大前提:根据主键查询返回数据
select * from t
innodb的数据是直接保存在主键索引上的,全表扫描实际上是扫描表t的主键索引。这条语句没有其他判断条件,所以查到的每一行可以直接放到结果集返回给客户端,
实际上,服务端并不需要保存一个完整的结果集,取数据和发数据的流程是这样的:
1.获取一行,写到 net_buffer。这块内存大小是参数 net_buffer_length定义的,默认16K
2.重复获取行,知道net_buffer_length写满,调用网络接口发出去
3.如果发送成功,清空net_buffer,然后继续取下一行,并写入net_buffer
4.如果发送函数返回 EAGAIN 或 WSAEWOULDBLOCK就表示本地网络栈(socket send buffer)写满了,进入等待。知道网络栈重新可写,再继续发送
流程图如下
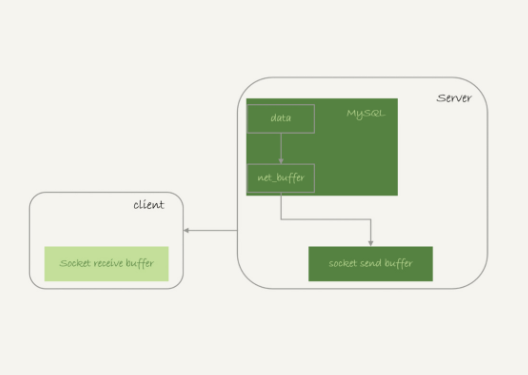
流程中,可以看到:
1.一个查询在发送过程中,占用的MYSQL内部的内存最大就是net_buffer_length,不会达到200G
2.socket send buffer也不可能达到200G(默认定义/proc/sys/net/core/wmem_default),如果socket send buffer被写满,就会暂停读数据的流程
也就是说,mysql是边读边发的,这个概念很重要。这就意味着,如果客户端接收的慢,会导致MYSQL服务端由于结果发布出去,这个事务的执行时间边长。
当show full processlist 时,看到许多线程处于 sending to client 这个状态,就意味着要确认是否要返回那么多的结果,这个查询是否可以优化
如果要快速减少这个状态的线程的话,可以将net_buffer_length参数设置为一个更大的值
与sending to client相似的一个状态是sending data,一个查询语句的状态变化为:
1.mysql查询语句进入执行阶段后,首先把状态设置为sending data
2.然后发送执行结果的列相关的信息meta data给客户端
3.再继续执行语句的流程
4.执行完成后,把状态设置为空字符串
查询内存命中率,buffer pool中的: show engine innodb status 可以看到“Buffer pool hit rate”字样,显示的就是当前的命中率
innodb_buffer_pool_size 小于磁盘数据量是很常见的,如果一个buffer pool 满了,而又要从磁盘读入一个数据页,那肯定要淘汰一个旧的数据页的
LRU算法:为全表扫描的操作量身定制

在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域。图中 LRU_old 指向的就是 old 区域的第一个位置,是整个链表的 5/8 处。也就是说,靠近链表头部的 5/8 是 young 区域,靠近链表尾部的 3/8 是 old 区域。改进后的 LRU 算法执行流程变成了下面这样。 中状态
1,要访问数据页 P3,由于 P3 在 young 区域,因此和优化前的 LRU 算法一样,将其移到链表头部,变成状态
2。之后要访问一个新的不存在于当前链表的数据页,这时候依然是淘汰掉数据页 Pm,但是新插入的数据页 Px,是放在 LRU_old 处。
3.处于 old 区域的数据页,每次被访问的时候都要做下面这个判断:
若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部;
如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。