目录:
- 什么是Kafka
- 为什么使用Kafka
- Kafka应用场景
- Kafka特点
- Kafka与RabbitMQ比较
- Kafka安装
什么是Kafka
Kafka是LinkedIn公司开发的一套分布式、多分区、多副本且基于Zookeeper协调的开源流处理平台。
流处理:说道流处理就需要先了解以下流数据。
流数据:流数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下,数据流可被视为一个随时间延续而无限增长的动态数据集合。应用于网络监控、传感器网络、航空航天、气象测控和金融服务等领域。它是指由数千个数据源持续生成的数据,通常也同时以数据记录的形式发送,规模较小(约几千字节)。流数据包括多种数据,例如客户使用您的移动或 Web 应用程序生成的日志文件、网购数据、游戏内玩家活动、社交网站信息、金融交易大厅或地理空间服务,以及来自数据中心内所连接设备或仪器的遥测数据。
综上所述,Kafka非常适用与大数据场景。
为什么使用Kafka
解耦、异步、削峰、冗余、顺序化、扩展性非常灵活。
Kafka应用场景
MQ、网站活动跟踪、日志聚合分析。
Kafka特点
1、基于磁盘存储:Kafka的消息被提交到磁盘,根据设置的规则进行保留数据,且每个主题可以设计单独的保留规则。Kafka充分利用磁盘物理特性,及随机写入慢(磁头冲停),顺序写入快(磁头悬浮),它采用顺序写的方式来存储数据。
2、伸缩性:用户可先使用单个Broker,待数据量增长时可在线对集群进行扩展而不影响系统的可用性(无需重启服务)。
3、高性能:通过横向扩展生产消费者、Broker,充分利用了磁盘的特性。
4、多个生产者:不管客户端使用单个还是多个主题,都支持多个生产者。
5、多个消费者:支持多个消费者从一个单独的消息流读取数据,而且消费者之间互不影响。
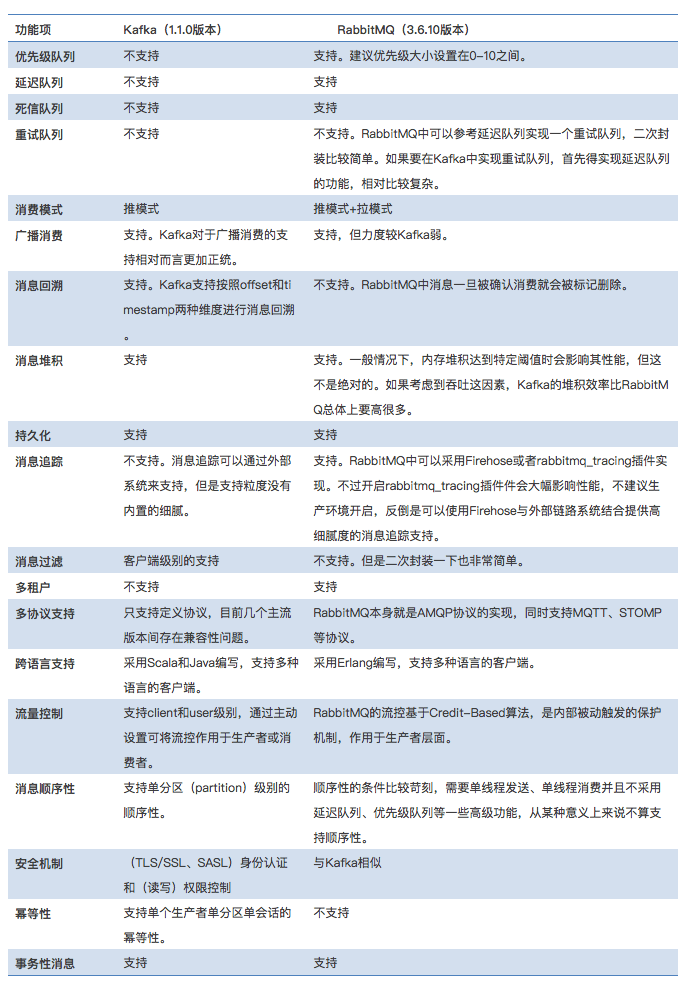
Kafka与RabbitMQ比较