本章主要介绍服务降级的原因、服务降级的开关、自动降级、读服务降级、写服务降级、服务容错策略、Hystrix降级与熔断、服务优先级设计等。
一、服务降级、熔断、调度
1、服务降级概述
分布式微服务架构流量都非常庞大,业务高峰时,为了保证服务的高可用,往往需要服务或者页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。这种技术在分布式微服务架构中称为服务降级。
例如在线购物系统,整个购买流程是重点业务,比如支付功能,在流量高峰时,为了保证购买流程的正常运行,往往会关闭一些不太重要的业务,比如广告业务等。
2、服务降级方式
服务降级体现在各个方面,从客户端(Web应用或者App应用)到后端服务整个链路的各环节都有降级的策略,这里挑选工作中常用的降级方式为大家讲述。
2.1服务降级开关
工作中常用的降级方式是使用降级开关,降级开关属于人工降级,我们可以设置一个分布式降级开关,用于实现服务的降级,然后集中式管理开关配置信息即可,具体方案如图11-1所示。
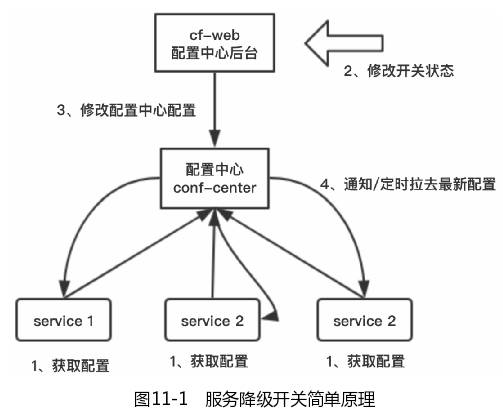
服务降级开关的步骤如下:
(1)服务启动时,从配置中心拉取配置,之后定时从配置中心拉取配置信息。
(2)流量高峰,为保证重要业务的高可用(SLA),开发人员通过配置中心后台修改非核心业务功能开关。
(3)在配置中心修改配置。
(4)在配置中心通知服务或者服务定时拉取最新配置,修改内存配置信息,配置开关生效,非核心业务功能暂时关闭。
2.2 自动降级
人工降级需要人为干预,但是系统服务24小时在线运行,人的精力毕竟有限。因此,系统服务需要支持自动化降级。自动化降级往往根据系统负载、资源使用情况、QPS、平均响应时间、SLA等指标进行降级。下面简单列举几种。
1. 超时降级
访问的资源响应时间慢,超过定义的最大响应时间,且该服务不是系统的核心服务的时候,可以在超时后自动降级。
2. 失败次数降级
当系统服务失败次数达到一定阈值时自动降级,可以使用异步线程探测服务是否恢复,恢复即取消降级。
3. 故障降级
系统服务出现网络故障、DNS故障、HTTP服务返回错误的状态码、RPC服务抛出异常等,可以直接降级。降级后的处理方案有:返回默认值、兜底数据(提前准备好静态页面或者数据)、缓存数据等。
4. 限流降级
系统服务因为访问量太大而导致系统崩溃,可以使用限流来限制访问量,当达到限流阈值时,后续请求会被降级。降级后的处理方案有:使用排队页面(导流到排队页面等一会重试)、错误页等。
2.3 读服务降级
对于非核心业务,服务读接口有问题的时候,可以暂时切换到缓存、走静态化、读取默认值,甚至直接返回友好的错误页面。对于前端页面,可以将动态化的页面静态化,减少对核心资源的占用,提升性能。反之,如果静态化页面出现问题,那么可以降级为动态化来保证服务正确运行。
对于整个系统的链路,在各个环节都有相应的读服务降级策略,具体业务具体分析即可。
2.4 写服务降级
对于写操作非常频繁的系统服务,比如淘宝“双十一”时,用户下单、加入购物车、结算等操作都涉及大量的写服务。可采取的策略有:
(1)同步写操作转异步写操作。
(2)先缓存,异步写数据到DB中。
(3)先缓存,在流量低峰,定时写数据到DB中。
例如购物“秒杀系统”,先扣减Redis库存,正常同步扣减DB库存,在流量高峰DB性能扛不住的时候,可以降级为发送一条扣减DB库存的信息,异步进行DB库存扣减,实现最终一致即可。如果DB还有压力,还可以直接扣减缓存,在流量低峰,定时写数据到DB中。
3、服务容错策略
分布式服务架构中,随着业务复杂度的增加,依赖的服务也逐步增加,集群中的服务调用失败后,服务框架需要能够在底层自动容错。引发服务调用失败的原因有很多:
(1)服务与依赖的服务之间链路有问题,例如网络中断。
(2)依赖服务超时。例如,依赖服务业务处理速度慢、依赖服务长时间的Full GC等。
(3)系统遭受恶意爬虫袭击。
设计服务容错的基本原则是“Design for Failure”。在设计上需要考虑到各种边界场景和对于服务间调用出现的异常或延迟情况,同时在设计和编程时要考虑周到。这一切都是为了达到以下目标:
(1)依赖服务的故障不会严重破坏用户的体验。
(2)系统能自动或半自动处理故障,具备自我恢复能力。
服务容错策略有很多,不同的业务场景有不同的容错策略。下面简单介绍几种工作中常用的容错策略。
3.1 失败转移(Failover)
当服务出现失败时,服务框架重试其他服务,通常用于幂等性(Idempotence)服务,例如读操作。缺点是失败重试会带来更长延迟,需要框架对失败重试的最大次数做限制。
3.2 失败自动恢复(Failback)
服务消费者调用服务提供者失败时,通过对失败错误码等异常信息进行判断决定后续的执行策略。对于Failback模式,如果服务提供者调用失败,就不会重试其他服务,而是服务消费者捕获异常后进行后续的处理。
3.3 快速失败(Failfast)
服务调用失败后,服务框架不会发起重试机制,而是忽略失败,记录日志。快速失败是一种比较简单的策略,常用于一些非核心服务。
3.4 失败缓存(FailCache)
服务调用失败后,服务框架可将消息临时缓存,等待周期T后重新发送,直到服务提供者能够正常处理消息。常用应用场景如记录日志、通知积分增长等。失败缓存策略需要注意的是,缓存时间、缓存对象大小、重试周期T以及重试最大次数等需要做出限制。
4 Hystrix降级、熔断
1 Hystrix简介
在微服务架构中,服务之间相互调用,下游服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种因“服务提供者”不可用导致“服务消费者”不可用,并将不可用逐渐放大的过程。
如图11-2所示,A作为服务提供者,B为A的服务消费者,C是B的服务消费者。A不可用引起了B的不可用,并将不可用像滚雪球一样放大到C,雪崩效应就形成了。
例如,对于一个依赖于30个服务的应用程序,每个服务都有99.99%的正常运行时间,可以计算:99.9930 = 99.7%可用,也就是说一亿个请求的0.03%(3000000)会失败。如果一切正常,那么每个月有2个小时服务是不可用的,现实通常更糟糕。
Hystrix的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,这与Hystrix本身的功能不谋而合,因此Netflix团队将该框架命名为Hystrix,并使用对应的卡通形象作为LOGO,具体如图11-3所示。

Hystrix被设计的目标是:
(1)对通过第三方客户端访问的依赖项(通常通过网络)的延迟和故障进行保护和控制。
(2)在复杂的分布式系统中阻止级联故障。
(3)快速失败,快速恢复。
(4)回退,尽可能优雅地降级。
(5)启用近乎实时监控、警报和操作控制。