【场景】
生产环境没有对外放开端口,所以在本机Windows、Macos环境下下载的客户端没办法使用,只能在Linux下查看当前的redis使用情况。此时我们可以用redis提供的客户端redis-cli进行操作: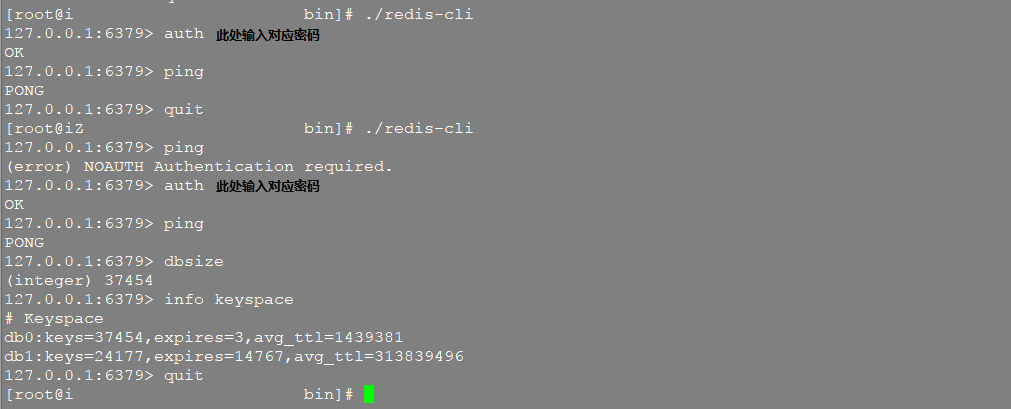
此时我们可以用dbsize查看redis中有多少个key,用info keyspace查看各库的使用情况,用info memory查看内存的状况。同时也可以用keys和scan来查看key的情况。keys只能在我们很清楚查找的内容很少时使用,如果keys *查出来有几千万条数据,对于客户端来说我们很难一次性处理这么多信息;对于服务器来说,这种规模的查找会因为O(n)的复杂度造成服务器卡顿。因为Redis是单线程程序,顺序执行所有指令,所以其它客户端的指令就只能等待。
【scan指令的使用】
提供了limit参数,我们可以控制返回数据的规模,要注意的是,返回的结果可能会有重复,需要客户端去重。
首先插入100条数据,如图:
而后我们用scan这个指令去查找: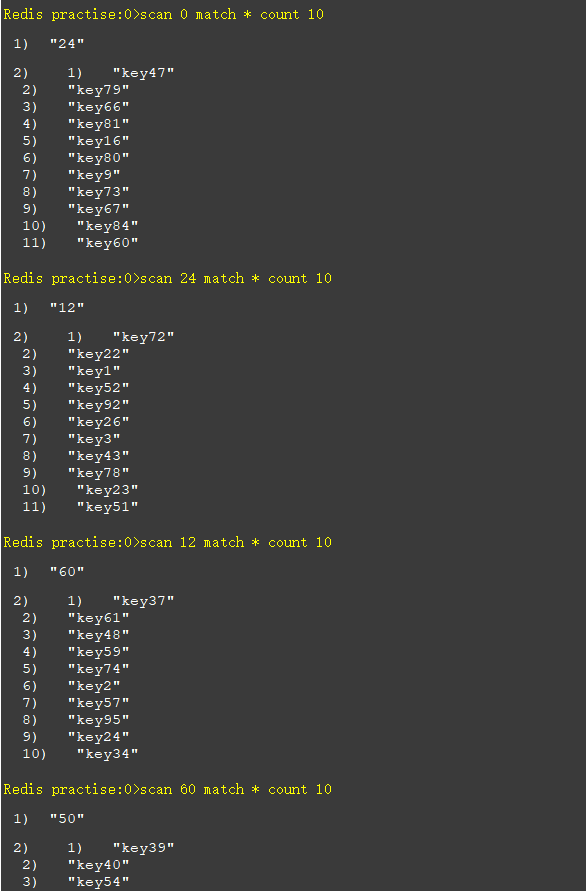
当这个指令返回的数字标号为0时,说明已经遍历完成。注意如果返回的是empty list or set时,只要标号不为0,那么遍历就还没有结束。
【一个规律】
为了后面描述字典的结构和scan遍历跳转的原则便于理解,这里讲一个规律。
任何自然数与2^n进行求余(模)运算,最终的结果其实跟这个数字和(2^n - 1)进行位'&'运算的结果是相同的。这是因为,对2^n求余或者说mod运算的本质,是找到这个数字在除开2^n整数倍之后,还能剩下的数字是几,那么对于2^n - 1来说,刚好就是比2^n小,且二进制全为1,这个全为1的二进制数,和这个自然数进行'&'运算可以真实的复刻出自然数中比2^n小的位还剩多少(对于大于2^n的高位来说,其实都是2^n的整数倍,在和全1的低位进行与的过程中,这一部分数据都会归0),两者本质相同。如下图描述了14005对8进行求余运算,结果其实和14005与7的'&'运算结果一致: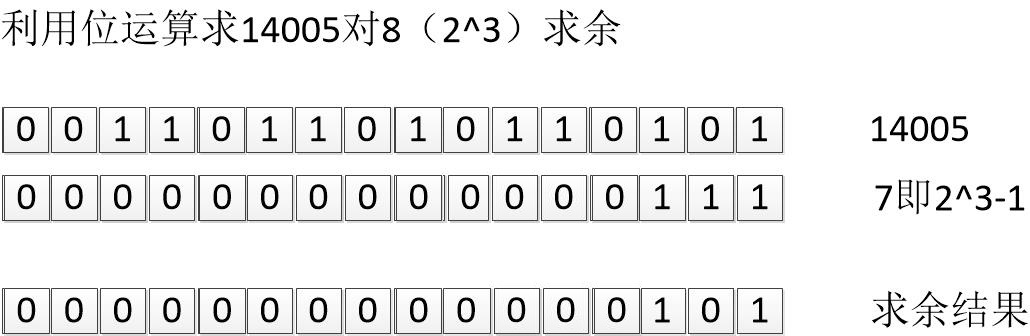
【扩容与缩容】
首先,当我们有一个长度为8的数组,我们需要把一大堆元素存储在这个长度为8的数组上,怎么办呢?最简单的办法就是求余,因为任何一个数字,对8进行求余的结果,必定为0-7的任何一个数,这个时候我们可以根据这个余数安排这些元素放在数组上的位置。如果两个元素对8求与的结果是相同的,比如11和19,对8求余的结果都为3(二进制为011),那么我们可以把11和19都放在3这个元素的位置上,这种现象我们可以叫做元素的碰撞。这两个元素在3这个位置将会由一个链表进行维护。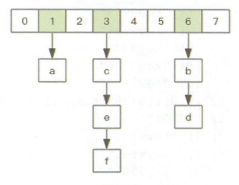
此时,如果这个长度为8的数组进行了扩容,长度增加一倍,变为16,再用对16求余的办法对现有的元素重新进行位置摆放,这个过程我们叫做rehash,那么11和19的位置又在哪里呢?对16求余我们发现,他们的余数为11和3,注意换算为二进制就是1011和0011,那么在新的数组结构中,11和19就会被安放在11和3这两个位置上。
而缩容的过程,与上述相反,也就是之前在1011和0011这两个位置上的元素又会合并到0011这个位置上。
【scan的遍历策略以及原因】
scan遍历正是利用了上述的规律和hash的规律,找到了一种独特的遍历路径,使得scan在遍历过程中,无论是发生扩容还是缩容,都尽量避免了历史链表元素的重复遍历和完全避免了遗漏。
这种策略不同于我们一般对数组进行从0到length-1的遍历,也不同于从length-1到0的遍历,而是采用二进制高位反向进位加法,计算下一次遍历的槽点。如图: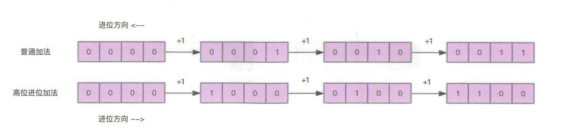
而理解了上述的两个规律,我们会发现,这种高位进位法就能够保证在扩容或者缩容时达到完全避漏尽量不重的效果: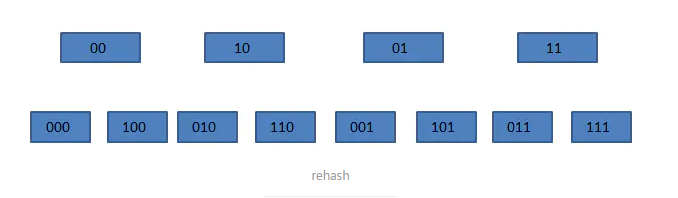
如图,假如scan完成了原数组10位的所有元素遍历,此时发生了数组的扩容,形成了下方的数组结构,那么按照scan的遍历策略,他就会去遍历原数组01位置,即现数组001位置,也就是说,它遍历的下一个槽点没有因为数组的扩容而发生变化。
这里需要说明的是,redis是单线程的,扩容和缩容是发生在本次scan结束之后,所以对于扩容来说,遍历历史的所有数据结果不会因为这个扩容而发生改变。
