目录:
- 高效索引策略
- 维护索引和表
- 索引创建的选择
高效索引策略
1、组合索引:多条件查询时使用组合索引,多每个查询的列增加独立的索引并不能提高查询效率。———————————————————————————————————————————————————————
2、独立的列:查询的列不是独立的,mysql不会使用索引,也就是数据列使用了mysql提供的函数(因为mysql不知道你要对列做什么处理,所以mysql认为使用索引可能会降低效率),当然查询的数据值是可以使用函数的。
如:id varchar;to_number(id)=1,不使用索引;id=to_number('1'),使用索引,但这种情况to_number可以写成id=1,mysql会做转换。———————————————————————————————————————————————————————
3、前缀索引和索引选择性:有时候需要检索很长的字符,这样会让索引变得大且慢。此时我们可以检索开始的部分字符,从而可以提高索引效率、节省索引空间、降低索引的选择性(不重复的索引值与数据表的记录总数的比值)。但MySQL无法使用前缀索引做ORDER BY和GROUP BY,也无法使用前缀索引做覆盖扫描。
不重复的索引值与数据表的记录总数的比值:SELECT COUNT(DISTINCT LEFT(address, 3)) / COUNT(*) FROM address;
比值越接近1,使用前缀索引的效率越好;我们可以这样计算来优化索引。
select count(DISTINCT left(address,3)) / count(*), count(DISTINCT left(address,4)) / count(*), count(DISTINCT left(address,5)) / count(*), count(DISTINCT left(address,6)) / count(*), count(DISTINCT left(address,7)) / count(*), count(DISTINCT left(address,8)) / count(*), count(DISTINCT left(address,9)) / count(*), count(DISTINCT left(address,10)) / count(*) from address;
最后选取一个比值与索引长度适中的作为索引的长度。
———————————————————————————————————————————————————————
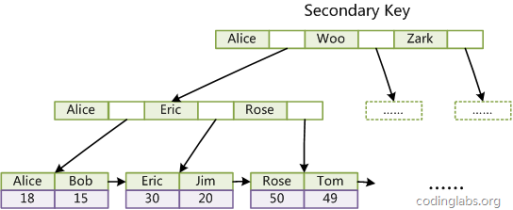
4、覆盖索引:一个索引包含所有需要查询的列,我们将这样的所有称为覆盖索引。
如InnoDB二级索引存储了主键和索引列,我们使用Select id,name from tablename where name=’Rose’;时,那这个索引就是覆盖索引。
———————————————————————————————————————————————————————
5、索引排序:mysql可以使用一个索引既满足排序,又可用于查找。
———————————————————————————————————————————————————————
6、压缩索引:Myisam索引使用前缀压缩来减少索引的大小,从而可以让更多的索引放入内存中,某些情况下可以提高性能。
———————————————————————————————————————————————————————
7、排除冗余和重复索引:MySQL允许在相同列上创建多个索引,无论是有意还是无意的。MySQL需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个进行考虑,这会影响性能。
维护索引和表
检查/修复损坏的表(CHECK TABLE / REPAIR TABLE)
索引创建的选择
- 频繁更新的字段不适合建立索引。
- 参与列计算的列不适合建索引。
- 数据重复且唯一性太差的字段不适合建立索引,例如:性别,真假值。
- 表数据可以确定比较少的不需要建索引。
- where条件中用不到的字段不适合建立索引。