这次探索一下http 请求
request
这节我们讲request,在nginx中我们指的是http请求,详细到nginx中的数据结构是ngx_http_request_t。
ngx_http_request_t是对一个http请求的封装。 我们知道,一个http请求。包括请求行、请求头、请求体、响应行、响应头、响应体。
http请求是典型的请求-响应类型的的网络协议,而http是文件协议。所以我们在分析请求行与请求头,以及输出响应行与响应头。往往是一行一行的进行处理。
假设我们自己来写一个httpserver,通常在一个连接建立好后,client会发送请求过来。然后我们读取一行数据,分析出请求行中包括的method、uri、http_version信息。然后再一行一行处理请求头,并依据请求method与请求头的信息来决定是否有请求体以及请求体的长度。然后再去读取请求体。
得到请求后。我们处理请求产生须要输出的数据,然后再生成响应行,响应头以及响应体。在将响应发送给client之后。一个完整的请求就处理完了。当然这是最简单的webserver的处理方式。事实上nginx也是这样做的,仅仅是有一些小小的差别,比方。当请求头读取完毕后。就開始进行请求的处理了。nginx通过ngx_http_request_t来保存解析请求与输出响应相关的数据。
那接下来,简要讲讲nginx是怎样处理一个完整的请求的。
对于nginx来说,一个请求是从ngx_http_init_request開始的,在这个函数中。会设置读事件为ngx_http_process_request_line,也就是说。接下来的网络事件。会由ngx_http_process_request_line来运行。
从ngx_http_process_request_line的函数名。我们能够看到。这就是来处理请求行的,正好与之前讲的,处理请求的第一件事就是处理请求行是一致的。
通过ngx_http_read_request_header来读取请求数据。然后调用ngx_http_parse_request_line函数来解析请求行。
nginx为提高效率,採用状态机来解析请求行,并且在进行method的比較时,没有直接使用字符串比較,而是将四个字符转换成一个整型,然后一次比較以降低cpu的指令数。这个前面有说过。
非常多人可能非常清楚一个请求行包括请求的方法,uri,版本号。却不知道事实上在请求行中。也是能够包括有host的。比方一个请求GET http://www.taobao.com/uri HTTP/1.0这样一个请求行也是合法的,并且host是www.taobao.com,这个时候,nginx会忽略请求头中的host域,而以请求行中的这个为准来查找虚拟主机。
另外。对于对于http0.9版来说,是不支持请求头的,所以这里也是要特别的处理。所以。在后面解析请求头时。协议版本号都是1.0或1.1。整个请求行解析到的參数,会保存到ngx_http_request_t结构其中。
在解析完请求行后。nginx会设置读事件的handler为ngx_http_process_request_headers,然后兴许的请求就在ngx_http_process_request_headers中进行读取与解析。
ngx_http_process_request_headers函数用来读取请求头,跟请求行一样,还是调用ngx_http_read_request_header来读取请求头,调用ngx_http_parse_header_line来解析一行请求头。解析到的请求头会保存到ngx_http_request_t的域headers_in中,headers_in是一个链表结构。保存全部的请求头。
而HTTP中有些请求是须要特别处理的。这些请求头与请求处理函数存放在一个映射表里面,即ngx_http_headers_in,在初始化时,会生成一个hash表,当每解析到一个请求头后,就会先在这个hash表中查找,假设有找到,则调用对应的处理函数来处理这个请求头。
比方:Host头的处理函数是ngx_http_process_host。
当nginx解析到两个回车换行符时,就表示请求头的结束。此时就会调用ngx_http_process_request来处理请求了。
ngx_http_process_request会设置当前的连接的读写事件处理函数为ngx_http_request_handler,然后再调用ngx_http_handler来真正開始处理一个完整的http请求。