对于缩容来说,如果此时遍历完了010的所有元素,此刻发生了缩容,那么原本即将遍历的110的槽点变成了新数组的10位置(去掉高位),就会重复遍历原010位置的元素,所以说会造成一定的重复。所以对于缩容来说,是会有少量的重复元素,但量占整体元素的比例应该是很低的。
【渐进式rehash】
Java的 HashMap在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面。如果HashMap中元素特别多,线程就会出现卡顿现象。Redis为了解决这个问题,采用“渐进式rehash”。
它会同时保留旧数组和新数组,然后在定时任务中以及后续对 hash 的指令操作中渐渐地将旧数组中挂接的元素迁移到新数组上。这意味着要操作处于rehash中的字典,需要同时访问新旧两个数组结构。如果在旧数组下面找不到元素,还需要去新数组下面寻找。
scan也需要考虑这个问题,对于rehash中的字典,它需要同时扫描新旧槽位,然后将结果融合后返回给客户端。
【系列指令】
scan指令是一系列指令,除了可以遍历所有的key之外,还可以对指定的容器集合进行遍历。比如zscan遍历zset集合元素,hscan遍历 hash字典的元素,sscan遍历set集合的元素。
【避免大key】
出现大key,会造成内存分配与回收时服务的卡顿,对集群迁移也会造成卡顿,所以在平时的业务开发中,要尽量避免大key的产生。
如果你观察到Redis 的内存大起大落,这极有可能是因为大key导致的,这时候你就需要定位出具体是哪个key,进一步定位出具体的业务来源,然后再改进相关业务代码设计。
对于大key的量化定义:
·一个STRING类型的Key,它的值为5MB(数据过大)
·一个LIST类型的Key,它的列表数量为20000个(列表数量过多)
.一个ZSET类型的Key,它的成员数量为10000个(成员数量过多)
·一个HASH格式的Key,它的成员数量虽然只有1000个但这些成员的value总大小为100MB(成员体积过大)
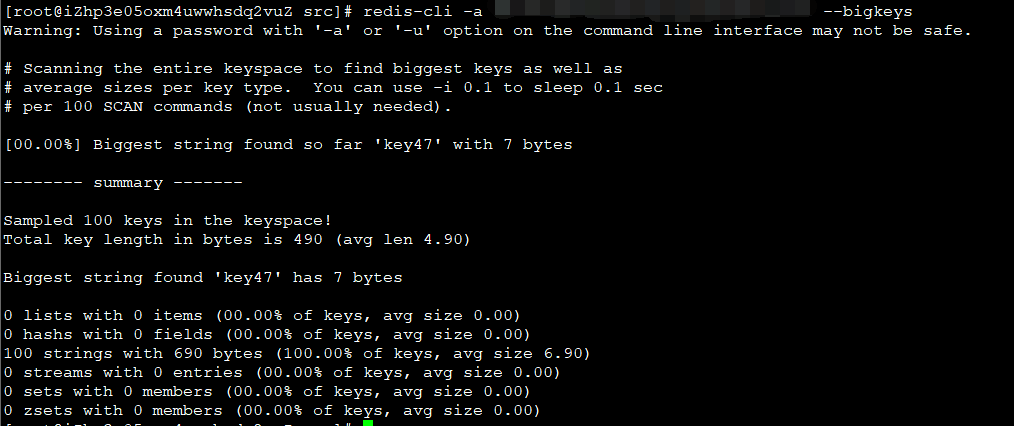
如图,可以使用指令进行大key的查询: