问你CART Tree生成的过程。这里有一个前提,gbdt的弱分类器默认选择的是CART TREE。其实也可以选择其他弱分类器的,选择的前提是低方差和高偏差。框架服从boosting 框架即可。
下面我们具体来说CART TREE(是一种二叉树) 如何生成。CART TREE 生成的过程其实就是一个选择特征的过程。假设我们目前总共有 M 个特征。第一步我们需要从中选择出一个特征 j,做为二叉树的第一个节点。然后对特征 j 的值选择一个切分点 m. 一个 样本的特征j的值 如果小于m,则分为一类,如果大于m,则分为另外一类。如此便构建了CART 树的一个节点。其他节点的生成过程和这个是一样的。现在的问题是在每轮迭代的时候,如何选择这个特征 j,以及如何选择特征 j 的切分点 m:
- 原始的gbdt的做法非常的暴力,首先遍历每个特征,然后对每个特征遍历它所有可能的切分点,找到最优特征 m 的最优切分点 j。
gbdt如何构建特征
其实说gbdt 能够构建特征并非很准确,gbdt 本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。在CTR预估中,工业界一般会采用逻辑回归去进行处理,在我的上一篇博文当中已经说过,逻辑回归本身是适合处理线性可分的数据,如果我们想让逻辑回归处理非线性的数据,其中一种方式便是组合不同特征,增强逻辑回归对非线性分布的拟合能力。
长久以来,我们都是通过人工的先验知识或者实验来获得有效的组合特征,但是很多时候,使用人工经验知识来组合特征过于耗费人力,造成了机器学习当中一个很奇特的现象:有多少人工就有多少智能。关键是这样通过人工去组合特征并不一定能够提升模型的效果。所以我们的从业者或者学界一直都有一个趋势便是通过算法自动,高效的寻找到有效的特征组合。Facebook 在2014年 发表的一篇论文便是这种尝试下的产物,利用gbdt去产生有效的特征组合,以便用于逻辑回归的训练,提升模型最终的效果。
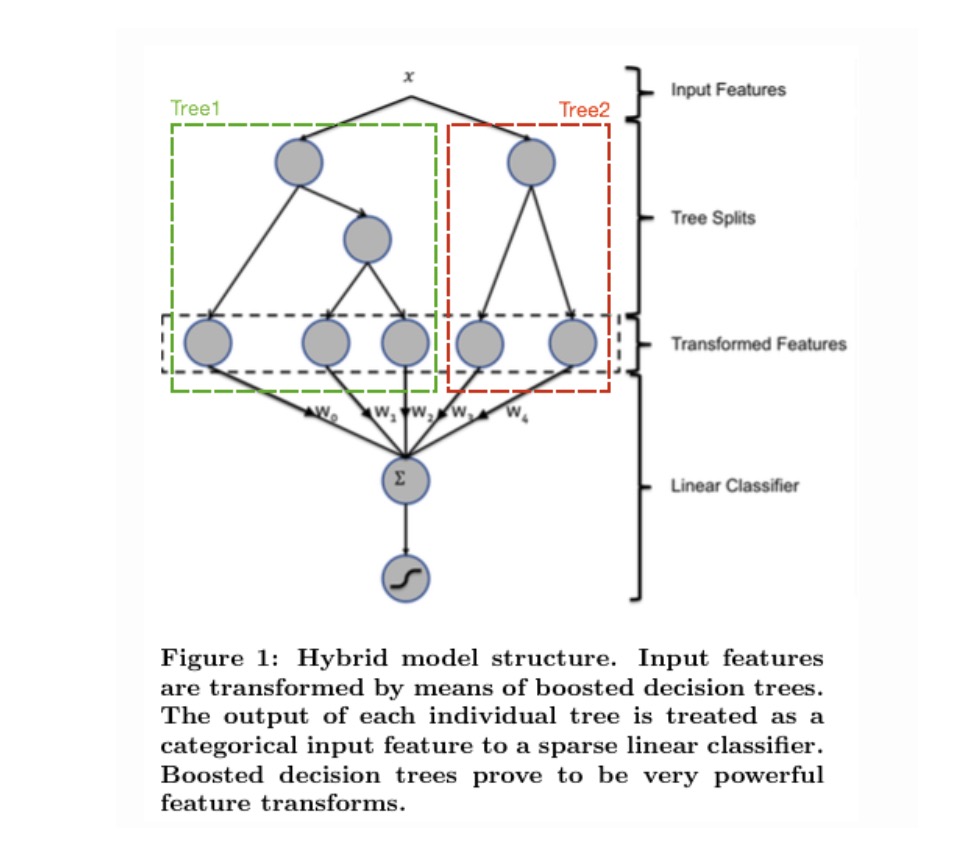
GBDT构建特征
如图所示,我们 使用 GBDT 生成了两棵树,两颗树一共有五个叶子节点。我们将样本 X 输入到两颗树当中去,样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为 0.
于是对于该样本,我们可以得到一个向量[0,1,0,1,0] 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。
gbdt如何进行分类
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。
如果选用的弱分类器是分类树,类别相减是没有意义的。上一轮输出的是样本 x 属于 A类,本一轮训练输出的是样本 x 属于 B类。 A 和 B 很多时候甚至都没有比较的意义,A 类- B类是没有意义的。
我们具体到分类这个任务上面来,我们假设样本 X 总共有 K类。来了一个样本 x,我们需要使用gbdt来判断 x 属于样本的哪一类。

第一步 我们在训练的时候,是针对样本 X 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类,也就是 K = 3。样本 x 属于 第二类。那么针对该样本 x 的分类结果,其实我们可以用一个 三维向量 [0,1,0] 来表示。0表示样本不属于该类,1表示样本属于该类。由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。
针对样本有 三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入为(x,0)。第二颗树输入针对 样本x 的第二类,输入为(x,1)。第三颗树针对样本x 的第三类,输入为(x,0)
在这里每颗树的训练过程其实就是就是我们之前已经提到过的CATR TREE 的生成过程。在此处我们参照之前的生成树的程序 即可以就解出三颗树,以及三颗树对x 类别的预测值f1(x),f2(x),f3(x)。那么在此类训练中,我们仿照多分类的逻辑回归 ,使用softmax 来产生概率,则属于类别 1 的概率
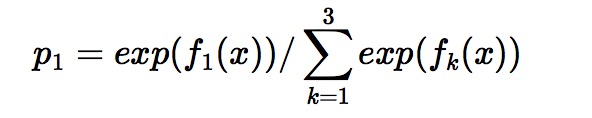
并且我们我们可以针对类别1 求出 残差y11(x)=p1(x);类别2 求出残差y22(x)=1-p2(x);类别3 求出残差y33=p3(x).
然后开始第二轮训练 针对第一类 输入为(x,y11(x)), 针对第二类输入为(x,y22(x)), 针对 第三类输入为 (x,y33(x)).继续训练出三颗树。一直迭代M轮。每轮构建 3颗树。
所以当K =3。我们其实应该有三个式子
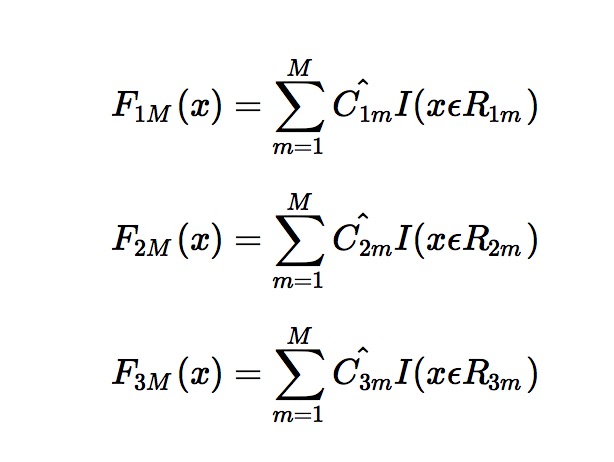
当训练完毕以后,新来一个样本 x1 ,我们需要预测该样本的类别的时候,便可以有这三个式子产生三个值,f1(x),f2(x),f3(x)。样本属于 某个类别c的概率为
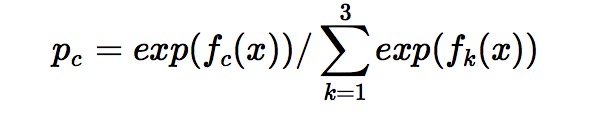
gbdt分类示例:
Boosting,迭代,即通过迭代多棵树来共同决策。这怎么实现呢?难道是每棵树独立训练一遍,比如A这个人,第一棵树认为是10岁,第二棵树认为是0岁,第三棵树认为是20岁,我们就取平均值10岁做最终结论?--当然不是!且不说这是投票方法并不是GBDT,只要训练集不变,独立训练三次的三棵树必定完全相同,这样做完全没有意义。之前说过,GBDT是把所有树的结论累加起来做最终结论的,所以可以想到每棵树的结论并不是年龄本身,而是年龄的一个累加量。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义,简单吧。
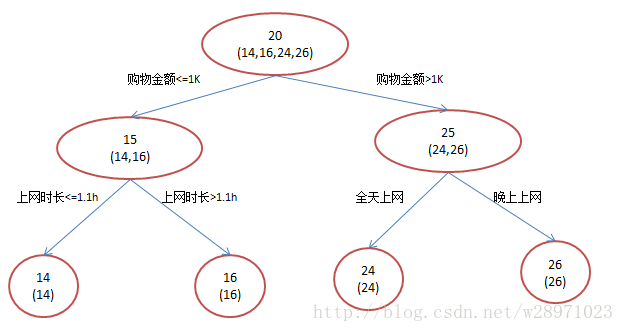
还是年龄预测,简单起见训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图1所示结果:
现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图2所示结果:
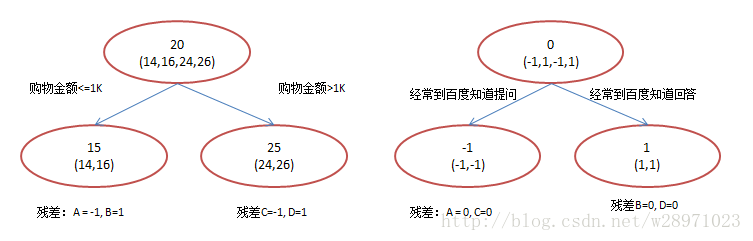
在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是我可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
换句话说,现在A,B,C,D的预测值都和真实年龄一致了。Perfect!:
A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26
那么哪里体现了Gradient呢?其实回到第一棵树结束时想一想,无论此时的cost function是什么,是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。
讲到这里我们已经把GBDT最核心的概念、运算过程讲完了!没错就是这么简单。不过讲到这里很容易发现三个问题:
为什么使用GBDT:
1)既然图1和图2 最终效果相同,为何还需要GBDT呢?
答案是过拟合。过拟合是指为了让训练集精度更高,学到了很多”仅在训练集上成立的规律“,导致换一个数据集当前规律就不适用了。其实只要允许一棵树的叶子节点足够多,训练集总是能训练到100%准确率的(大不了最后一个叶子上只有一个instance)。在训练精度和实际精度(或测试精度)之间,后者才是我们想要真正得到的。
我们发现图1为了达到100%精度使用了3个feature(上网时长、时段、网购金额),其中分枝“上网时长>1.1h” 很显然已经过拟合了,这个数据集上A,B也许恰好A每天上网1.09h, B上网1.05小时,但用上网时间是不是>1.1小时来判断所有人的年龄很显然是有悖常识的;
相对来说图2的boosting虽然用了两棵树 ,但其实只用了2个feature就搞定了,后一个feature是问答比例,显然图2的依据更靠谱。(当然,这里是LZ故意做的数据,所以才能靠谱得如此狗血。实际中靠谱不靠谱总是相对的) Boosting的最大好处在于,每一步的残差计算其实变相地增大了分错instance的权重,而已经分对的instance则都趋向于0。这样后面的树就能越来越专注那些前面被分错的instance。就像我们做互联网,总是先解决60%用户的需求凑合着,再解决35%用户的需求,最后才关注那5%人的需求,这样就能逐渐把产品做好,因为不同类型用户需求可能完全不同,需要分别独立分析。如果反过来做,或者刚上来就一定要做到尽善尽美,往往最终会竹篮打水一场空。
2)Gradient呢?不是“G”BDT么?
到目前为止,我们的确没有用到求导的Gradient。在当前版本GBDT描述中,的确没有用到Gradient,该版本用残差作为全局最优的绝对方向,并不需要Gradient求解.
3)这不是boosting吧?Adaboost可不是这么定义的。
这是boosting,但不是Adaboost。GBDT不是Adaboost Decistion Tree。就像提到决策树大家会想起C4.5,提到boost多数人也会想到Adaboost。Adaboost是另一种boost方法,它按分类对错,分配不同的weight,计算cost function时使用这些weight,从而让“错分的样本权重越来越大,使它们更被重视”。Bootstrap也有类似思想,它在每一步迭代时不改变模型本身,也不计算残差,而是从N个instance训练集中按一定概率重新抽取N个instance出来(单个instance可以被重复sample),对着这N个新的instance再训练一轮。由于数据集变了迭代模型训练结果也不一样,而一个instance被前面分错的越厉害,它的概率就被设的越高,这样就能同样达到逐步关注被分错的instance,逐步完善的效果。Adaboost的方法被实践证明是一种很好的防止过拟合的方法,但至于为什么则至今没从理论上被证明。GBDT也可以在使用残差的同时引入Bootstrap re-sampling,GBDT多数实现版本中也增加的这个选项,但是否一定使用则有不同看法。re-sampling一个缺点是它的随机性,即同样的数据集合训练两遍结果是不一样的,也就是模型不可稳定复现,这对评估是很大挑战,比如很难说一个模型变好是因为你选用了更好的feature,还是由于这次sample的随机因素。