这里可能比較奇怪,读写事件处理函数都是ngx_http_request_handler,事实上在这个函数中。会依据当前事件是读事件还是写事件。分别调用ngx_http_request_t中的read_event_handler或者是write_event_handler。因为此时。我们的请求头已经读取完毕了,之前有说过,nginx的做法是先不读取请求body,所以这里面我们设置read_event_handler为ngx_http_block_reading。即不读取数据了。
刚才说到,真正開始处理数据,是在ngx_http_handler这个函数里面,这个函数会设置write_event_handler为ngx_http_core_run_phases,并运行ngx_http_core_run_phases函数。
ngx_http_core_run_phases这个函数将运行多阶段请求处理,nginx将一个http请求的处理分为多个阶段,那么这个函数就是运行这些阶段来产生数据。由于ngx_http_core_run_phases最后会产生数据。所以我们就非常easy理解,为什么设置写事件的处理函数为ngx_http_core_run_phases了。
在这里,我简要说明了一下函数的调用逻辑。我们须要明确终于是调用ngx_http_core_run_phases来处理请求,产生的响应头会放在ngx_http_request_t的headers_out中,这一部分内容,我会放在请求处理流程里面去讲。nginx的各种阶段会对请求进行处理。最后会调用filter来过滤数据。对数据进行加工,如truncked传输、gzip压缩等。
这里的filter包含header filter与body filter。即对响应头或响应体进行处理。filter是一个链表结构,分别有header filter与body filter,先运行header filter中的全部filter,然后再运行body filter中的全部filter。在header filter中的最后一个filter,即ngx_http_header_filter。这个filter将会遍历全部的响应头,最后须要输出的响应头在一个连续的内存。然后调用ngx_http_write_filter进行输出。
ngx_http_write_filter是body filter中的最后一个。所以nginx首先的body信息,在经过一系列的body filter之后,最后也会调用ngx_http_write_filter来进行输出(有图来说明)。
这里要注意的是,nginx会将整个请求头都放在一个buffer里面,这个buffer的大小通过配置项client_header_buffer_size来设置,假设用户的请求头太大,这个buffer装不下。那nginx就会又一次分配一个新的更大的buffer来装请求头,这个大buffer能够通过large_client_header_buffers来设置,这个large_buffer这一组buffer。比方配置4 8k,就是表示有四个8k大小的buffer能够用。注意。为了保存请求行或请求头的完整性,一个完整的请求行或请求头,须要放在一个连续的内存里面,所以。一个完整的请求行或请求头。仅仅会保存在一个buffer里面。
这样,假设请求行大于一个buffer的大小。就会返回414错误。假设一个请求头大小大于一个buffer大小。就会返回400错误。
在了解了这些參数的值。以及nginx实际的做法之后。在应用场景,我们就须要依据实际的需求来调整这些參数,来优化我们的程序了。
处理流程图:
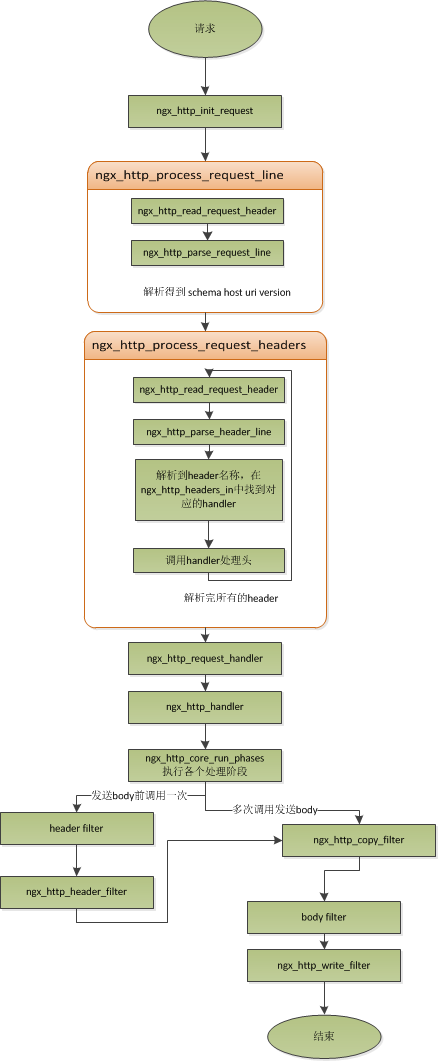
以上这些。就是nginx中一个http请求的生命周期了。我们再看看与请求相关的一些概念吧。
keepalive
当然,在nginx中,对于http1.0与http1.1也是支持长连接的。
什么是长连接呢?我们知道。http请求是基于TCP协议之上的,那么。当client在发起请求前,须要先与服务端建立TCP连接。而每一次的TCP连接是须要三次握手来确定的。假设client与服务端之间网络差一点。这三次交互消费的时间会比較多。并且三次交互也会带来网络流量。当然。当连接断开后。也会有四次的交互,当然对用户体验来说就不重要了。
而http请求是请求应答式的。假设我们能知道每一个请求头与响应体的长度。那么我们是可以在一个连接上面运行多个请求的,这就是所谓的长连接,但前提条件是我们先得确定请求头与响应体的长度。对于请求来说。假设当前请求须要有body。如POST请求。那么nginx就须要client在请求头中指定content-length来表明body的大小。否则返回400错误。
也就是说,请求体的长度是确定的。那么响应体的长度呢?先来看看http协议中关于响应body长度的确定:
- 对于http1.0协议来说,假设响应头中有content-length头,则以content-length的长度就能够知道body的长度了,client在接收body时,就能够依照这个长度来接收数据。接收完后,就表示这个请求完毕了。而假设没有content-length头,则client会一直接收数据,直到服务端主动断开连接。才表示body接收完了。
- 而对于http1.1协议来说,如果响应头中的Transfer-encoding为chunked传输。则表示body是流式输出,body会被分成多个块,(类似于对于流式传输解决粘包问题的做法)每块的開始会标识出当前块的长度。此时,body不须要通过长度来指定。假设是非chunked传输,并且有content-length。则依照content-length来接收数据。
否则,假设是非chunked,并且没有content-length。则client接收数据。直到服务端主动断开连接。
从上面。我们能够看到。除了http1.0不带content-length以及http1.1非chunked不带content-length外,body的长度是可知的。
此时,当服务端在输出完body之后。会能够考虑使用长连接。是否能使用长连接,也是有条件限制的。假设client的请求头中的connection为close,则表示client须要关掉长连接。假设为keep-alive。则client须要打开长连接。
假设client的请求中没有connection这个头,那么依据协议,假设是http1.0。则默觉得close。假设是http1.1,则默觉得keep-alive。
假设结果为keepalive,那么,nginx在输出完响应体后。会设置当前连接的keepalive属性,然后等待client下一次请求。当然,nginx不可能一直等待下去。假设client一直不发数据过来,岂不是一直占用这个连接?所以当nginx设置了keepalive等待下一次的请求时,同一时候也会设置一个最大等待时间,这个时间是通过选项keepalive_timeout来配置的,假设配置为0,则表示关掉keepalive,此时,http版本号不管是1.1还是1.0。client的connection不管是close还是keepalive。都会强制为close。
假设服务端最后的决定是keepalive打开,那么在响应的http头里面,也会包括有connection头域。其值是”Keep-Alive”,否则就是”Close”。假设connection值为close,那么在nginx响应完数据后,会主动关掉连接。所以。对于请求量比較大的nginx来说,关掉keepalive最后会产生比較多的time-wait状态的socket。
一般来说,当client的一次訪问。须要多次訪问同一个server时,打开keepalive的优势非常大。比方图片服务器。通常一个网页会包括非常多个图片。打开keepalive也会大量降低time-wait的数量。
(服务端timee-wait数量过多会影响服务端性能。由于很多套接字不能马上被使用要设置地址复用)
pipe
在http1.1中,引入了一种新的特性。即pipeline。
那么什么是pipeline呢?pipeline事实上就是流水线作业,它能够看作为keepalive的一种升华,由于pipeline也是基于长连接的,目的就是利用一个连接做多次请求。假设client要提交多个请求。对于keepalive来说。那么第二个请求,必需要等到第一个请求的响应接收全然后,才干发起,这和TCP的停止等待协议是一样的。得到两个响应的时间至少为2*RTT。
而对pipeline来说。client不必等到第一个请求处理完后,就能够立即发起第二个请求。得到两个响应的时间可能能够达到1*RTT。nginx是直接支持pipeline的。(client的请求是并行的提高用户体验)可是,nginx对pipeline中的多个请求的处理却不是并行的。依旧是一个请求接一个请求的处理,仅仅是在处理第一个请求的时候,client就能够发起第二个请求。这样。nginx利用pipeline降低了处理完一个请求后。等待第二个请求的请求头数据的时间。
事实上nginx的做法非常easy。前面说到,nginx在读取数据时,会将读取的数据放到一个buffer里面,所以。假设nginx在处理完前一个请求后,假设发现buffer里面还有数据,就觉得剩下的数据是下一个请求的開始,然后就接下来处理下一个请求。否则就设置keepalive。
lingering_close
lingering_close。字面意思就是延迟关闭,也就是说,当nginx要关闭连接时。并不是马上关闭连接,而是先关闭tcp连接的写。再等待一段时间后再关掉连接的读。
为什么要这样呢?我们先来看看这样一个场景。
nginx在接收client的请求时,可能因为client或服务端出错了,要马上响应错误信息给client,而nginx在响应错误信息后,大分部情况下是须要关闭当前连接。nginx运行完write()系统调用把错误信息发送给client。write()系统调用返回成功并不表示数据已经发送到client,有可能还在tcp连接的write buffer里(内核缓冲区中)。接着假设直接运行close()系统调用关闭tcp连接。内核会首先检查tcp的read buffer里有没有client发送过来的数据留在内核态没有被用户态进程读取。假设有则发送给clientRST报文来关闭tcp连接丢弃write buffer里的数据,假设没有则等待write buffer里的数据发送完成,然后再经过正常的4次分手报文断开连接。
所以,当在某些场景下出现tcp write buffer里的数据在write()系统调用之后到close()系统调用运行之前没有发送完成,且tcp read buffer里面还有数据没有读。close()系统调用会导致client收到RST报文且不会拿到服务端发送过来的错误信息数据(由于错误信息在内核缓冲区中并没有发送完,或者由于发送了RST包导致client忽略了)。
那client肯定会想,这server好霸道,动不动就reset我的连接。连个错误信息都没有。
在上面这个场景中,我们能够看到,关键点是服务端给client发送了RST包。导致自己发送的数据在client忽略掉了。所以,解决这个问题的重点是,让服务端别发RST包。
再想想,我们发送RST是由于我们关掉了连接。关掉连接是由于我们不想再处理此连接了,也不会有不论什么数据产生了。对于全双工的TCP连接来说,我们仅仅须要关掉写即可了。读能够继续进行。我们仅仅须要丢掉读到的不论什么数据即可了,这种话,当我们关掉连接后,client再发过来的数据,就不会再收到RST了。
当然终于我们还是须要关掉这个读端的。所以我们会设置一个超时时间,在这个时间过后,就关掉读,client再发送数据来就无论了。作为服务端我会觉得。都这么长时间了。发给你的错误信息也应该读到了。再慢就不关我事了。要怪就怪你RP不好了。当然,正常的client,在读取到数据后。会关掉连接,此时服务端就会在超时时间内关掉读端。
这些正是lingering_close所做的事情。
协议栈提供 SO_LINGER 这个选项,它的一种配置情况就是来处理lingering_close的情况的,只是nginx是自己实现的lingering_close。lingering_close存在的意义就是来读取剩下的client发来的数据,所以nginx会有一个读超时时间,通过lingering_timeout选项来设置。假设在lingering_timeout时间内还没有收到数据,则直接关掉连接。nginx还支持设置一个总的读取时间,通过lingering_time来设置,这个时间也就是nginx在关闭写之后,保留socket的时间。client须要在这个时间内发送全然部的数据。否则nginx在这个时间过后,会直接关掉连接。当然,nginx是支持配置是否打开lingering_close选项的,通过lingering_close选项来配置。 那么。我们在实际应用中。是否应该打开lingering_close呢?
这个就没有固定的推荐值了,如Maxim Dounin所说。lingering_close的主要作用是保持更好的client兼容性,可是却须要消耗很多其它的额外资源(比方连接会一直占着)。
这节,我们介绍了nginx中。连接与请求的基本概念,下节。我们讲主要的数据结构。