环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、Shark
Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,当数据全部load在内存的话,将快10倍以上,因此Shark可以作为交互式查询应用服务来使用。除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上Shark底层依赖于Hive的解析器,查询优化器,但正是由于SHark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,比如不能和Spark的其他组件进行很好的集成,无法满足Spark的一栈式解决大数据处理的需求。
二、SparkSQL
1、SparkSQL介绍
Hive是Shark的前身,Shark是SparkSQL的前身。
(1)SparkSQL产生的根本原因是其完全脱离了Hive的限制。
(2)SparkSQL支持查询原生的RDD,RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础。
(3)能够在Scala中写SQL语句,支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用。
2、Spark on Hive和Hive on Spark
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
3、DataFrame(SparkSQL的最佳搭档)
DataFrame也是一个分布式数据容器。
与RDD类似,然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。
同时与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。
从API易用性的角度上看, DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
DataFrame的底层封装的是RDD,只不过RDD的泛型是Row类型。
4. SparkSQL的数据源
SparkSQL的数据源可以是JSON类型的字符串,也可以是JDBC,Parquent,Hive,HDFS等。

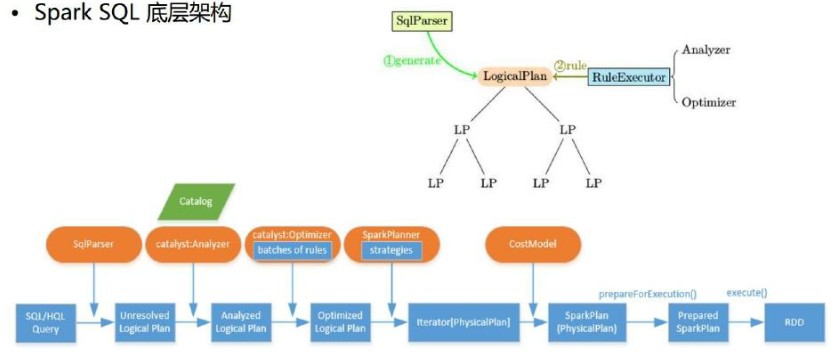
5. SparkSQL底层架构
首先拿到sql后解析一批未被解决的逻辑计划,
-->再经过分析得到分析后的逻辑计划,
-->再经过一批优化规则转换成一批最佳优化的逻辑计划,
-->再经过SparkPlanner的策略转化成一批物理计划,
-->随后经过消费模型转换成一个个的Spark任务执行。
6. 谓词下推(predicate Pushdown)

参考: